 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


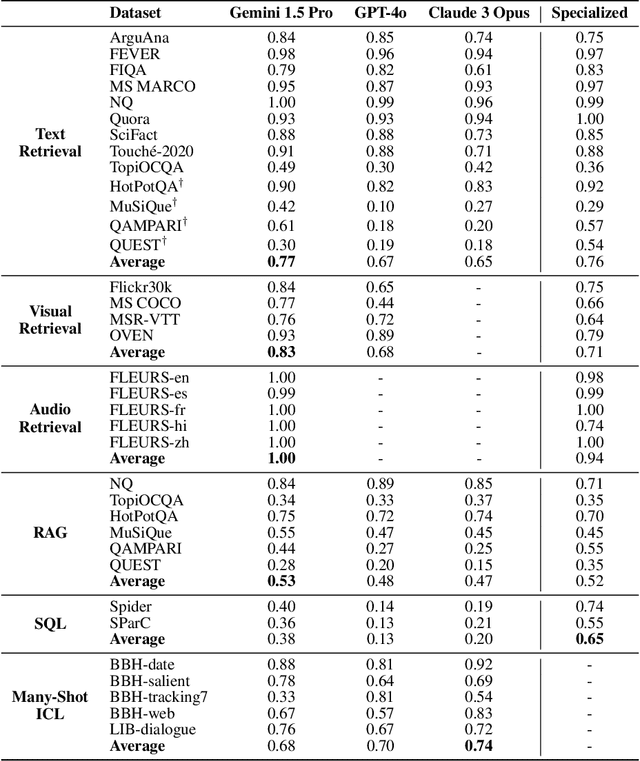
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
In-context Learning with Retrieved Demonstrations for Language Models: A Survey
Jan 23, 2024Language models, especially pre-trained large language models, have showcased remarkable abilities as few-shot in-context learners (ICL), adept at adapting to new tasks with just a few demonstrations in the input context. However, the model's ability to perform ICL is sensitive to the choice of the few-shot demonstrations. Instead of using a fixed set of demonstrations, one recent development is to retrieve demonstrations tailored to each input query. The implementation of demonstration retrieval is relatively straightforward, leveraging existing databases and retrieval systems. This not only improves the efficiency and scalability of the learning process but also has been shown to reduce biases inherent in manual example selection. In light of the encouraging results and growing research in ICL with retrieved demonstrations, we conduct an extensive review of studies in this area. In this survey, we discuss and compare different design choices for retrieval models, retrieval training procedures, and inference algorithms.
Large Language Models as Analogical Reasoners
Oct 07, 2023



Chain-of-thought (CoT) prompting for language models demonstrates impressive performance across reasoning tasks, but typically needs labeled exemplars of the reasoning process. In this work, we introduce a new prompting approach, Analogical Prompting, designed to automatically guide the reasoning process of large language models. Inspired by analogical reasoning, a cognitive process in which humans draw from relevant past experiences to tackle new problems, our approach prompts language models to self-generate relevant exemplars or knowledge in the context, before proceeding to solve the given problem. This method presents several advantages: it obviates the need for labeling or retrieving exemplars, offering generality and convenience; it can also tailor the generated exemplars and knowledge to each problem, offering adaptability. Experimental results show that our approach outperforms 0-shot CoT and manual few-shot CoT in a variety of reasoning tasks, including math problem solving in GSM8K and MATH, code generation in Codeforces, and other reasoning tasks in BIG-Bench.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023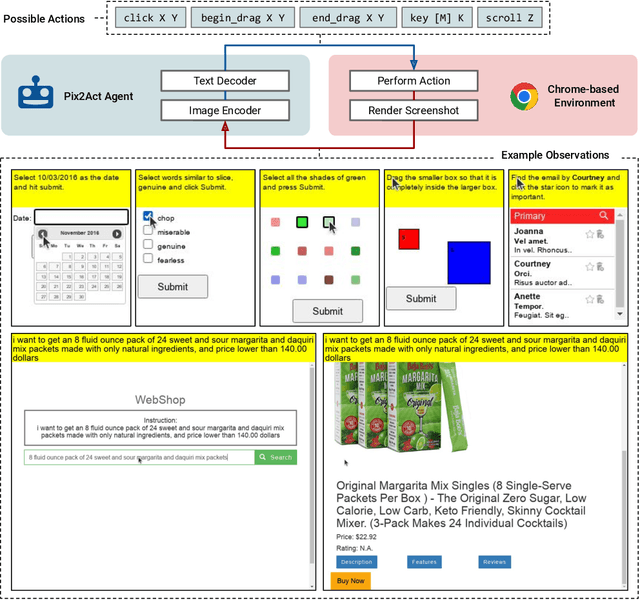
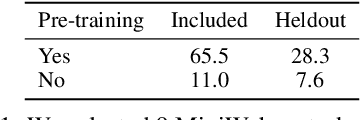
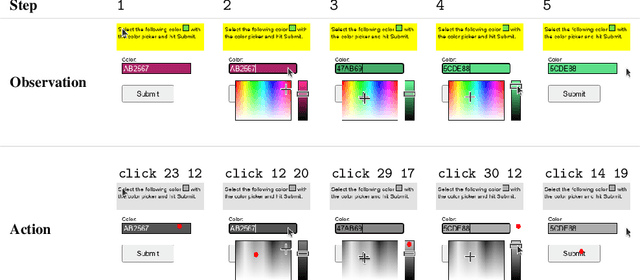
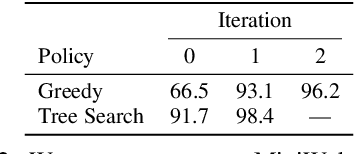
Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
PURR: Efficiently Editing Language Model Hallucinations by Denoising Language Model Corruptions
May 24, 2023

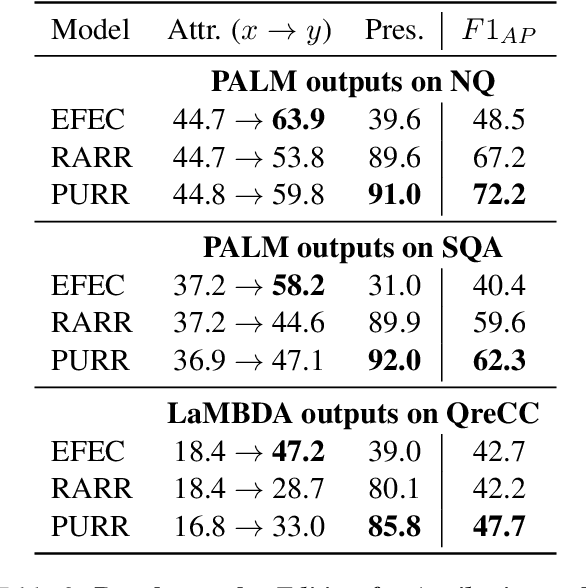

The remarkable capabilities of large language models have been accompanied by a persistent drawback: the generation of false and unsubstantiated claims commonly known as "hallucinations". To combat this issue, recent research has introduced approaches that involve editing and attributing the outputs of language models, particularly through prompt-based editing. However, the inference cost and speed of using large language models for editing currently bottleneck prompt-based methods. These bottlenecks motivate the training of compact editors, which is challenging due to the scarcity of training data for this purpose. To overcome these challenges, we exploit the power of large language models to introduce corruptions (i.e., noise) into text and subsequently fine-tune compact editors to denoise the corruptions by incorporating relevant evidence. Our methodology is entirely unsupervised and provides us with faux hallucinations for training in any domain. Our Petite Unsupervised Research and Revision model, PURR, not only improves attribution over existing editing methods based on fine-tuning and prompting, but also achieves faster execution times by orders of magnitude.
Dr.ICL: Demonstration-Retrieved In-context Learning
May 23, 2023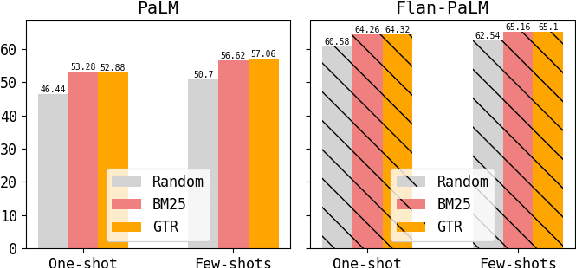
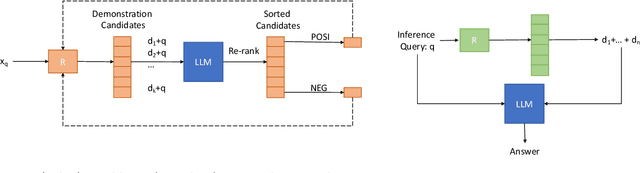
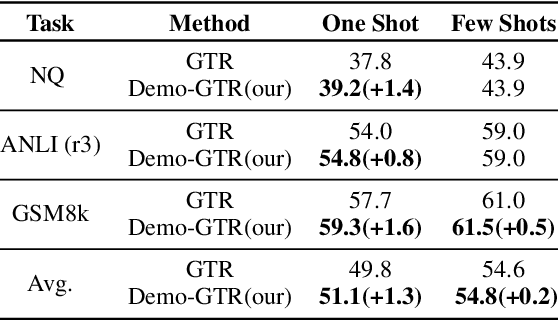
In-context learning (ICL), teaching a large language model (LLM) to perform a task with few-shot demonstrations rather than adjusting the model parameters, has emerged as a strong paradigm for using LLMs. While early studies primarily used a fixed or random set of demonstrations for all test queries, recent research suggests that retrieving semantically similar demonstrations to the input from a pool of available demonstrations results in better performance. This work expands the applicability of retrieval-based ICL approaches by demonstrating that even simple word-overlap similarity measures such as BM25 outperform randomly selected demonstrations. Furthermore, we extend the success of retrieval-based ICL to instruction-finetuned LLMs as well as Chain-of-Thought (CoT) prompting. For instruction-finetuned LLMs, we find that although a model has already seen the training data at training time, retrieving demonstrations from the training data at test time yields better results compared to using no demonstrations or random demonstrations. Last but not least, we train a task-specific demonstration retriever that outperforms off-the-shelf retrievers.
Meta-Learning Fast Weight Language Models
Dec 05, 2022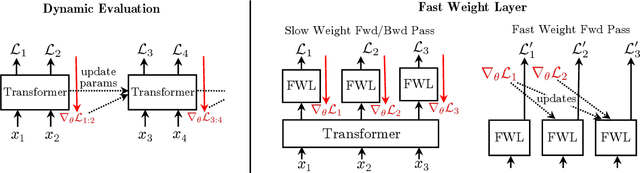
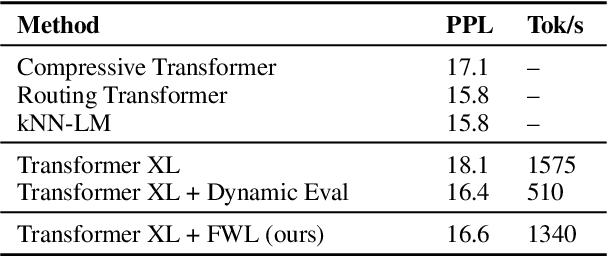
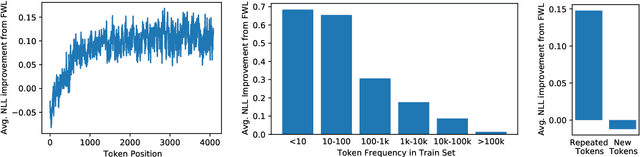
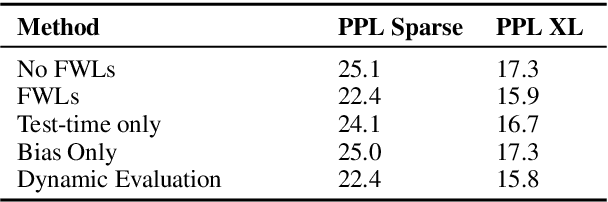
Dynamic evaluation of language models (LMs) adapts model parameters at test time using gradient information from previous tokens and substantially improves LM performance. However, it requires over 3x more compute than standard inference. We present Fast Weight Layers (FWLs), a neural component that provides the benefits of dynamic evaluation much more efficiently by expressing gradient updates as linear attention. A key improvement over dynamic evaluation is that FWLs can also be applied at training time so the model learns to make good use of gradient updates. FWLs can easily be added on top of existing transformer models, require relatively little extra compute or memory to run, and significantly improve language modeling perplexity.
Attributed Text Generation via Post-hoc Research and Revision
Oct 17, 2022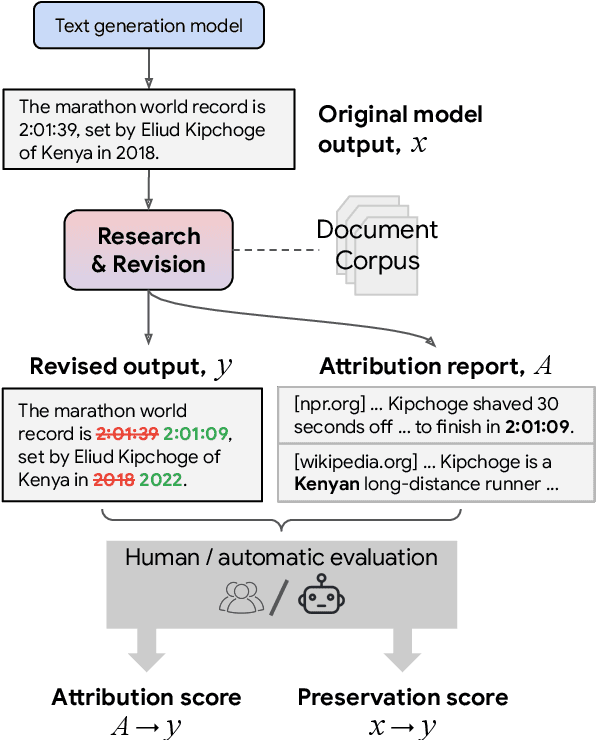
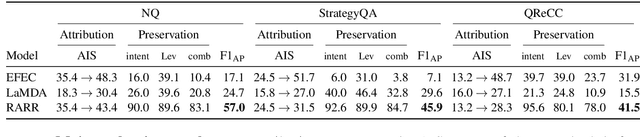
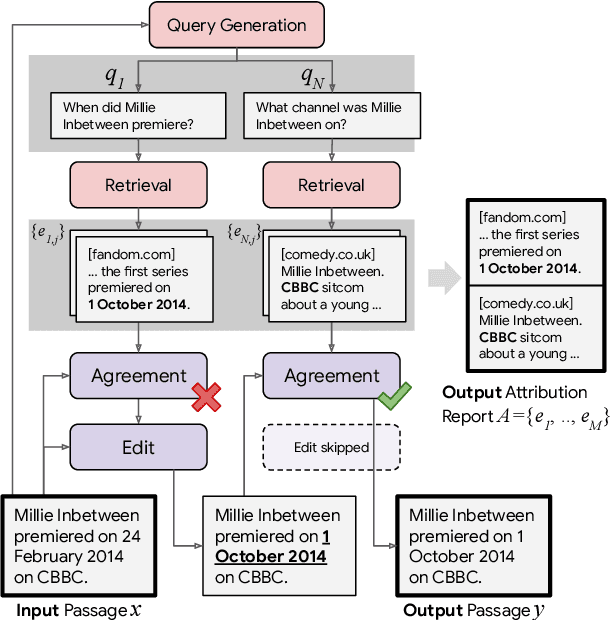
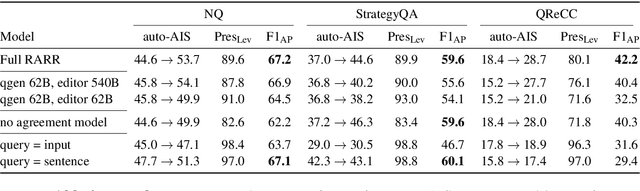
Language models (LMs) now excel at many tasks such as few-shot learning, question answering, reasoning, and dialog. However, they sometimes generate unsupported or misleading content. A user cannot easily determine whether their outputs are trustworthy or not, because most LMs do not have any built-in mechanism for attribution to external evidence. To enable attribution while still preserving all the powerful advantages of recent generation models, we propose RARR (Retrofit Attribution using Research and Revision), a system that 1) automatically finds attribution for the output of any text generation model and 2) post-edits the output to fix unsupported content while preserving the original output as much as possible. When applied to the output of several state-of-the-art LMs on a diverse set of generation tasks, we find that RARR significantly improves attribution while otherwise preserving the original input to a much greater degree than previously explored edit models. Furthermore, the implementation of RARR requires only a handful of training examples, a large language model, and standard web search.
Generate-and-Retrieve: use your predictions to improve retrieval for semantic parsing
Sep 29, 2022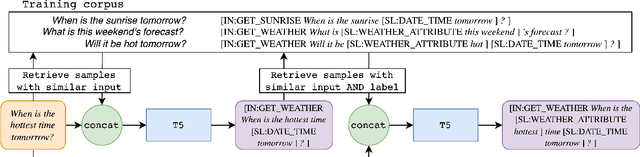
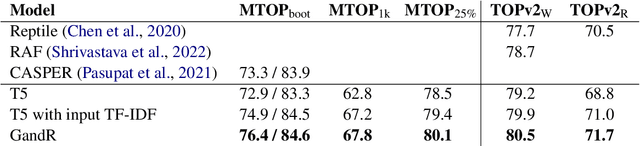
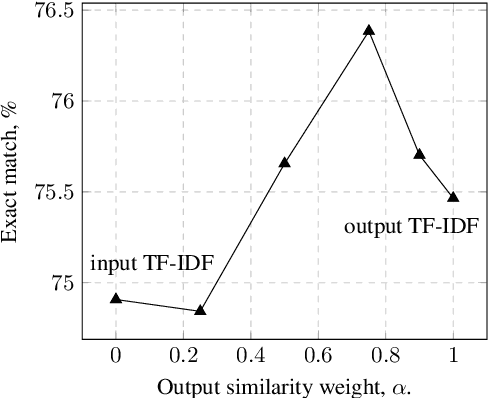
A common recent approach to semantic parsing augments sequence-to-sequence models by retrieving and appending a set of training samples, called exemplars. The effectiveness of this recipe is limited by the ability to retrieve informative exemplars that help produce the correct parse, which is especially challenging in low-resource settings. Existing retrieval is commonly based on similarity of query and exemplar inputs. We propose GandR, a retrieval procedure that retrieves exemplars for which outputs are also similar. GandRfirst generates a preliminary prediction with input-based retrieval. Then, it retrieves exemplars with outputs similar to the preliminary prediction which are used to generate a final prediction. GandR sets the state of the art on multiple low-resource semantic parsing tasks.
Evaluating the Impact of Model Scale for Compositional Generalization in Semantic Parsing
May 24, 2022
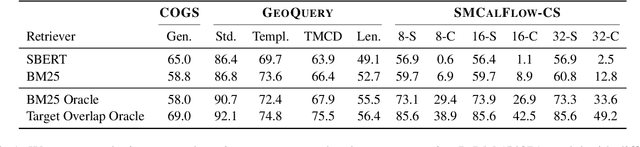
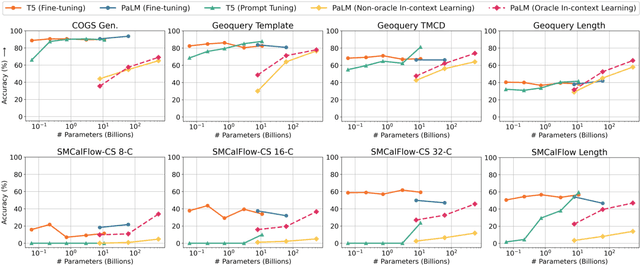
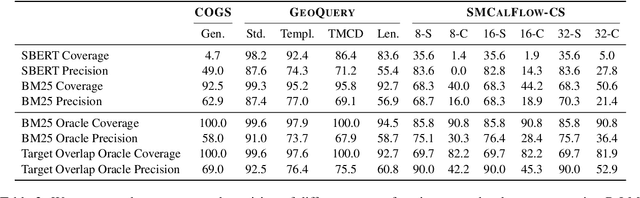
Despite their strong performance on many tasks, pre-trained language models have been shown to struggle on out-of-distribution compositional generalization. Meanwhile, recent work has shown considerable improvements on many NLP tasks from model scaling. Can scaling up model size also improve compositional generalization in semantic parsing? We evaluate encoder-decoder models up to 11B parameters and decoder-only models up to 540B parameters, and compare model scaling curves for three different methods for transfer learning: fine-tuning all parameters, prompt tuning, and in-context learning. We observe that fine-tuning generally has flat or negative scaling curves on out-of-distribution compositional generalization in semantic parsing evaluations. In-context learning has positive scaling curves, but is generally outperformed by much smaller fine-tuned models. Prompt-tuning can outperform fine-tuning, suggesting further potential improvements from scaling as it exhibits a more positive scaling curve. Additionally, we identify several error trends that vary with model scale. For example, larger models are generally better at modeling the syntax of the output space, but are also more prone to certain types of overfitting. Overall, our study highlights limitations of current techniques for effectively leveraging model scale for compositional generalization, while our analysis also suggests promising directions for future work.