 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
May 21, 2026Public transit route planning traditionally depends on structured map infrastructure and complex routing engines, and no existing dataset supports training models to bypass this dependency. We present TransitLM, a large-scale dataset of over 13 million transit route planning records from four Chinese cities covering 120,845 stations and 13,666 lines, released as a continual pre-training corpus and benchmark data for three evaluation tasks with complementary metrics. Experiments show that an LLM trained on TransitLM produces structurally valid routes at high accuracy and implicitly grounds arbitrary GPS coordinates to appropriate stations without any explicit mapping. These results demonstrate that transit route planning can be learned entirely from data, enabling end-to-end, map-free route generation directly from origin-destination information. The dataset and benchmark are available at https://huggingface.co/datasets/GD-ML/TransitLM, with evaluation code at https://github.com/HotTricker/TransitLM.
EDU-Net: Retinal Pathological Fluid Segmentation in OCT Images with Multiscale Feature Fusion and Boundary Optimization
Apr 22, 2026Objective: Diabetic macular edema (DME) is the leading cause of severe visual impairment in patients with diabetes. Quantification of retinal fluid, particularly intraretinal fluid (IRF) and subretinal fluid (SRF), plays a critical role in the management of DME. Although optical coherence tomography (OCT) can be used for detection, the variable morphology of fluid accumulation and the blurred boundaries caused by noise interference still limit the accuracy of OCT's automatic segmentation. Methods: Retrospective model development and validation study. This study proposes a novel edge-guided dual-branch encoder-decoder network (EDU-Net) to achieve accurate and efficient automatic segmentation of OCT liquid lesions. The local feature extraction branch is based on the EfficientNet model, which precisely captures tiny lesions by leveraging its lightweight separable convolution and high-resolution feature preservation strategy. The global feature extraction branch is based on the large-kernel efficient convolution (LKEC) module and the downsampling layer design to enhance long-range dependencies and global semantics. EDU-Net applies a multi-category edge-guided attention module to fuse high-frequency boundary detail information to each resolution feature to optimize the boundary segmentation performance. Results: Extensive results on the in-house and public datasets demonstrate that EDU-Net achieves state-of-the-art DSC segmentation performance in terms of efficiency and robustness, especially in the segmentation of IRF lesions. Conclusions: EDU-Net integrates local details with global context and optimizes boundaries, achieving an improvement in the accuracy of automatic segmentation of retinal fluid.
SCASRec: A Self-Correcting and Auto-Stopping Model for Generative Route List Recommendation
Feb 03, 2026Route recommendation systems commonly adopt a multi-stage pipeline involving fine-ranking and re-ranking to produce high-quality ordered recommendations. However, this paradigm faces three critical limitations. First, there is a misalignment between offline training objectives and online metrics. Offline gains do not necessarily translate to online improvements. Actual performance must be validated through A/B testing, which may potentially compromise the user experience. Second, redundancy elimination relies on rigid, handcrafted rules that lack adaptability to the high variance in user intent and the unstructured complexity of real-world scenarios. Third, the strict separation between fine-ranking and re-ranking stages leads to sub-optimal performance. Since each module is optimized in isolation, the fine-ranking stage remains oblivious to the list-level objectives (e.g., diversity) targeted by the re-ranker, thereby preventing the system from achieving a jointly optimized global optimum. To overcome these intertwined challenges, we propose \textbf{SCASRec} (\textbf{S}elf-\textbf{C}orrecting and \textbf{A}uto-\textbf{S}topping \textbf{Rec}ommendation), a unified generative framework that integrates ranking and redundancy elimination into a single end-to-end process. SCASRec introduces a stepwise corrective reward (SCR) to guide list-wise refinement by focusing on hard samples, and employs a learnable End-of-Recommendation (EOR) token to terminate generation adaptively when no further improvement is expected. Experiments on two large-scale, open-sourced route recommendation datasets demonstrate that SCASRec establishes an SOTA in offline and online settings. SCASRec has been fully deployed in a real-world navigation app, demonstrating its effectiveness.
Comprehensive Comparison Network: a framework for locality-aware, routes-comparable and interpretable route recommendation
Aug 12, 2025Route recommendation (RR) is a core task of route planning in the Amap app, with the goal of recommending the optimal route among candidate routes to users. Unlike traditional recommendation methods, insights into the local quality of routes and comparisons between candidate routes are crucial for enhancing recommendation performance but often overlooked in previous studies. To achieve these, we propose a novel model called Comprehensive Comparison Network (CCN). CCN not only uses query-level features (e.g. user features) and item-level features (e.g. route features, item embedding) that are common in traditional recommendations, but also introduces comparison-level features which describe the non-overlapping segments between different routes to capture the local quality of routes. The key component Comprehensive Comparison Block (CCB) in CCN is designed to enable comparisons between routes. CCB includes a Comprehensive Comparison Operator (CCO) and a multi-scenario MLP, which can update the representations of candidate routes based on a comprehensive comparison. By stacking multiple CCBs, CCN can determine the final scores of candidate routes and recommend the optimal one to the user. Additionally, since routes directly affect the costs and risks experienced by users, the RR model must be interpretable for online deployment. Therefore, we designed an interpretable pair scoring network to achieve interpretability. Both offline and online experiments demonstrate that CCN significantly improves RR performance and exhibits strong interpretability. CCN has been fully deployed in the Amap app for over a year, providing stable and optimal benefits for route recommendations.
DDO-IN: Dual Domains Optimization for Implicit Neural Network to Eliminate Motion Artifact in Magnetic Resonance Imaging
Mar 11, 2025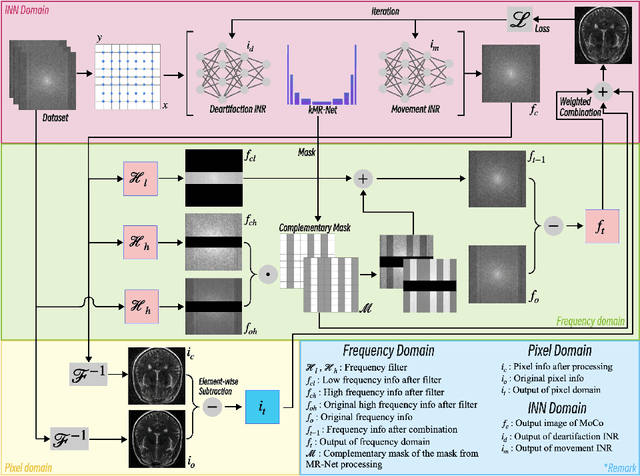
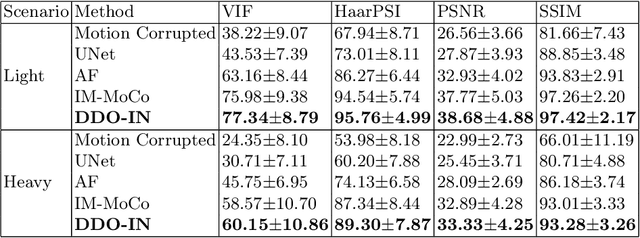
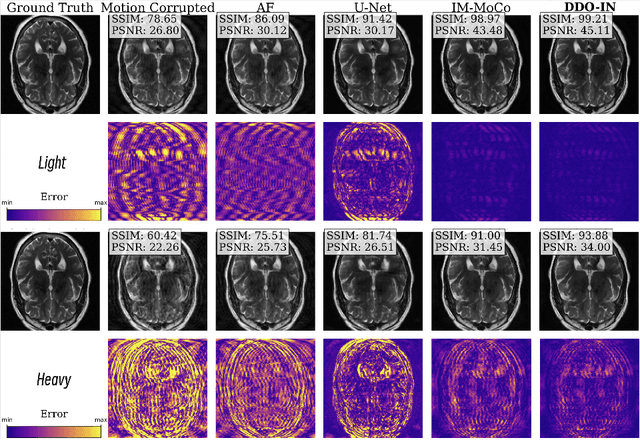
Magnetic resonance imaging (MRI) motion artifacts can seriously affect clinical diagnostics, making it challenging to interpret images accurately. Existing methods for eliminating motion artifacts struggle to retain fine structural details and simultaneously lack the necessary vividness and sharpness. In this study, we present a novel dual-domain optimization (DDO) approach that integrates information from the pixel and frequency domains guiding the recovery of clean magnetic resonance images through implicit neural representations(INRs). Specifically, our approach leverages the low-frequency components in the k-space as a reference to capture accurate tissue textures, while high-frequency and pixel information contribute to recover details. Furthermore, we design complementary masks and dynamic loss weighting transitioning from global to local attention that effectively suppress artifacts while retaining useful details for reconstruction. Experimental results on the NYU fastMRI dataset demonstrate that our method outperforms existing approaches in multiple evaluation metrics. Our code is available at https://anonymous.4open.science/r/DDO-IN-A73B.
Video-to-Task Learning via Motion-Guided Attention for Few-Shot Action Recognition
Nov 18, 2024



In recent years, few-shot action recognition has achieved remarkable performance through spatio-temporal relation modeling. Although a wide range of spatial and temporal alignment modules have been proposed, they primarily address spatial or temporal misalignments at the video level, while the spatio-temporal relationships across different videos at the task level remain underexplored. Recent studies utilize class prototypes to learn task-specific features but overlook the spatio-temporal relationships across different videos at the task level, especially in the spatial dimension, where these relationships provide rich information. In this paper, we propose a novel Dual Motion-Guided Attention Learning method (called DMGAL) for few-shot action recognition, aiming to learn the spatio-temporal relationships from the video-specific to the task-specific level. To achieve this, we propose a carefully designed Motion-Guided Attention (MGA) method to identify and correlate motion-related region features from the video level to the task level. Specifically, the Self Motion-Guided Attention module (S-MGA) achieves spatio-temporal relation modeling at the video level by identifying and correlating motion-related region features between different frames within a video. The Cross Motion-Guided Attention module (C-MGA) identifies and correlates motion-related region features between frames of different videos within a specific task to achieve spatio-temporal relationships at the task level. This approach enables the model to construct class prototypes that fully incorporate spatio-temporal relationships from the video-specific level to the task-specific level. We validate the effectiveness of our DMGAL method by employing both fully fine-tuning and adapter-tuning paradigms. The models developed using these paradigms are termed DMGAL-FT and DMGAL-Adapter, respectively.
Generalized Value Iteration Networks: Life Beyond Lattices
Oct 26, 2017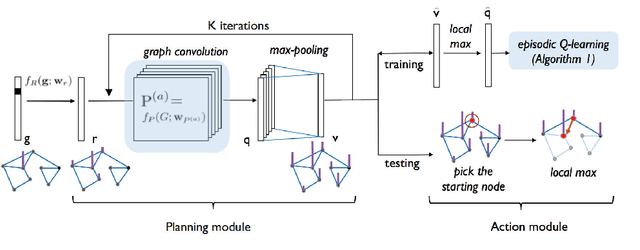
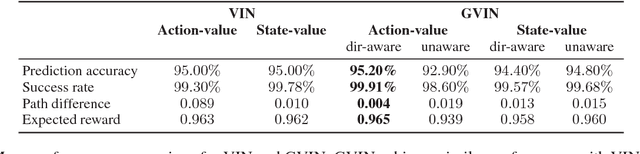
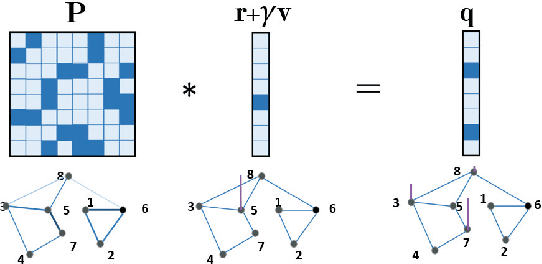

In this paper, we introduce a generalized value iteration network (GVIN), which is an end-to-end neural network planning module. GVIN emulates the value iteration algorithm by using a novel graph convolution operator, which enables GVIN to learn and plan on irregular spatial graphs. We propose three novel differentiable kernels as graph convolution operators and show that the embedding based kernel achieves the best performance. We further propose episodic Q-learning, an improvement upon traditional n-step Q-learning that stabilizes training for networks that contain a planning module. Lastly, we evaluate GVIN on planning problems in 2D mazes, irregular graphs, and real-world street networks, showing that GVIN generalizes well for both arbitrary graphs and unseen graphs of larger scale and outperforms a naive generalization of VIN (discretizing a spatial graph into a 2D image).