Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemLongT5: A Multilingual and Efficient Text-To-Text Transformer for Longer Sequences
Paper and Code
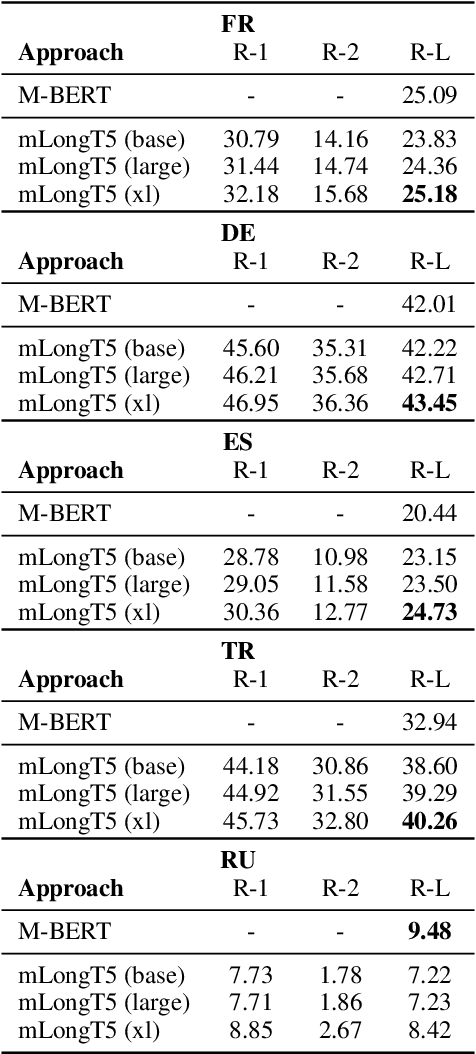
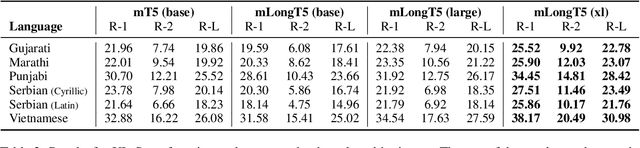
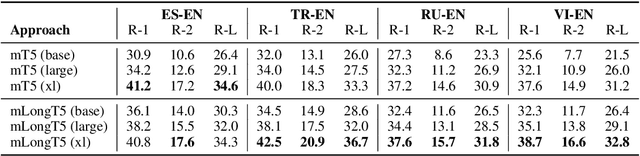
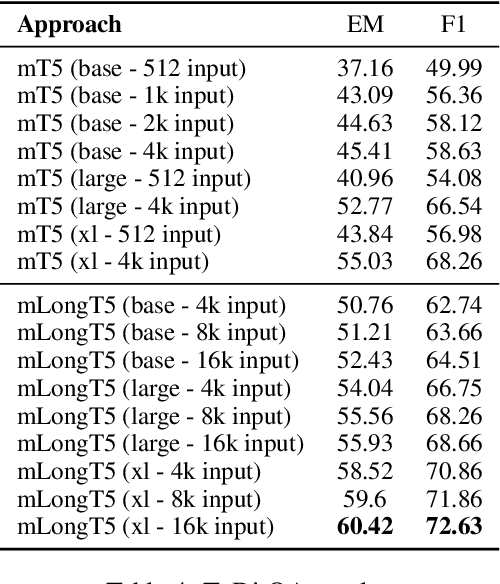
We present our work on developing a multilingual, efficient text-to-text transformer that is suitable for handling long inputs. This model, called mLongT5, builds upon the architecture of LongT5, while leveraging the multilingual datasets used for pretraining mT5 and the pretraining tasks of UL2. We evaluate this model on a variety of multilingual summarization and question-answering tasks, and the results show stronger performance for mLongT5 when compared to existing multilingual models such as mBART or M-BERT.
View paper on