 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Mixtral of Experts
Jan 08, 2024



We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
Mistral 7B
Oct 10, 2023



We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
Gym-$μ$RTS: Toward Affordable Full Game Real-time Strategy Games Research with Deep Reinforcement Learning
May 21, 2021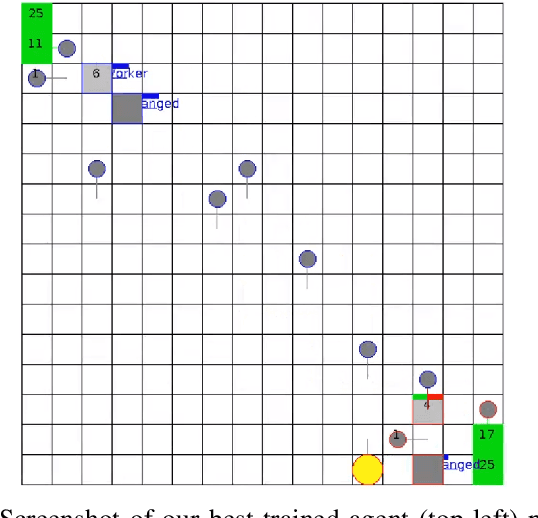
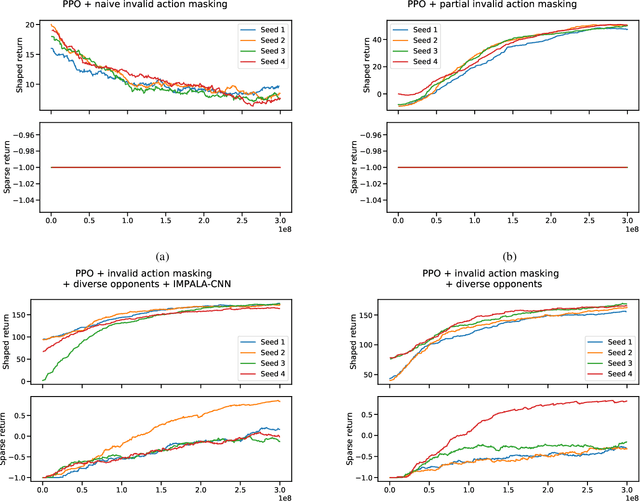
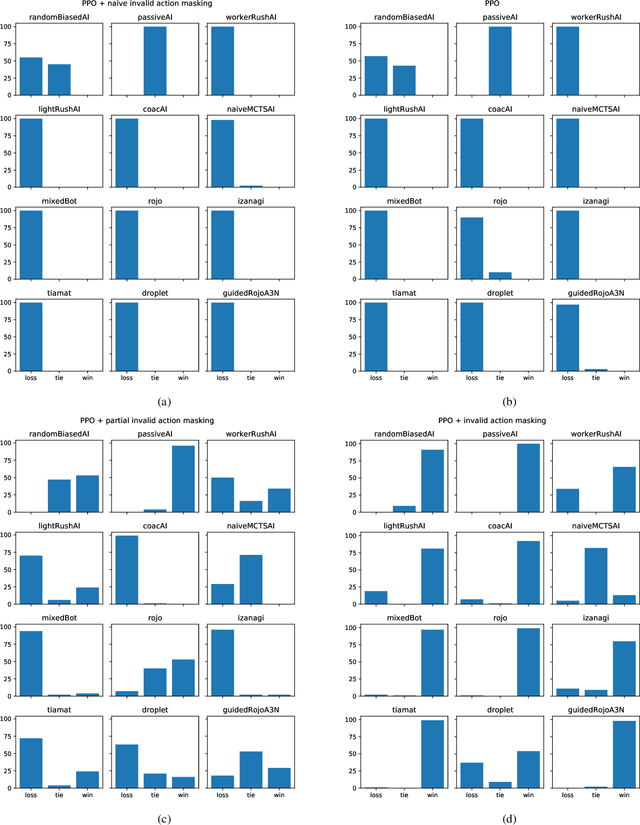
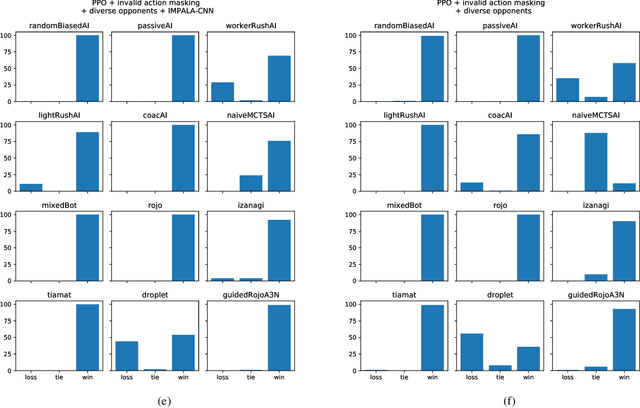
In recent years, researchers have achieved great success in applying Deep Reinforcement Learning (DRL) algorithms to Real-time Strategy (RTS) games, creating strong autonomous agents that could defeat professional players in StarCraft~II. However, existing approaches to tackle full games have high computational costs, usually requiring the use of thousands of GPUs and CPUs for weeks. This paper has two main contributions to address this issue: 1) We introduce Gym-$\mu$RTS (pronounced "gym-micro-RTS") as a fast-to-run RL environment for full-game RTS research and 2) we present a collection of techniques to scale DRL to play full-game $\mu$RTS as well as ablation studies to demonstrate their empirical importance. Our best-trained bot can defeat every $\mu$RTS bot we tested from the past $\mu$RTS competitions when working in a single-map setting, resulting in a state-of-the-art DRL agent while only taking about 60 hours of training using a single machine (one GPU, three vCPU, 16GB RAM).
Griddly: A platform for AI research in games
Nov 21, 2020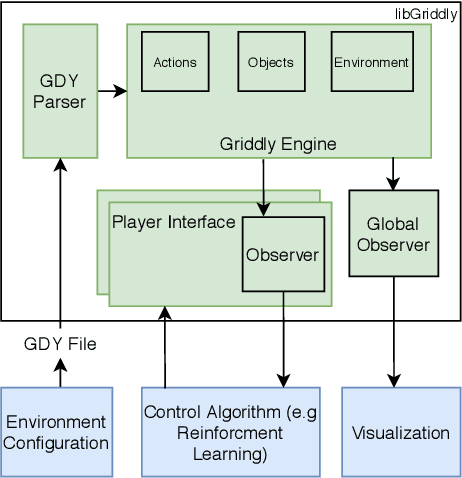

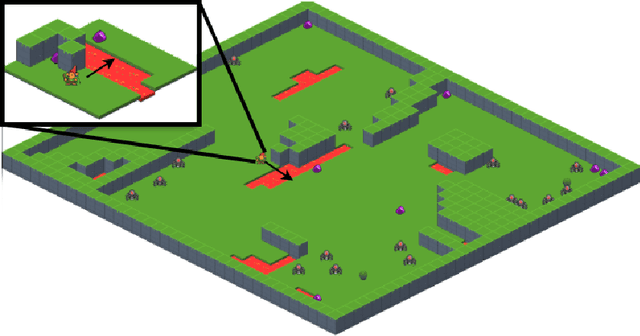
In recent years, there have been immense breakthroughs in Game AI research, particularly with Reinforcement Learning (RL). Despite their success, the underlying games are usually implemented with their own preset environments and game mechanics, thus making it difficult for researchers to prototype different game environments. However, testing the RL agents against a variety of game environments is critical for recent effort to study generalization in RL and avoid the problem of overfitting that may otherwise occur. In this paper, we present Griddly as a new platform for Game AI research that provides a unique combination of highly configurable games, different observer types and an efficient C++ core engine. Additionally, we present a series of baseline experiments to study the effect of different observation configurations and generalization ability of RL agents.
Neural Game Engine: Accurate learning of generalizable forward models from pixels
Mar 31, 2020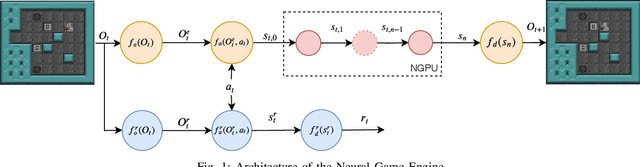
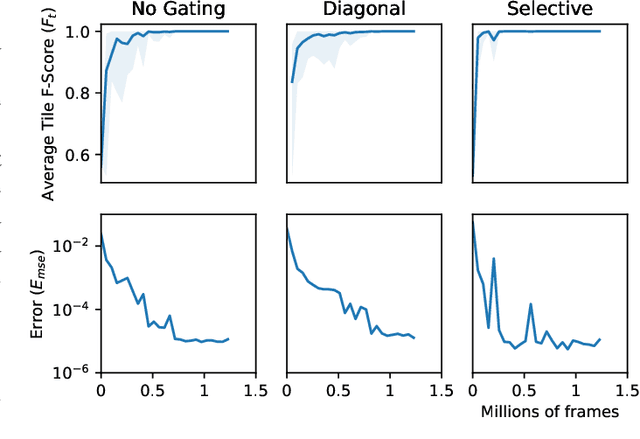
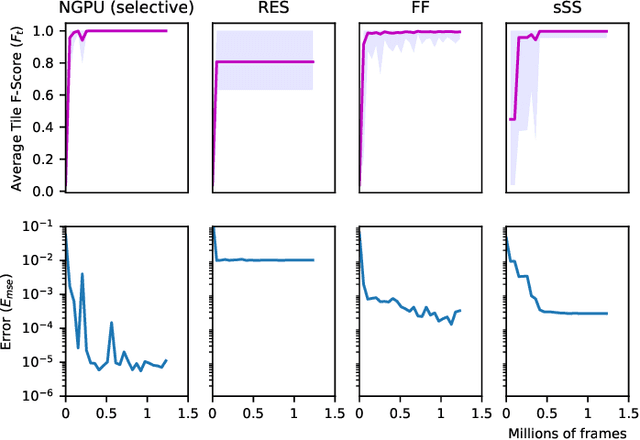
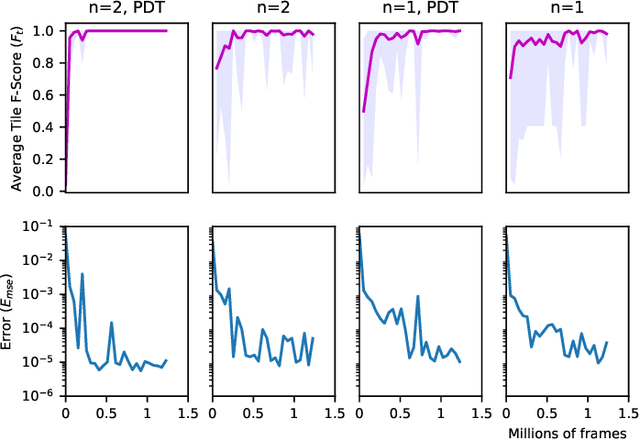
Access to a fast and easily copied forward model of a game is essential for model-based reinforcement learning and for algorithms such as Monte Carlo tree search, and is also beneficial as a source of unlimited experience data for model-free algorithms. Learning forward models is an interesting and important challenge in order to address problems where a model is not available. Building upon previous work on the Neural GPU, this paper introduces the Neural Game Engine, as a way to learn models directly from pixels. The learned models are able to generalise to different size game levels to the ones they were trained on without loss of accuracy. Results on 10 deterministic General Video Game AI games demonstrate competitive performance, with many of the games models being learned perfectly both in terms of pixel predictions and reward predictions. The pre-trained models are available through the OpenAI Gym interface and are available publicly for future research here: \url{https://github.com/Bam4d/Neural-Game-Engine}
A Local Approach to Forward Model Learning: Results on the Game of Life Game
Mar 29, 2019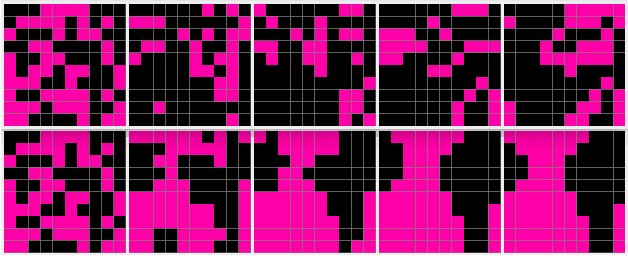
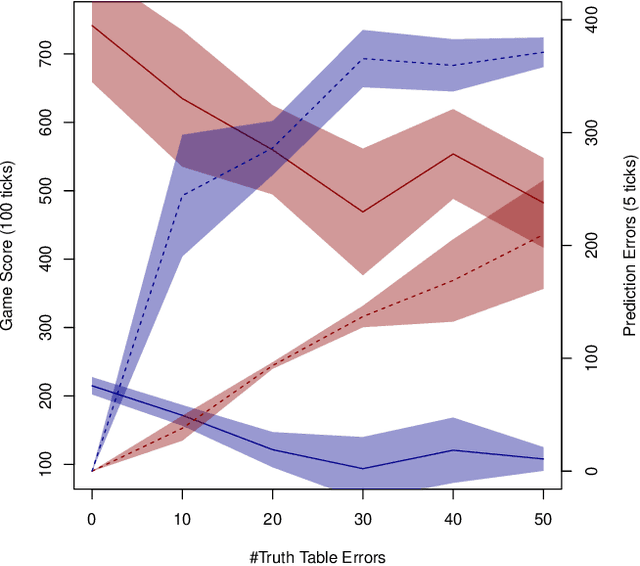
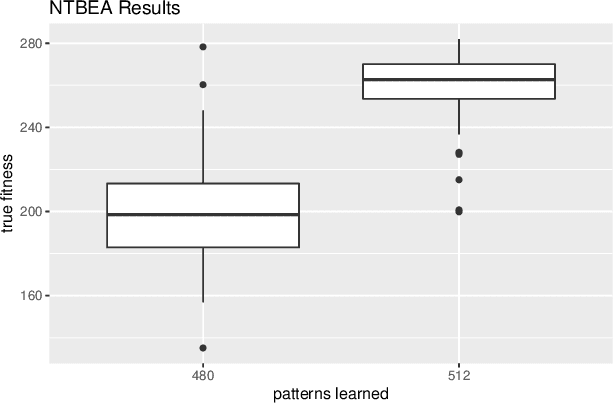
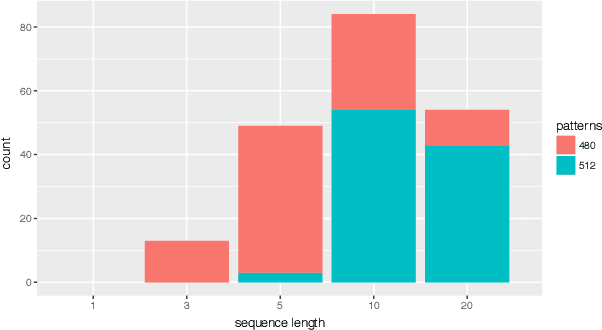
This paper investigates the effect of learning a forward model on the performance of a statistical forward planning agent. We transform Conway's Game of Life simulation into a single-player game where the objective can be either to preserve as much life as possible or to extinguish all life as quickly as possible. In order to learn the forward model of the game, we formulate the problem in a novel way that learns the local cell transition function by creating a set of supervised training data and predicting the next state of each cell in the grid based on its current state and immediate neighbours. Using this method we are able to harvest sufficient data to learn perfect forward models by observing only a few complete state transitions, using either a look-up table, a decision tree or a neural network. In contrast, learning the complete state transition function is a much harder task and our initial efforts to do this using deep convolutional auto-encoders were less successful. We also investigate the effects of imperfect learned models on prediction errors and game-playing performance, and show that even models with significant errors can provide good performance.