 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaskLAMA: Probing the Complex Task Understanding of Language Models
Aug 29, 2023Structured Complex Task Decomposition (SCTD) is the problem of breaking down a complex real-world task (such as planning a wedding) into a directed acyclic graph over individual steps that contribute to achieving the task, with edges specifying temporal dependencies between them. SCTD is an important component of assistive planning tools, and a challenge for commonsense reasoning systems. We probe how accurately SCTD can be done with the knowledge extracted from Large Language Models (LLMs). We introduce a high-quality human-annotated dataset for this problem and novel metrics to fairly assess performance of LLMs against several baselines. Our experiments reveal that LLMs are able to decompose complex tasks into individual steps effectively, with a relative improvement of 15% to 280% over the best baseline. We also propose a number of approaches to further improve their performance, with a relative improvement of 7% to 37% over the base model. However, we find that LLMs still struggle to predict pairwise temporal dependencies, which reveals a gap in their understanding of complex tasks.
BoardgameQA: A Dataset for Natural Language Reasoning with Contradictory Information
Jun 13, 2023Automated reasoning with unstructured natural text is a key requirement for many potential applications of NLP and for developing robust AI systems. Recently, Language Models (LMs) have demonstrated complex reasoning capacities even without any finetuning. However, existing evaluation for automated reasoning assumes access to a consistent and coherent set of information over which models reason. When reasoning in the real-world, the available information is frequently inconsistent or contradictory, and therefore models need to be equipped with a strategy to resolve such conflicts when they arise. One widely-applicable way of resolving conflicts is to impose preferences over information sources (e.g., based on source credibility or information recency) and adopt the source with higher preference. In this paper, we formulate the problem of reasoning with contradictory information guided by preferences over sources as the classical problem of defeasible reasoning, and develop a dataset called BoardgameQA for measuring the reasoning capacity of LMs in this setting. BoardgameQA also incorporates reasoning with implicit background knowledge, to better reflect reasoning problems in downstream applications. We benchmark various LMs on BoardgameQA and the results reveal a significant gap in the reasoning capacity of state-of-the-art LMs on this problem, showing that reasoning with conflicting information does not surface out-of-the-box in LMs. While performance can be improved with finetuning, it nevertheless remains poor.
Dr.ICL: Demonstration-Retrieved In-context Learning
May 23, 2023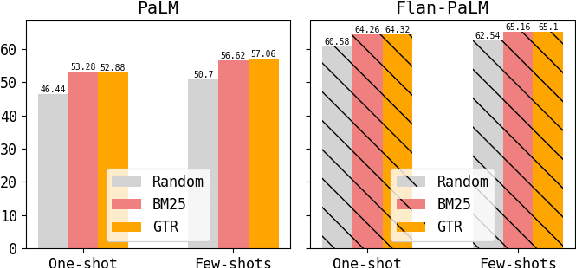
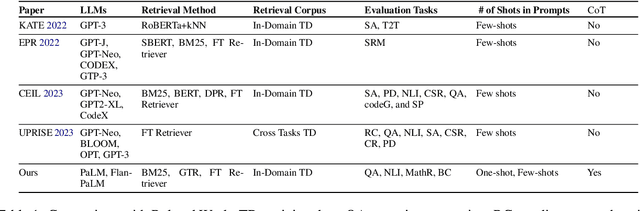
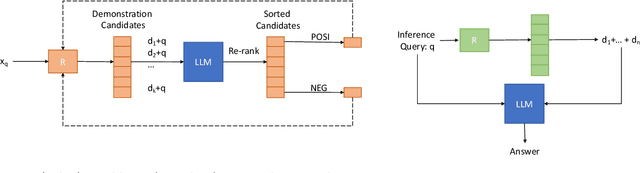
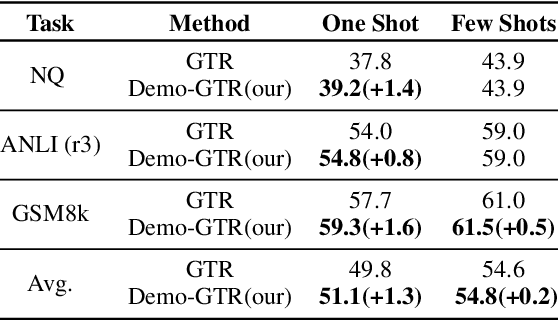
In-context learning (ICL), teaching a large language model (LLM) to perform a task with few-shot demonstrations rather than adjusting the model parameters, has emerged as a strong paradigm for using LLMs. While early studies primarily used a fixed or random set of demonstrations for all test queries, recent research suggests that retrieving semantically similar demonstrations to the input from a pool of available demonstrations results in better performance. This work expands the applicability of retrieval-based ICL approaches by demonstrating that even simple word-overlap similarity measures such as BM25 outperform randomly selected demonstrations. Furthermore, we extend the success of retrieval-based ICL to instruction-finetuned LLMs as well as Chain-of-Thought (CoT) prompting. For instruction-finetuned LLMs, we find that although a model has already seen the training data at training time, retrieving demonstrations from the training data at test time yields better results compared to using no demonstrations or random demonstrations. Last but not least, we train a task-specific demonstration retriever that outperforms off-the-shelf retrievers.