 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMORY-VQ: Compression for Tractable Internet-Scale Memory
Aug 28, 2023



Retrieval augmentation is a powerful but expensive method to make language models more knowledgeable about the world. Memory-based methods like LUMEN pre-compute token representations for retrieved passages to drastically speed up inference. However, memory also leads to much greater storage requirements from storing pre-computed representations. We propose MEMORY-VQ, a new method to reduce storage requirements of memory-augmented models without sacrificing performance. Our method uses a vector quantization variational autoencoder (VQ-VAE) to compress token representations. We apply MEMORY-VQ to the LUMEN model to obtain LUMEN-VQ, a memory model that achieves a 16x compression rate with comparable performance on the KILT benchmark. LUMEN-VQ enables practical retrieval augmentation even for extremely large retrieval corpora.
GLIMMER: generalized late-interaction memory reranker
Jun 17, 2023



Memory-augmentation is a powerful approach for efficiently incorporating external information into language models, but leads to reduced performance relative to retrieving text. Recent work introduced LUMEN, a memory-retrieval hybrid that partially pre-computes memory and updates memory representations on the fly with a smaller live encoder. We propose GLIMMER, which improves on this approach through 1) exploiting free access to the powerful memory representations by applying a shallow reranker on top of memory to drastically improve retrieval quality at low cost, and 2) incorporating multi-task training to learn a general and higher quality memory and live encoder. GLIMMER achieves strong gains in performance at faster speeds compared to LUMEN and FiD on the KILT benchmark of knowledge-intensive tasks.
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
May 22, 2023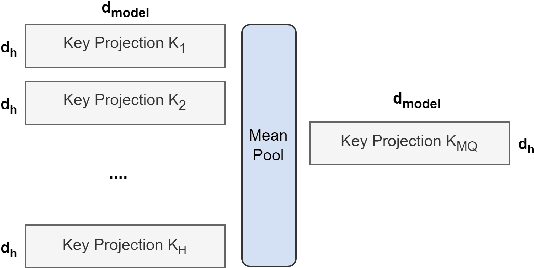
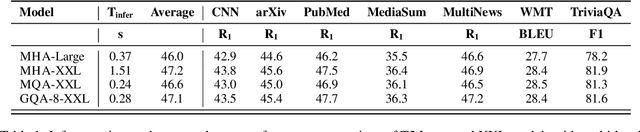
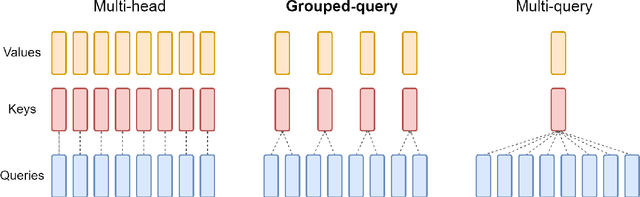
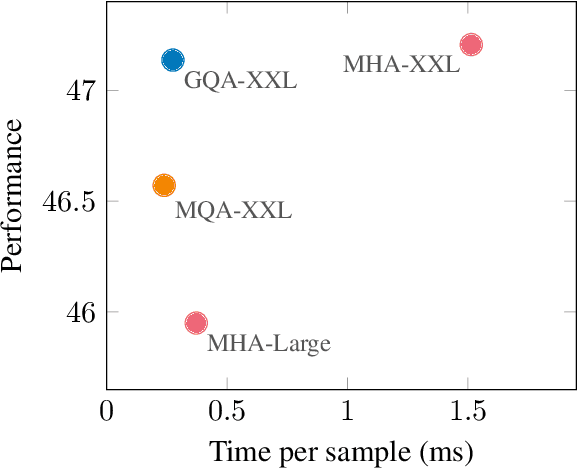
Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. We (1) propose a recipe for uptraining existing multi-head language model checkpoints into models with MQA using 5% of original pre-training compute, and (2) introduce grouped-query attention (GQA), a generalization of multi-query attention which uses an intermediate (more than one, less than number of query heads) number of key-value heads. We show that uptrained GQA achieves quality close to multi-head attention with comparable speed to MQA.
CoLT5: Faster Long-Range Transformers with Conditional Computation
Mar 17, 2023Many natural language processing tasks benefit from long inputs, but processing long documents with Transformers is expensive -- not only due to quadratic attention complexity but also from applying feedforward and projection layers to every token. However, not all tokens are equally important, especially for longer documents. We propose CoLT5, a long-input Transformer model that builds on this intuition by employing conditional computation, devoting more resources to important tokens in both feedforward and attention layers. We show that CoLT5 achieves stronger performance than LongT5 with much faster training and inference, achieving SOTA on the long-input SCROLLS benchmark. Moreover, CoLT5 can effectively and tractably make use of extremely long inputs, showing strong gains up to 64k input length.
Pre-computed memory or on-the-fly encoding? A hybrid approach to retrieval augmentation makes the most of your compute
Jan 25, 2023



Retrieval-augmented language models such as Fusion-in-Decoder are powerful, setting the state of the art on a variety of knowledge-intensive tasks. However, they are also expensive, due to the need to encode a large number of retrieved passages. Some work avoids this cost by pre-encoding a text corpus into a memory and retrieving dense representations directly. However, pre-encoding memory incurs a severe quality penalty as the memory representations are not conditioned on the current input. We propose LUMEN, a hybrid between these two extremes, pre-computing the majority of the retrieval representation and completing the encoding on the fly using a live encoder that is conditioned on the question and fine-tuned for the task. We show that LUMEN significantly outperforms pure memory on multiple question-answering tasks while being much cheaper than FiD, and outperforms both for any given compute budget. Moreover, the advantage of LUMEN over FiD increases with model size.
FiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Dec 15, 2022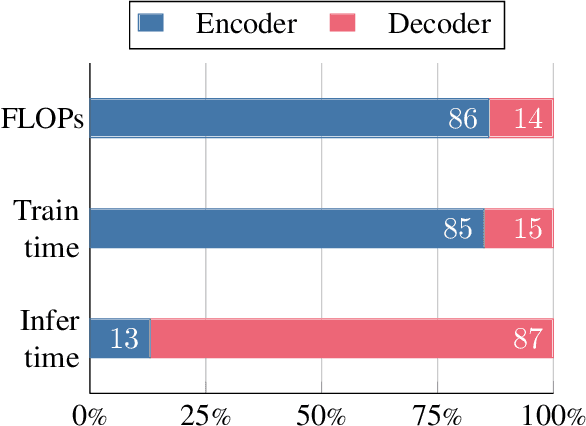

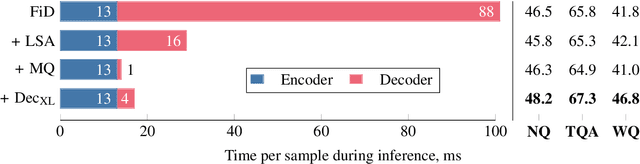

Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
Generate-and-Retrieve: use your predictions to improve retrieval for semantic parsing
Sep 29, 2022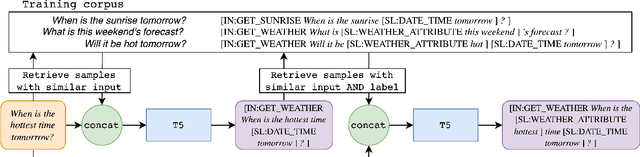
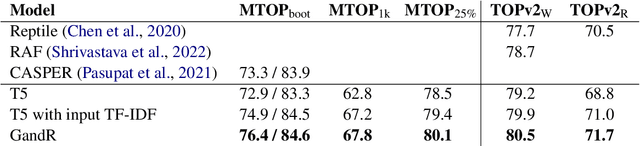
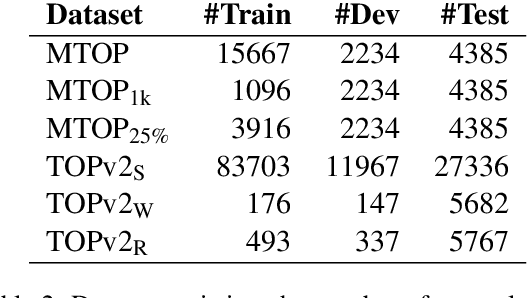
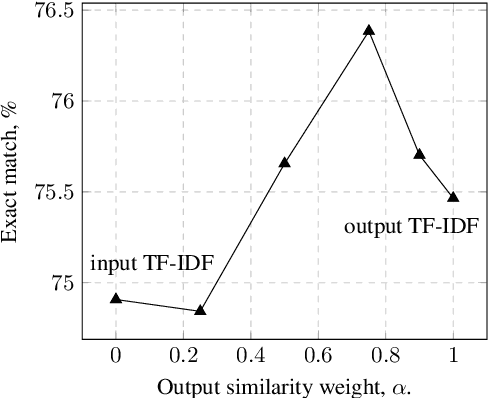
A common recent approach to semantic parsing augments sequence-to-sequence models by retrieving and appending a set of training samples, called exemplars. The effectiveness of this recipe is limited by the ability to retrieve informative exemplars that help produce the correct parse, which is especially challenging in low-resource settings. Existing retrieval is commonly based on similarity of query and exemplar inputs. We propose GandR, a retrieval procedure that retrieves exemplars for which outputs are also similar. GandRfirst generates a preliminary prediction with input-based retrieval. Then, it retrieves exemplars with outputs similar to the preliminary prediction which are used to generate a final prediction. GandR sets the state of the art on multiple low-resource semantic parsing tasks.
Mention Memory: incorporating textual knowledge into Transformers through entity mention attention
Oct 12, 2021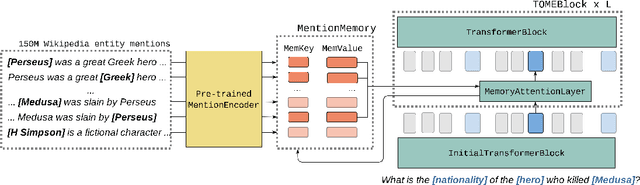
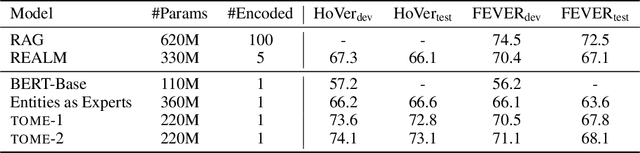
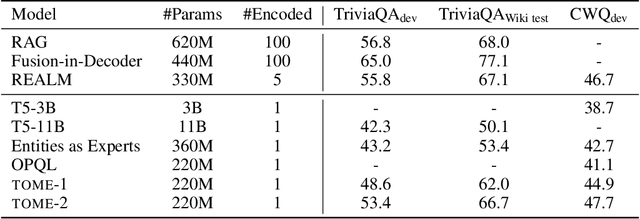
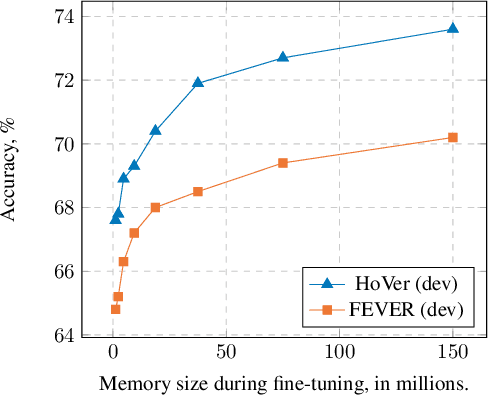
Natural language understanding tasks such as open-domain question answering often require retrieving and assimilating factual information from multiple sources. We propose to address this problem by integrating a semi-parametric representation of a large text corpus into a Transformer model as a source of factual knowledge. Specifically, our method represents knowledge with `mention memory', a table of dense vector representations of every entity mention in a corpus. The proposed model - TOME - is a Transformer that accesses the information through internal memory layers in which each entity mention in the input passage attends to the mention memory. This approach enables synthesis of and reasoning over many disparate sources of information within a single Transformer model. In experiments using a memory of 150 million Wikipedia mentions, TOME achieves strong performance on several open-domain knowledge-intensive tasks, including the claim verification benchmarks HoVer and FEVER and several entity-based QA benchmarks. We also show that the model learns to attend to informative mentions without any direct supervision. Finally we demonstrate that the model can generalize to new unseen entities by updating the memory without retraining.
ReadTwice: Reading Very Large Documents with Memories
May 11, 2021

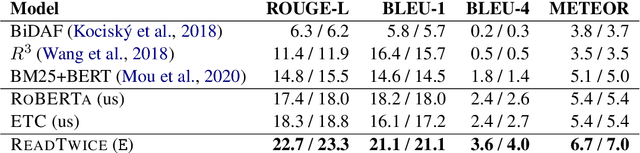
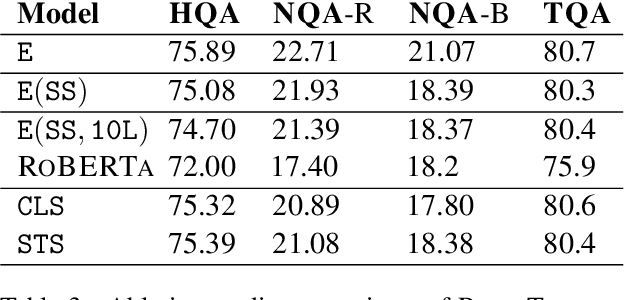
Knowledge-intensive tasks such as question answering often require assimilating information from different sections of large inputs such as books or article collections. We propose ReadTwice, a simple and effective technique that combines several strengths of prior approaches to model long-range dependencies with Transformers. The main idea is to read text in small segments, in parallel, summarizing each segment into a memory table to be used in a second read of the text. We show that the method outperforms models of comparable size on several question answering (QA) datasets and sets a new state of the art on the challenging NarrativeQA task, with questions about entire books. Source code and pre-trained checkpoints for ReadTwice can be found at https://goo.gle/research-readtwice.
DOCENT: Learning Self-Supervised Entity Representations from Large Document Collections
Feb 26, 2021

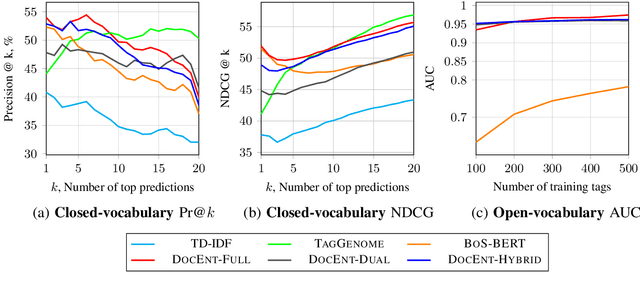
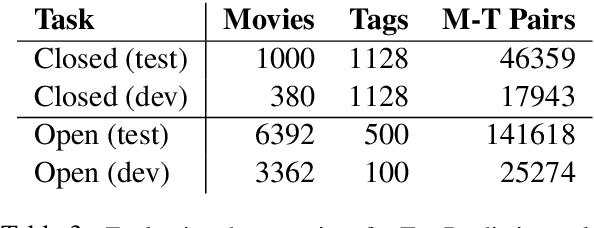
This paper explores learning rich self-supervised entity representations from large amounts of the associated text. Once pre-trained, these models become applicable to multiple entity-centric tasks such as ranked retrieval, knowledge base completion, question answering, and more. Unlike other methods that harvest self-supervision signals based merely on a local context within a sentence, we radically expand the notion of context to include any available text related to an entity. This enables a new class of powerful, high-capacity representations that can ultimately distill much of the useful information about an entity from multiple text sources, without any human supervision. We present several training strategies that, unlike prior approaches, learn to jointly predict words and entities -- strategies we compare experimentally on downstream tasks in the TV-Movies domain, such as MovieLens tag prediction from user reviews and natural language movie search. As evidenced by results, our models match or outperform competitive baselines, sometimes with little or no fine-tuning, and can scale to very large corpora. Finally, we make our datasets and pre-trained models publicly available. This includes Reviews2Movielens (see https://goo.gle/research-docent ), mapping the up to 1B word corpus of Amazon movie reviews (He and McAuley, 2016) to MovieLens tags (Harper and Konstan, 2016), as well as Reddit Movie Suggestions (see https://urikz.github.io/docent ) with natural language queries and corresponding community recommendations.