 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGym-$μ$RTS: Toward Affordable Full Game Real-time Strategy Games Research with Deep Reinforcement Learning
May 21, 2021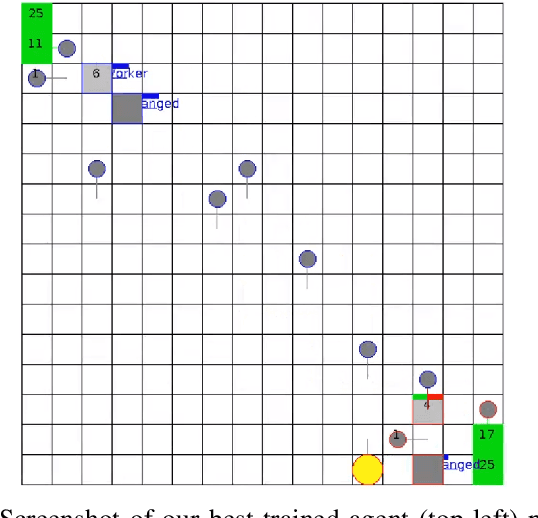
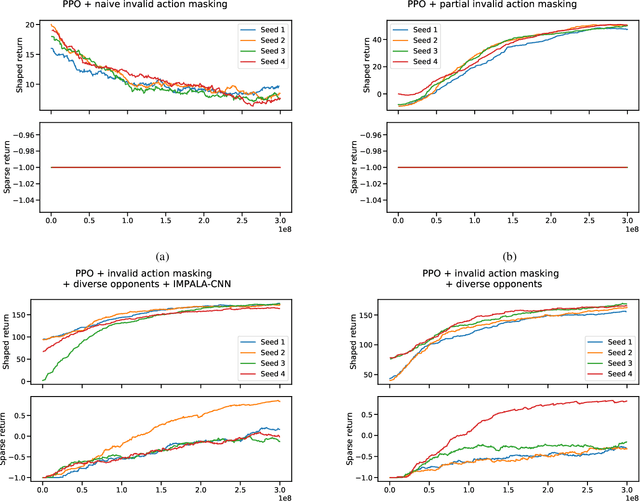
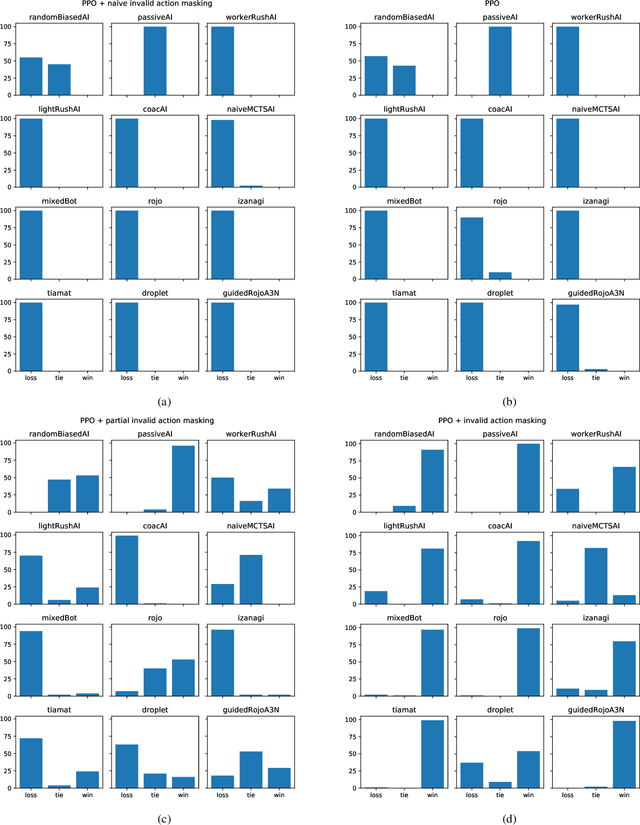
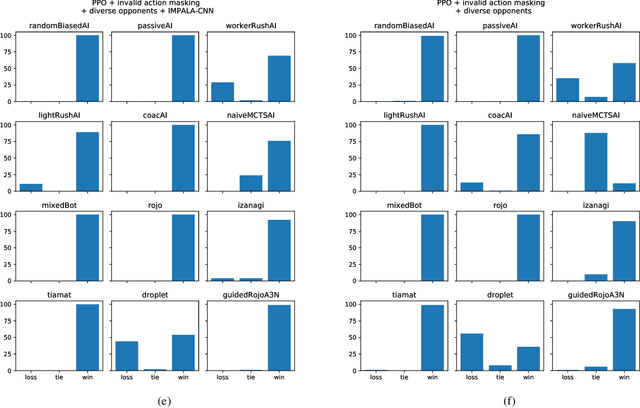
In recent years, researchers have achieved great success in applying Deep Reinforcement Learning (DRL) algorithms to Real-time Strategy (RTS) games, creating strong autonomous agents that could defeat professional players in StarCraft~II. However, existing approaches to tackle full games have high computational costs, usually requiring the use of thousands of GPUs and CPUs for weeks. This paper has two main contributions to address this issue: 1) We introduce Gym-$\mu$RTS (pronounced "gym-micro-RTS") as a fast-to-run RL environment for full-game RTS research and 2) we present a collection of techniques to scale DRL to play full-game $\mu$RTS as well as ablation studies to demonstrate their empirical importance. Our best-trained bot can defeat every $\mu$RTS bot we tested from the past $\mu$RTS competitions when working in a single-map setting, resulting in a state-of-the-art DRL agent while only taking about 60 hours of training using a single machine (one GPU, three vCPU, 16GB RAM).