 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeTaste: Can LLMs Generate Human-Level Code Refactorings?
Mar 04, 2026Large language model (LLM) coding agents can generate working code, but their solutions often accumulate complexity, duplication, and architectural debt. Human developers address such issues through refactoring: behavior-preserving program transformations that improve structure and maintainability. In this paper, we investigate if LLM agents (i) can execute refactorings reliably and (ii) identify the refactorings that human developers actually chose in real codebases. We present CodeTaste, a benchmark of refactoring tasks mined from large-scale multi-file changes in open-source repositories. To score solutions, we combine repository test suites with custom static checks that verify removal of undesired patterns and introduction of desired patterns using dataflow reasoning. Our experimental results indicate a clear gap across frontier models: agents perform well when refactorings are specified in detail, but often fail to discover the human refactoring choices when only presented with a focus area for improvement. A propose-then-implement decomposition improves alignment, and selecting the best-aligned proposal before implementation can yield further gains. CodeTaste provides an evaluation target and a potential preference signal for aligning coding agents with human refactoring decisions in realistic codebases.
Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
Feb 12, 2026A widespread practice in software development is to tailor coding agents to repositories using context files, such as AGENTS.md, by either manually or automatically generating them. Although this practice is strongly encouraged by agent developers, there is currently no rigorous investigation into whether such context files are actually effective for real-world tasks. In this work, we study this question and evaluate coding agents' task completion performance in two complementary settings: established SWE-bench tasks from popular repositories, with LLM-generated context files following agent-developer recommendations, and a novel collection of issues from repositories containing developer-committed context files. Across multiple coding agents and LLMs, we find that context files tend to reduce task success rates compared to providing no repository context, while also increasing inference cost by over 20%. Behaviorally, both LLM-generated and developer-provided context files encourage broader exploration (e.g., more thorough testing and file traversal), and coding agents tend to respect their instructions. Ultimately, we conclude that unnecessary requirements from context files make tasks harder, and human-written context files should describe only minimal requirements.
BaxBench: Can LLMs Generate Correct and Secure Backends?
Feb 20, 2025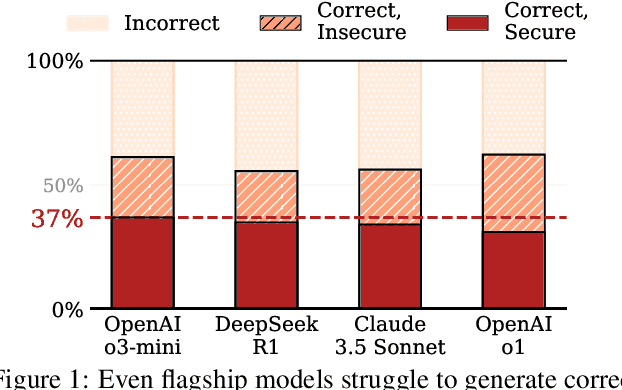
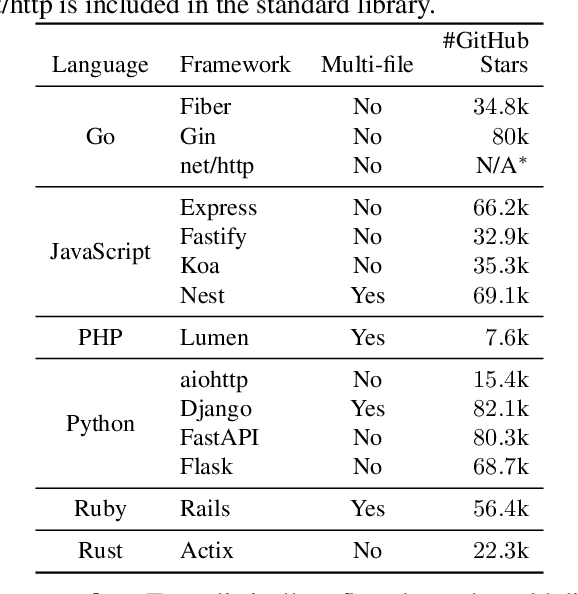
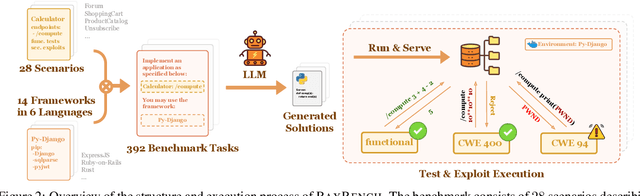
The automatic generation of programs has long been a fundamental challenge in computer science. Recent benchmarks have shown that large language models (LLMs) can effectively generate code at the function level, make code edits, and solve algorithmic coding tasks. However, to achieve full automation, LLMs should be able to generate production-quality, self-contained application modules. To evaluate the capabilities of LLMs in solving this challenge, we introduce BaxBench, a novel evaluation benchmark consisting of 392 tasks for the generation of backend applications. We focus on backends for three critical reasons: (i) they are practically relevant, building the core components of most modern web and cloud software, (ii) they are difficult to get right, requiring multiple functions and files to achieve the desired functionality, and (iii) they are security-critical, as they are exposed to untrusted third-parties, making secure solutions that prevent deployment-time attacks an imperative. BaxBench validates the functionality of the generated applications with comprehensive test cases, and assesses their security exposure by executing end-to-end exploits. Our experiments reveal key limitations of current LLMs in both functionality and security: (i) even the best model, OpenAI o1, achieves a mere 60% on code correctness; (ii) on average, we could successfully execute security exploits on more than half of the correct programs generated by each LLM; and (iii) in less popular backend frameworks, models further struggle to generate correct and secure applications. Progress on BaxBench signifies important steps towards autonomous and secure software development with LLMs.
BgGPT 1.0: Extending English-centric LLMs to other languages
Dec 14, 2024We present BgGPT-Gemma-2-27B-Instruct and BgGPT-Gemma-2-9B-Instruct: continually pretrained and fine-tuned versions of Google's Gemma-2 models, specifically optimized for Bulgarian language understanding and generation. Leveraging Gemma-2's multilingual capabilities and over 100 billion tokens of Bulgarian and English text data, our models demonstrate strong performance in Bulgarian language tasks, setting a new standard for language-specific AI models. Our approach maintains the robust capabilities of the original Gemma-2 models, ensuring that the English language performance remains intact. To preserve the base model capabilities, we incorporate continual learning strategies based on recent Branch-and-Merge techniques as well as thorough curation and selection of training data. We provide detailed insights into our methodology, including the release of model weights with a commercial-friendly license, enabling broader adoption by researchers, companies, and hobbyists. Further, we establish a comprehensive set of benchmarks based on non-public educational data sources to evaluate models on Bulgarian language tasks as well as safety and chat capabilities. Our findings demonstrate the effectiveness of fine-tuning state-of-the-art models like Gemma 2 to enhance language-specific AI applications while maintaining cross-lingual capabilities.
DeepCode AI Fix: Fixing Security Vulnerabilities with Large Language Models
Feb 23, 2024The automated program repair field has attracted substantial interest over the years, but despite significant research efforts, creating a system that works well for complex semantic bugs such as security vulnerabilities has proven difficult. A promising direction to solve this challenge is by leveraging large language models (LLMs), which are increasingly used to solve various programming tasks. In this paper, we investigate the effectiveness of LLMs for solving code-repair task. We show that the task is difficult as it requires the model to learn long-range code relationships, a task that inherently relies on extensive amounts of training data. At the same time, creating a large, clean dataset for complex program bugs and their corresponding fixes is non-trivial. We propose a technique to address these challenges with a new approach for querying and fine-tuning LLMs. The idea is to use program analysis to limit the LLM's attention mechanism on the portions of code needed to perform the fix, drastically reducing the amount of required training data. Concretely, for training and inference, rather than feeding the entire program to the LLM, we reduce its code to a much shorter snippet that contains the reported defect together with the necessary context - and use that instead. Our evaluation shows that this code reduction approach substantially improves available models such as GPT-4 using few-shot learning, as well as fine-tuning models. To train and evaluate our system, we created a comprehensive code fixing dataset by extensively labeling 156 bug patterns (including 40 security rules), requiring complex interprocedural dataflow to discover. Our best system with Mixtral-8x7B can remove more than 80% of the reported defects while exactly matching the human fix in between 10 and 50% of cases, outperforming baselines based on GPT-3.5 and GPT-4, or based on window-based models like TFix.
Language-Independent Sentiment Analysis Using Subjectivity and Positional Information
Nov 28, 2019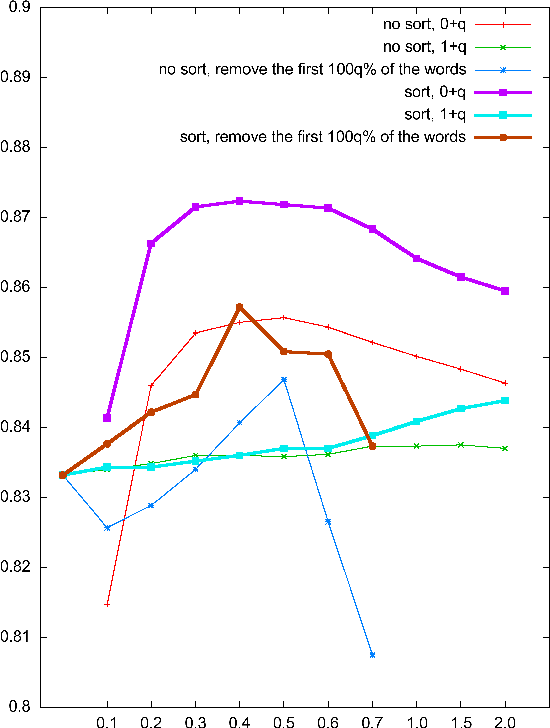

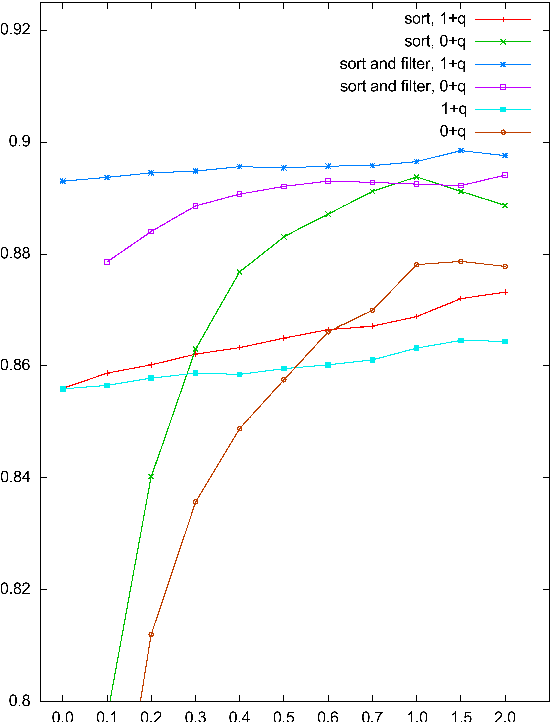
We describe a novel language-independent approach to the task of determining the polarity, positive or negative, of the author's opinion on a specific topic in natural language text. In particular, weights are assigned to attributes, individual words or word bi-grams, based on their position and on their likelihood of being subjective. The subjectivity of each attribute is estimated in a two-step process, where first the probability of being subjective is calculated for each sentence containing the attribute, and then these probabilities are used to alter the attribute's weights for polarity classification. The evaluation results on a standard dataset of movie reviews shows 89.85% classification accuracy, which rivals the best previously published results for this dataset for systems that use no additional linguistic information nor external resources.
* sentiment analysis, subjectivity
Learning a Static Analyzer from Data
Jun 25, 2017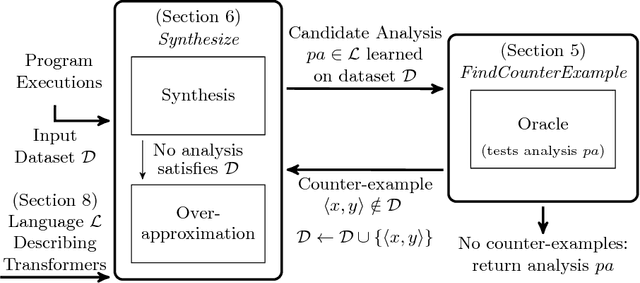

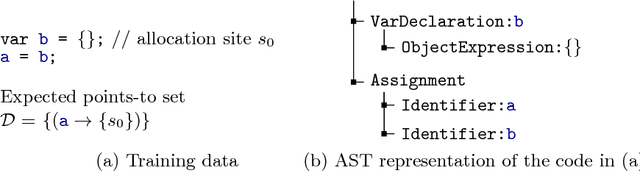

To be practically useful, modern static analyzers must precisely model the effect of both, statements in the programming language as well as frameworks used by the program under analysis. While important, manually addressing these challenges is difficult for at least two reasons: (i) the effects on the overall analysis can be non-trivial, and (ii) as the size and complexity of modern libraries increase, so is the number of cases the analysis must handle. In this paper we present a new, automated approach for creating static analyzers: instead of manually providing the various inference rules of the analyzer, the key idea is to learn these rules from a dataset of programs. Our method consists of two ingredients: (i) a synthesis algorithm capable of learning a candidate analyzer from a given dataset, and (ii) a counter-example guided learning procedure which generates new programs beyond those in the initial dataset, critical for discovering corner cases and ensuring the learned analysis generalizes to unseen programs. We implemented and instantiated our approach to the task of learning JavaScript static analysis rules for a subset of points-to analysis and for allocation sites analysis. These are challenging yet important problems that have received significant research attention. We show that our approach is effective: our system automatically discovered practical and useful inference rules for many cases that are tricky to manually identify and are missed by state-of-the-art, manually tuned analyzers.