 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform
Sep 29, 2023
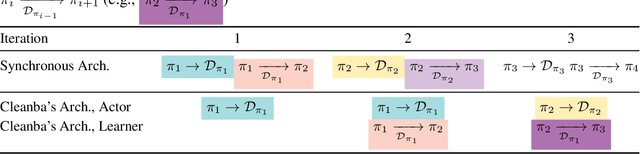
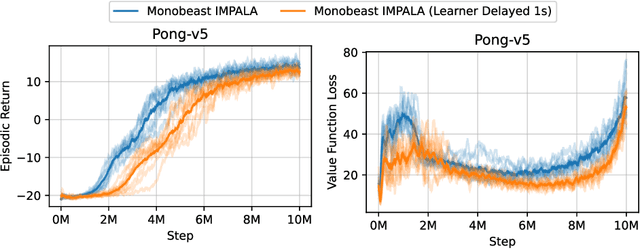

Distributed Deep Reinforcement Learning (DRL) aims to leverage more computational resources to train autonomous agents with less training time. Despite recent progress in the field, reproducibility issues have not been sufficiently explored. This paper first shows that the typical actor-learner framework can have reproducibility issues even if hyperparameters are controlled. We then introduce Cleanba, a new open-source platform for distributed DRL that proposes a highly reproducible architecture. Cleanba implements highly optimized distributed variants of PPO and IMPALA. Our Atari experiments show that these variants can obtain equivalent or higher scores than strong IMPALA baselines in moolib and torchbeast and PPO baseline in CleanRL. However, Cleanba variants present 1) shorter training time and 2) more reproducible learning curves in different hardware settings. Cleanba's source code is available at \url{https://github.com/vwxyzjn/cleanba}
MEMORY-VQ: Compression for Tractable Internet-Scale Memory
Aug 28, 2023



Retrieval augmentation is a powerful but expensive method to make language models more knowledgeable about the world. Memory-based methods like LUMEN pre-compute token representations for retrieved passages to drastically speed up inference. However, memory also leads to much greater storage requirements from storing pre-computed representations. We propose MEMORY-VQ, a new method to reduce storage requirements of memory-augmented models without sacrificing performance. Our method uses a vector quantization variational autoencoder (VQ-VAE) to compress token representations. We apply MEMORY-VQ to the LUMEN model to obtain LUMEN-VQ, a memory model that achieves a 16x compression rate with comparable performance on the KILT benchmark. LUMEN-VQ enables practical retrieval augmentation even for extremely large retrieval corpora.
mLongT5: A Multilingual and Efficient Text-To-Text Transformer for Longer Sequences
May 18, 2023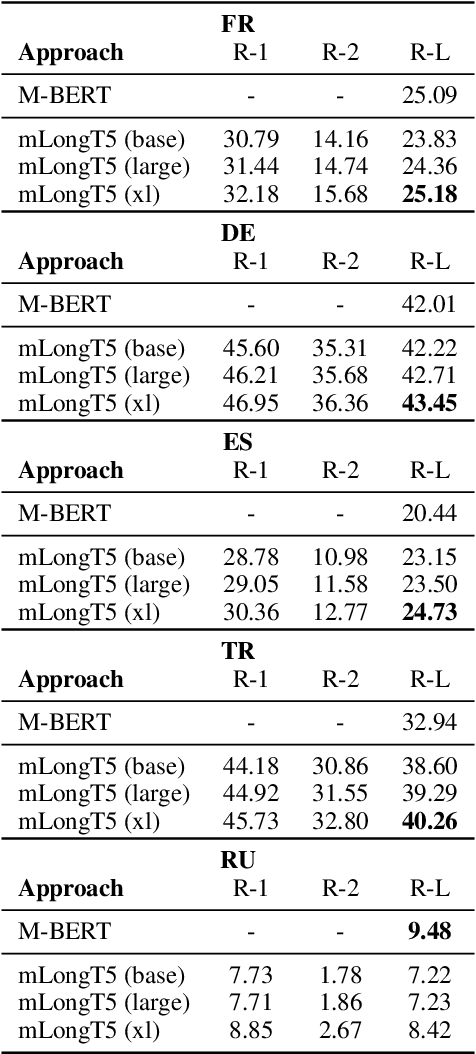
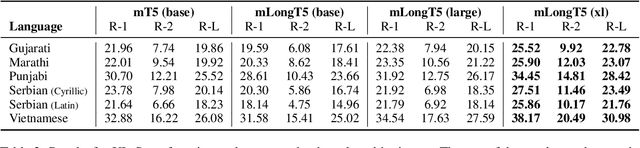
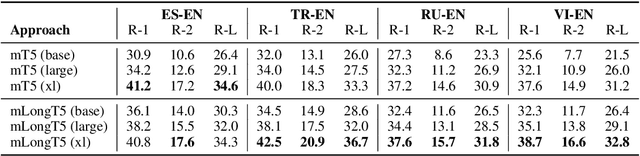
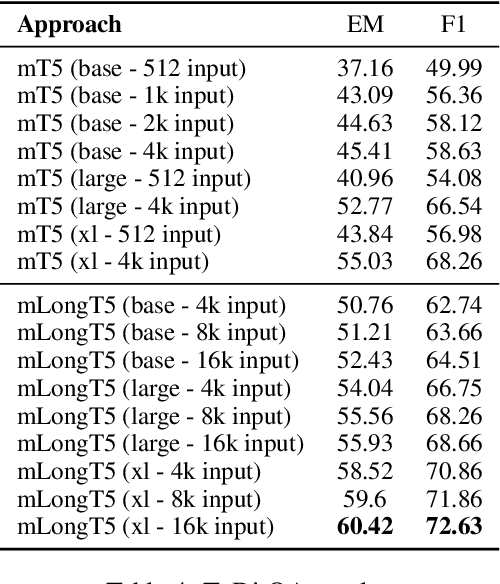
We present our work on developing a multilingual, efficient text-to-text transformer that is suitable for handling long inputs. This model, called mLongT5, builds upon the architecture of LongT5, while leveraging the multilingual datasets used for pretraining mT5 and the pretraining tasks of UL2. We evaluate this model on a variety of multilingual summarization and question-answering tasks, and the results show stronger performance for mLongT5 when compared to existing multilingual models such as mBART or M-BERT.
CoLT5: Faster Long-Range Transformers with Conditional Computation
Mar 17, 2023Many natural language processing tasks benefit from long inputs, but processing long documents with Transformers is expensive -- not only due to quadratic attention complexity but also from applying feedforward and projection layers to every token. However, not all tokens are equally important, especially for longer documents. We propose CoLT5, a long-input Transformer model that builds on this intuition by employing conditional computation, devoting more resources to important tokens in both feedforward and attention layers. We show that CoLT5 achieves stronger performance than LongT5 with much faster training and inference, achieving SOTA on the long-input SCROLLS benchmark. Moreover, CoLT5 can effectively and tractably make use of extremely long inputs, showing strong gains up to 64k input length.
Improving Fairness in Adaptive Social Exergames via Shapley Bandits
Feb 21, 2023Algorithmic fairness is an essential requirement as AI becomes integrated in society. In the case of social applications where AI distributes resources, algorithms often must make decisions that will benefit a subset of users, sometimes repeatedly or exclusively, while attempting to maximize specific outcomes. How should we design such systems to serve users more fairly? This paper explores this question in the case where a group of users works toward a shared goal in a social exergame called Step Heroes. We identify adverse outcomes in traditional multi-armed bandits (MABs) and formalize the Greedy Bandit Problem. We then propose a solution based on a new type of fairness-aware multi-armed bandit, Shapley Bandits. It uses the Shapley Value for increasing overall player participation and intervention adherence rather than the maximization of total group output, which is traditionally achieved by favoring only high-performing participants. We evaluate our approach via a user study (n=46). Our results indicate that our Shapley Bandits effectively mediates the Greedy Bandit Problem and achieves better user retention and motivation across the participants.
A2C is a special case of PPO
May 18, 2022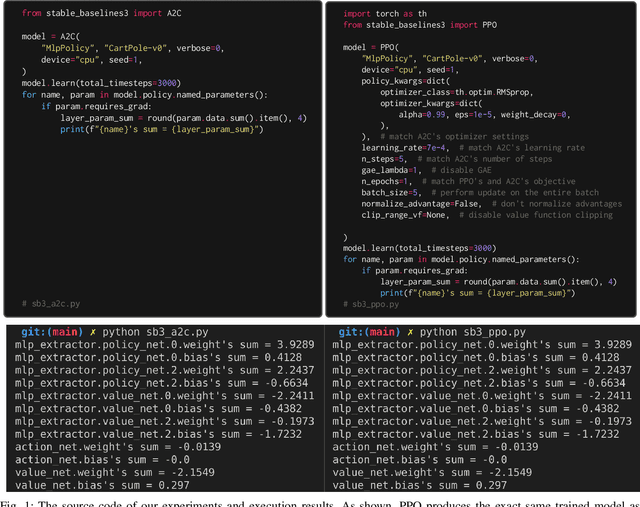
Advantage Actor-critic (A2C) and Proximal Policy Optimization (PPO) are popular deep reinforcement learning algorithms used for game AI in recent years. A common understanding is that A2C and PPO are separate algorithms because PPO's clipped objective appears significantly different than A2C's objective. In this paper, however, we show A2C is a special case of PPO. We present theoretical justifications and pseudocode analysis to demonstrate why. To validate our claim, we conduct an empirical experiment using \texttt{Stable-baselines3}, showing A2C and PPO produce the \textit{exact} same models when other settings are controlled.
Identifying On-road Scenarios Predictive of ADHD usingDriving Simulator Time Series Data
Nov 12, 2021

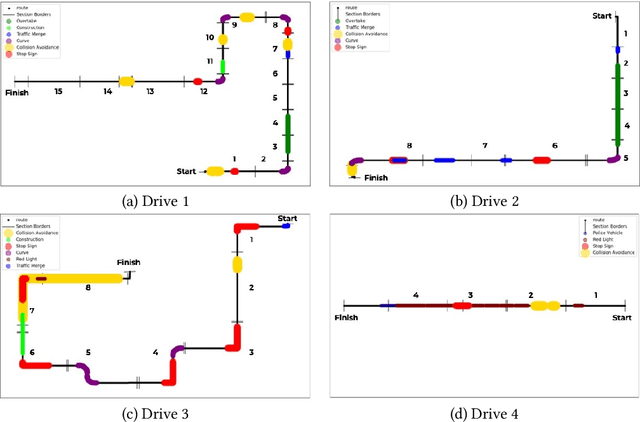

In this paper we introduce a novel algorithm called Iterative Section Reduction (ISR) to automatically identify sub-intervals of spatiotemporal time series that are predictive of a target classification task. Specifically, using data collected from a driving simulator study, we identify which spatial regions (dubbed "sections") along the simulated routes tend to manifest driving behaviors that are predictive of the presence of Attention Deficit Hyperactivity Disorder (ADHD). Identifying these sections is important for two main reasons: (1) to improve predictive accuracy of the trained models by filtering out non-predictive time series sub-intervals, and (2) to gain insights into which on-road scenarios (dubbed events) elicit distinctly different driving behaviors from patients undergoing treatment for ADHD versus those that are not. Our experimental results show both improved performance over prior efforts (+10% accuracy) and good alignment between the predictive sections identified and scripted on-road events in the simulator (negotiating turns and curves).
Iterative Decoding for Compositional Generalization in Transformers
Oct 08, 2021
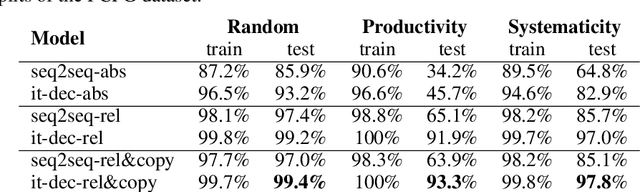

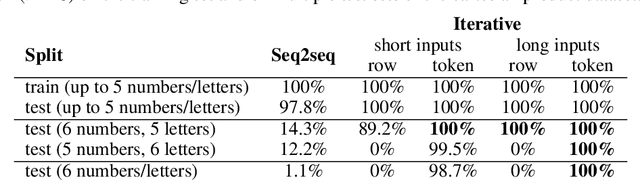
Deep learning models do well at generalizing to in-distribution data but struggle to generalize compositionally, i.e., to combine a set of learned primitives to solve more complex tasks. In particular, in sequence-to-sequence (seq2seq) learning, transformers are often unable to predict correct outputs for even marginally longer examples than those seen during training. This paper introduces iterative decoding, an alternative to seq2seq learning that (i) improves transformer compositional generalization and (ii) evidences that, in general, seq2seq transformers do not learn iterations that are not unrolled. Inspired by the idea of compositionality -- that complex tasks can be solved by composing basic primitives -- training examples are broken down into a sequence of intermediate steps that the transformer then learns iteratively. At inference time, the intermediate outputs are fed back to the transformer as intermediate inputs until an end-of-iteration token is predicted. Through numerical experiments, we show that transfomers trained via iterative decoding outperform their seq2seq counterparts on the PCFG dataset, and solve the problem of calculating Cartesian products between vectors longer than those seen during training with 100% accuracy, a task at which seq2seq models have been shown to fail. We also illustrate a limitation of iterative decoding, specifically, that it can make sorting harder to learn on the CFQ dataset.
Making Transformers Solve Compositional Tasks
Aug 09, 2021

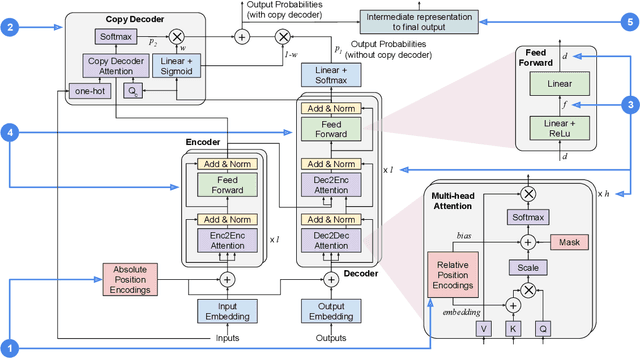

Several studies have reported the inability of Transformer models to generalize compositionally, a key type of generalization in many NLP tasks such as semantic parsing. In this paper we explore the design space of Transformer models showing that the inductive biases given to the model by several design decisions significantly impact compositional generalization. Through this exploration, we identified Transformer configurations that generalize compositionally significantly better than previously reported in the literature in a diverse set of compositional tasks, and that achieve state-of-the-art results in a semantic parsing compositional generalization benchmark (COGS), and a string edit operation composition benchmark (PCFG).