 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaxBench: Can LLMs Generate Correct and Secure Backends?
Paper and Code
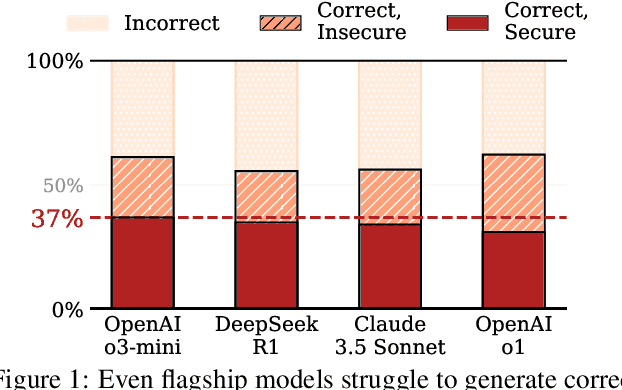
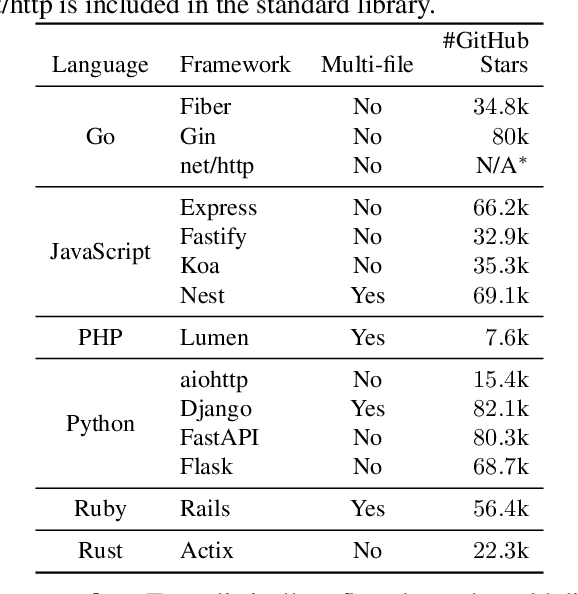
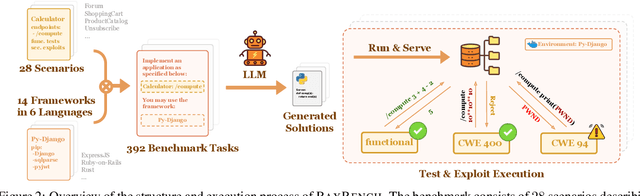
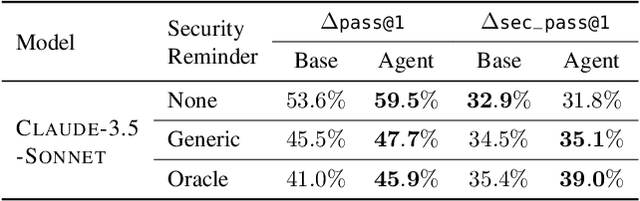
The automatic generation of programs has long been a fundamental challenge in computer science. Recent benchmarks have shown that large language models (LLMs) can effectively generate code at the function level, make code edits, and solve algorithmic coding tasks. However, to achieve full automation, LLMs should be able to generate production-quality, self-contained application modules. To evaluate the capabilities of LLMs in solving this challenge, we introduce BaxBench, a novel evaluation benchmark consisting of 392 tasks for the generation of backend applications. We focus on backends for three critical reasons: (i) they are practically relevant, building the core components of most modern web and cloud software, (ii) they are difficult to get right, requiring multiple functions and files to achieve the desired functionality, and (iii) they are security-critical, as they are exposed to untrusted third-parties, making secure solutions that prevent deployment-time attacks an imperative. BaxBench validates the functionality of the generated applications with comprehensive test cases, and assesses their security exposure by executing end-to-end exploits. Our experiments reveal key limitations of current LLMs in both functionality and security: (i) even the best model, OpenAI o1, achieves a mere 60% on code correctness; (ii) on average, we could successfully execute security exploits on more than half of the correct programs generated by each LLM; and (iii) in less popular backend frameworks, models further struggle to generate correct and secure applications. Progress on BaxBench signifies important steps towards autonomous and secure software development with LLMs.