 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Kolmogorov Complexity and Deep Learning: Asymptotically Optimal Description Length Objectives for Transformers
Sep 26, 2025



The Minimum Description Length (MDL) principle offers a formal framework for applying Occam's razor in machine learning. However, its application to neural networks such as Transformers is challenging due to the lack of a principled, universal measure for model complexity. This paper introduces the theoretical notion of asymptotically optimal description length objectives, grounded in the theory of Kolmogorov complexity. We establish that a minimizer of such an objective achieves optimal compression, for any dataset, up to an additive constant, in the limit as model resource bounds increase. We prove that asymptotically optimal objectives exist for Transformers, building on a new demonstration of their computational universality. We further show that such objectives can be tractable and differentiable by constructing and analyzing a variational objective based on an adaptive Gaussian mixture prior. Our empirical analysis shows that this variational objective selects for a low-complexity solution with strong generalization on an algorithmic task, but standard optimizers fail to find such solutions from a random initialization, highlighting key optimization challenges. More broadly, by providing a theoretical framework for identifying description length objectives with strong asymptotic guarantees, we outline a potential path towards training neural networks that achieve greater compression and generalization.
Optimizing Pre-Training Data Mixtures with Mixtures of Data Expert Models
Feb 21, 2025We propose a method to optimize language model pre-training data mixtures through efficient approximation of the cross-entropy loss corresponding to each candidate mixture via a Mixture of Data Experts (MDE). We use this approximation as a source of additional features in a regression model, trained from observations of model loss for a small number of mixtures. Experiments with Transformer decoder-only language models in the range of 70M to 1B parameters on the SlimPajama dataset show that our method achieves significantly better performance than approaches that train regression models using only the mixture rates as input features. Combining this improved optimization method with an objective that takes into account cross-entropy on end task data leads to superior performance on few-shot downstream evaluations. We also provide theoretical insights on why aggregation of data expert predictions can provide good approximations to model losses for data mixtures.
BgGPT 1.0: Extending English-centric LLMs to other languages
Dec 14, 2024We present BgGPT-Gemma-2-27B-Instruct and BgGPT-Gemma-2-9B-Instruct: continually pretrained and fine-tuned versions of Google's Gemma-2 models, specifically optimized for Bulgarian language understanding and generation. Leveraging Gemma-2's multilingual capabilities and over 100 billion tokens of Bulgarian and English text data, our models demonstrate strong performance in Bulgarian language tasks, setting a new standard for language-specific AI models. Our approach maintains the robust capabilities of the original Gemma-2 models, ensuring that the English language performance remains intact. To preserve the base model capabilities, we incorporate continual learning strategies based on recent Branch-and-Merge techniques as well as thorough curation and selection of training data. We provide detailed insights into our methodology, including the release of model weights with a commercial-friendly license, enabling broader adoption by researchers, companies, and hobbyists. Further, we establish a comprehensive set of benchmarks based on non-public educational data sources to evaluate models on Bulgarian language tasks as well as safety and chat capabilities. Our findings demonstrate the effectiveness of fine-tuning state-of-the-art models like Gemma 2 to enhance language-specific AI applications while maintaining cross-lingual capabilities.
Understanding the World's Museums through Vision-Language Reasoning
Dec 02, 2024



Museums serve as vital repositories of cultural heritage and historical artifacts spanning diverse epochs, civilizations, and regions, preserving well-documented collections. Data reveal key attributes such as age, origin, material, and cultural significance. Understanding museum exhibits from their images requires reasoning beyond visual features. In this work, we facilitate such reasoning by (a) collecting and curating a large-scale dataset of 65M images and 200M question-answer pairs in the standard museum catalog format for exhibits from all around the world; (b) training large vision-language models on the collected dataset; (c) benchmarking their ability on five visual question answering tasks. The complete dataset is labeled by museum experts, ensuring the quality as well as the practical significance of the labels. We train two VLMs from different categories: the BLIP model, with vision-language aligned embeddings, but lacking the expressive power of large language models, and the LLaVA model, a powerful instruction-tuned LLM enriched with vision-language reasoning capabilities. Through exhaustive experiments, we provide several insights on the complex and fine-grained understanding of museum exhibits. In particular, we show that some questions whose answers can often be derived directly from visual features are well answered by both types of models. On the other hand, questions that require the grounding of the visual features in repositories of human knowledge are better answered by the large vision-language models, thus demonstrating their superior capacity to perform the desired reasoning. Find our dataset, benchmarks, and source code at: https://github.com/insait-institute/Museum-65
ALTA: Compiler-Based Analysis of Transformers
Oct 23, 2024
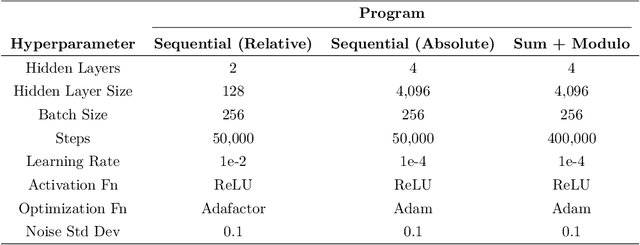

We propose a new programming language called ALTA and a compiler that can map ALTA programs to Transformer weights. ALTA is inspired by RASP, a language proposed by Weiss et al. (2021), and Tracr (Lindner et al., 2023), a compiler from RASP programs to Transformer weights. ALTA complements and extends this prior work, offering the ability to express loops and to compile programs to Universal Transformers, among other advantages. ALTA allows us to constructively show how Transformers can represent length-invariant algorithms for computing parity and addition, as well as a solution to the SCAN benchmark of compositional generalization tasks, without requiring intermediate scratchpad decoding steps. We also propose tools to analyze cases where the expressibility of an algorithm is established, but end-to-end training on a given training set fails to induce behavior consistent with the desired algorithm. To this end, we explore training from ALTA execution traces as a more fine-grained supervision signal. This enables additional experiments and theoretical analyses relating the learnability of various algorithms to data availability and modeling decisions, such as positional encodings. We make the ALTA framework -- language specification, symbolic interpreter, and weight compiler -- available to the community to enable further applications and insights.
Taming CLIP for Fine-grained and Structured Visual Understanding of Museum Exhibits
Sep 03, 2024CLIP is a powerful and widely used tool for understanding images in the context of natural language descriptions to perform nuanced tasks. However, it does not offer application-specific fine-grained and structured understanding, due to its generic nature. In this work, we aim to adapt CLIP for fine-grained and structured -- in the form of tabular data -- visual understanding of museum exhibits. To facilitate such understanding we (a) collect, curate, and benchmark a dataset of 200K+ image-table pairs, and (b) develop a method that allows predicting tabular outputs for input images. Our dataset is the first of its kind in the public domain. At the same time, the proposed method is novel in leveraging CLIP's powerful representations for fine-grained and tabular understanding. The proposed method (MUZE) learns to map CLIP's image embeddings to the tabular structure by means of a proposed transformer-based parsing network (parseNet). More specifically, parseNet enables prediction of missing attribute values while integrating context from known attribute-value pairs for an input image. We show that this leads to significant improvement in accuracy. Through exhaustive experiments, we show the effectiveness of the proposed method on fine-grained and structured understanding of museum exhibits, by achieving encouraging results in a newly established benchmark. Our dataset and source-code can be found at: https://github.com/insait-institute/MUZE
Efficient End-to-End Visual Document Understanding with Rationale Distillation
Nov 16, 2023



Understanding visually situated language requires recognizing text and visual elements, and interpreting complex layouts. State-of-the-art methods commonly use specialized pre-processing tools, such as optical character recognition (OCR) systems, that map document image inputs to extracted information in the space of textual tokens, and sometimes also employ large language models (LLMs) to reason in text token space. However, the gains from external tools and LLMs come at the cost of increased computational and engineering complexity. In this paper, we ask whether small pretrained image-to-text models can learn selective text or layout recognition and reasoning as an intermediate inference step in an end-to-end model for pixel-level visual language understanding. We incorporate the outputs of such OCR tools, LLMs, and larger multimodal models as intermediate ``rationales'' on training data, and train a small student model to predict both rationales and answers for input questions based on those training examples. A student model based on Pix2Struct (282M parameters) achieves consistent improvements on three visual document understanding benchmarks representing infographics, scanned documents, and figures, with improvements of more than 4\% absolute over a comparable Pix2Struct model that predicts answers directly.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023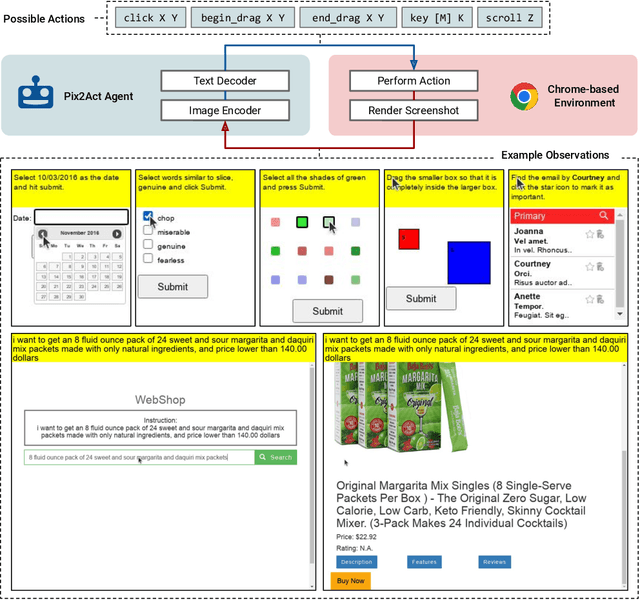
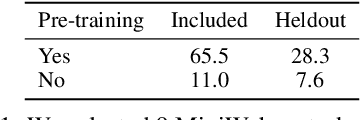
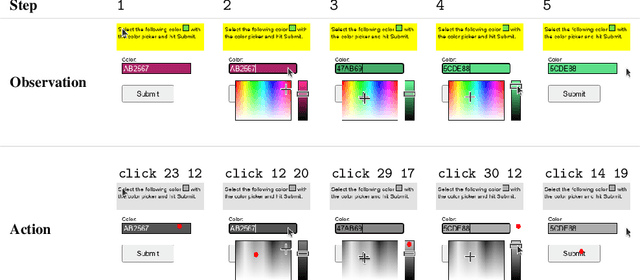
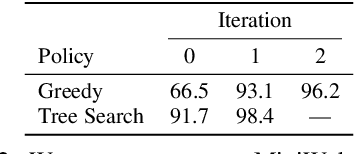
Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
Anchor Prediction: Automatic Refinement of Internet Links
May 24, 2023Internet links enable users to deepen their understanding of a topic by providing convenient access to related information. However, the majority of links are unanchored -- they link to a target webpage as a whole, and readers may expend considerable effort localizing the specific parts of the target webpage that enrich their understanding of the link's source context. To help readers effectively find information in linked webpages, we introduce the task of anchor prediction, where the goal is to identify the specific part of the linked target webpage that is most related to the source linking context. We release the AuthorAnchors dataset, a collection of 34K naturally-occurring anchored links, which reflect relevance judgments by the authors of the source article. To model reader relevance judgments, we annotate and release ReaderAnchors, an evaluation set of anchors that readers find useful. Our analysis shows that effective anchor prediction often requires jointly reasoning over lengthy source and target webpages to determine their implicit relations and identify parts of the target webpage that are related but not redundant. We benchmark a performant T5-based ranking approach to establish baseline performance on the task, finding ample room for improvement.
QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations
May 19, 2023



Formulating selective information needs results in queries that implicitly specify set operations, such as intersection, union, and difference. For instance, one might search for "shorebirds that are not sandpipers" or "science-fiction films shot in England". To study the ability of retrieval systems to meet such information needs, we construct QUEST, a dataset of 3357 natural language queries with implicit set operations, that map to a set of entities corresponding to Wikipedia documents. The dataset challenges models to match multiple constraints mentioned in queries with corresponding evidence in documents and correctly perform various set operations. The dataset is constructed semi-automatically using Wikipedia category names. Queries are automatically composed from individual categories, then paraphrased and further validated for naturalness and fluency by crowdworkers. Crowdworkers also assess the relevance of entities based on their documents and highlight attribution of query constraints to spans of document text. We analyze several modern retrieval systems, finding that they often struggle on such queries. Queries involving negation and conjunction are particularly challenging and systems are further challenged with combinations of these operations.