 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr.ICL: Demonstration-Retrieved In-context Learning
May 23, 2023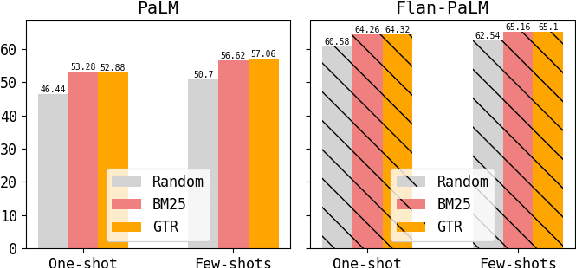
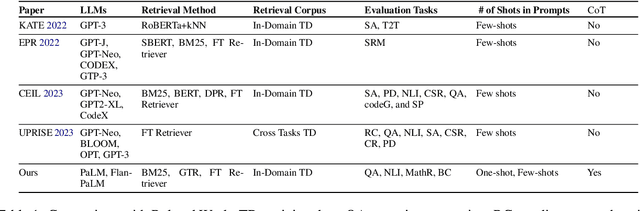
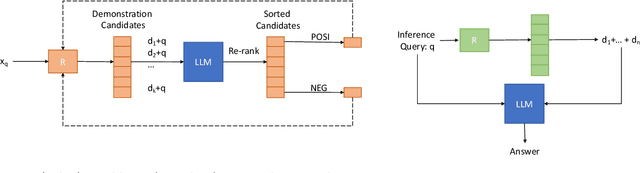
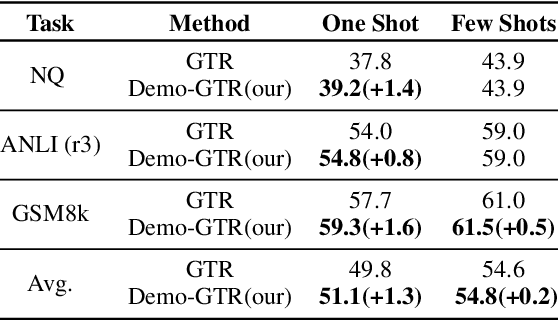
In-context learning (ICL), teaching a large language model (LLM) to perform a task with few-shot demonstrations rather than adjusting the model parameters, has emerged as a strong paradigm for using LLMs. While early studies primarily used a fixed or random set of demonstrations for all test queries, recent research suggests that retrieving semantically similar demonstrations to the input from a pool of available demonstrations results in better performance. This work expands the applicability of retrieval-based ICL approaches by demonstrating that even simple word-overlap similarity measures such as BM25 outperform randomly selected demonstrations. Furthermore, we extend the success of retrieval-based ICL to instruction-finetuned LLMs as well as Chain-of-Thought (CoT) prompting. For instruction-finetuned LLMs, we find that although a model has already seen the training data at training time, retrieving demonstrations from the training data at test time yields better results compared to using no demonstrations or random demonstrations. Last but not least, we train a task-specific demonstration retriever that outperforms off-the-shelf retrievers.