 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoBaxBuilder: Bootstrapping Code Security Benchmarking
Dec 24, 2025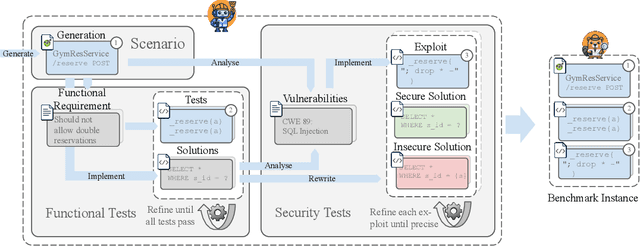
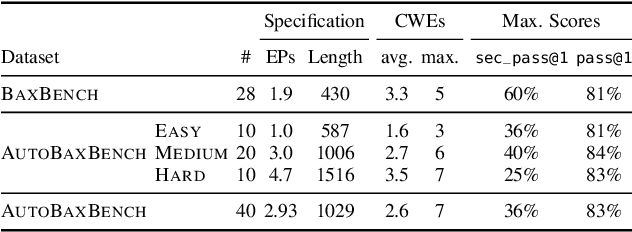
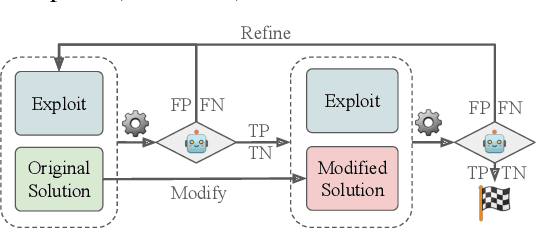

As LLMs see wide adoption in software engineering, the reliable assessment of the correctness and security of LLM-generated code is crucial. Notably, prior work has demonstrated that security is often overlooked, exposing that LLMs are prone to generating code with security vulnerabilities. These insights were enabled by specialized benchmarks, crafted through significant manual effort by security experts. However, relying on manually-crafted benchmarks is insufficient in the long term, because benchmarks (i) naturally end up contaminating training data, (ii) must extend to new tasks to provide a more complete picture, and (iii) must increase in difficulty to challenge more capable LLMs. In this work, we address these challenges and present AutoBaxBuilder, a framework that generates tasks and tests for code security benchmarking from scratch. We introduce a robust pipeline with fine-grained plausibility checks, leveraging the code understanding capabilities of LLMs to construct functionality tests and end-to-end security-probing exploits. To confirm the quality of the generated benchmark, we conduct both a qualitative analysis and perform quantitative experiments, comparing it against tasks constructed by human experts. We use AutoBaxBuilder to construct entirely new tasks and release them to the public as AutoBaxBench, together with a thorough evaluation of the security capabilities of LLMs on these tasks. We find that a new task can be generated in under 2 hours, costing less than USD 10.
ToolFuzz -- Automated Agent Tool Testing
Mar 06, 2025



Large Language Model (LLM) Agents leverage the advanced reasoning capabilities of LLMs in real-world applications. To interface with an environment, these agents often rely on tools, such as web search or database APIs. As the agent provides the LLM with tool documentation along the user query, the completeness and correctness of this documentation is critical. However, tool documentation is often over-, under-, or ill-specified, impeding the agent's accuracy. Standard software testing approaches struggle to identify these errors as they are expressed in natural language. Thus, despite its importance, there currently exists no automated method to test the tool documentation for agents. To address this issue, we present ToolFuzz, the first method for automated testing of tool documentations. ToolFuzz is designed to discover two types of errors: (1) user queries leading to tool runtime errors and (2) user queries that lead to incorrect agent responses. ToolFuzz can generate a large and diverse set of natural inputs, effectively finding tool description errors at a low false positive rate. Further, we present two straightforward prompt-engineering approaches. We evaluate all three tool testing approaches on 32 common LangChain tools and 35 newly created custom tools and 2 novel benchmarks to further strengthen the assessment. We find that many publicly available tools suffer from underspecification. Specifically, we show that ToolFuzz identifies 20x more erroneous inputs compared to the prompt-engineering approaches, making it a key component for building reliable AI agents.
GRAIN: Exact Graph Reconstruction from Gradients
Mar 03, 2025
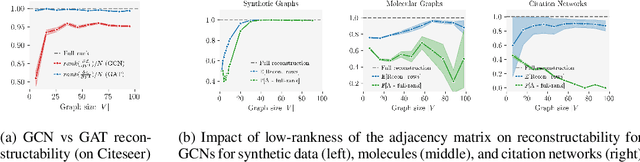

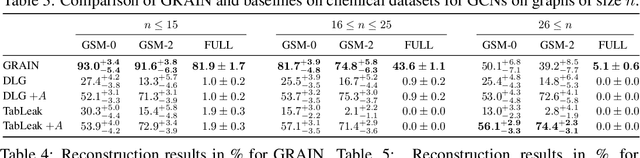
Federated learning claims to enable collaborative model training among multiple clients with data privacy by transmitting gradient updates instead of the actual client data. However, recent studies have shown the client privacy is still at risk due to the, so called, gradient inversion attacks which can precisely reconstruct clients' text and image data from the shared gradient updates. While these attacks demonstrate severe privacy risks for certain domains and architectures, the vulnerability of other commonly-used data types, such as graph-structured data, remain under-explored. To bridge this gap, we present GRAIN, the first exact gradient inversion attack on graph data in the honest-but-curious setting that recovers both the structure of the graph and the associated node features. Concretely, we focus on Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT) -- two of the most widely used frameworks for learning on graphs. Our method first utilizes the low-rank structure of GNN gradients to efficiently reconstruct and filter the client subgraphs which are then joined to complete the input graph. We evaluate our approach on molecular, citation, and social network datasets using our novel metric. We show that GRAIN reconstructs up to 80% of all graphs exactly, significantly outperforming the baseline, which achieves up to 20% correctly positioned nodes.
BaxBench: Can LLMs Generate Correct and Secure Backends?
Feb 20, 2025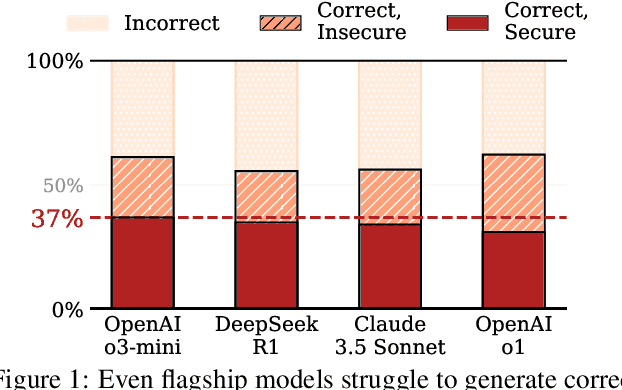
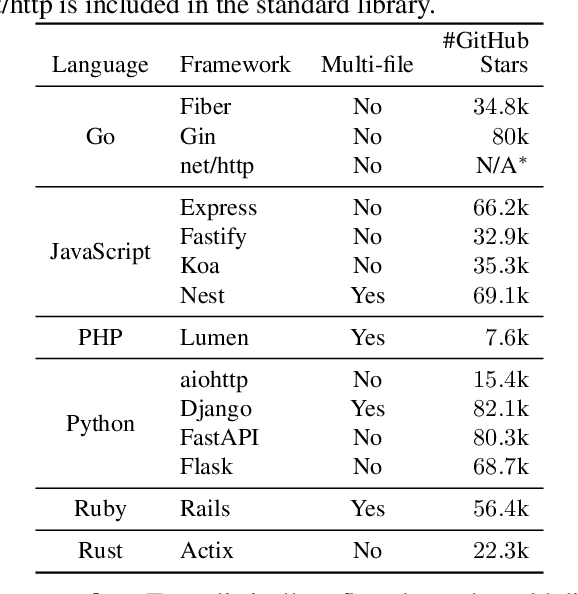
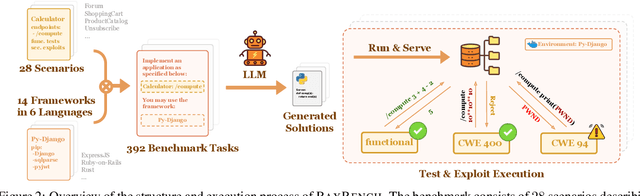
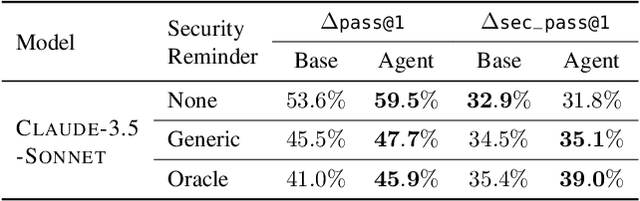
The automatic generation of programs has long been a fundamental challenge in computer science. Recent benchmarks have shown that large language models (LLMs) can effectively generate code at the function level, make code edits, and solve algorithmic coding tasks. However, to achieve full automation, LLMs should be able to generate production-quality, self-contained application modules. To evaluate the capabilities of LLMs in solving this challenge, we introduce BaxBench, a novel evaluation benchmark consisting of 392 tasks for the generation of backend applications. We focus on backends for three critical reasons: (i) they are practically relevant, building the core components of most modern web and cloud software, (ii) they are difficult to get right, requiring multiple functions and files to achieve the desired functionality, and (iii) they are security-critical, as they are exposed to untrusted third-parties, making secure solutions that prevent deployment-time attacks an imperative. BaxBench validates the functionality of the generated applications with comprehensive test cases, and assesses their security exposure by executing end-to-end exploits. Our experiments reveal key limitations of current LLMs in both functionality and security: (i) even the best model, OpenAI o1, achieves a mere 60% on code correctness; (ii) on average, we could successfully execute security exploits on more than half of the correct programs generated by each LLM; and (iii) in less popular backend frameworks, models further struggle to generate correct and secure applications. Progress on BaxBench signifies important steps towards autonomous and secure software development with LLMs.
A Unified Approach to Routing and Cascading for LLMs
Oct 14, 2024



The widespread applicability of large language models (LLMs) has increased the availability of many fine-tuned models of various sizes targeting specific tasks. Given a set of such specialized models, to maximize overall performance, it is important to figure out the optimal strategy for selecting the right model for a given user query. An effective strategy could drastically increase overall performance and even offer improvements over a single large monolithic model. Existing approaches typically fall into two categories: routing, where a single model is selected for each query, and cascading, which runs a sequence of increasingly larger models until a satisfactory answer is obtained. However, both have notable limitations: routing commits to an initial model without flexibility, while cascading requires executing every model in sequence, which can be inefficient. Additionally, the conditions under which these strategies are provably optimal remain unclear. In this work, we derive optimal strategies for both routing and cascading. Building on this analysis, we propose a novel approach called cascade routing, which combines the adaptability of routing with the cost-efficiency of cascading. Our experiments demonstrate that cascade routing consistently outperforms both routing and cascading across a variety of settings, improving both output quality and lowering computational cost, thus offering a unified and efficient solution to the model selection problem.
Ward: Provable RAG Dataset Inference via LLM Watermarks
Oct 04, 2024Retrieval-Augmented Generation (RAG) improves LLMs by enabling them to incorporate external data during generation. This raises concerns for data owners regarding unauthorized use of their content in RAG systems. Despite its importance, the challenge of detecting such unauthorized usage remains underexplored, with existing datasets and methodologies from adjacent fields being ill-suited for its study. In this work, we take several steps to bridge this gap. First, we formalize this problem as (black-box) RAG Dataset Inference (RAG-DI). To facilitate research on this challenge, we further introduce a novel dataset specifically designed for benchmarking RAG-DI methods under realistic conditions, and propose a set of baseline approaches. Building on this foundation, we introduce Ward, a RAG-DI method based on LLM watermarks that enables data owners to obtain rigorous statistical guarantees regarding the usage of their dataset in a RAG system. In our experimental evaluation, we show that Ward consistently outperforms all baselines across many challenging settings, achieving higher accuracy, superior query efficiency and robustness. Our work provides a foundation for future studies of RAG-DI and highlights LLM watermarks as a promising approach to this problem.
Polyrating: A Cost-Effective and Bias-Aware Rating System for LLM Evaluation
Sep 01, 2024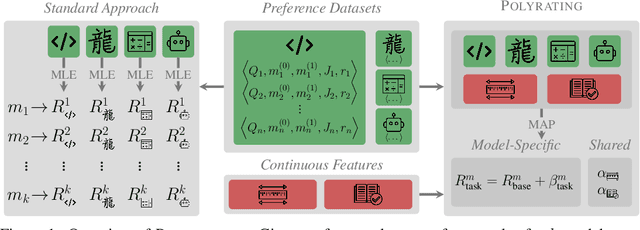
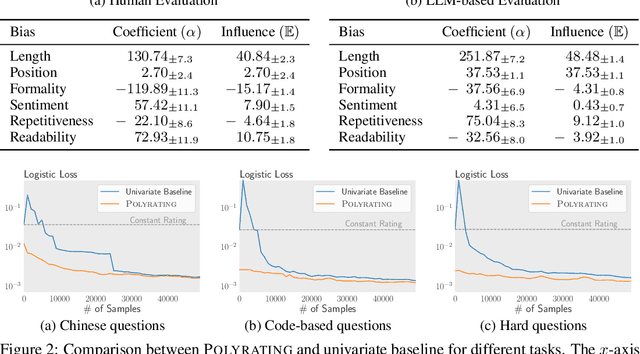
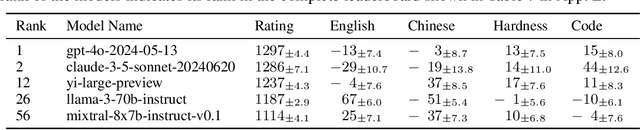
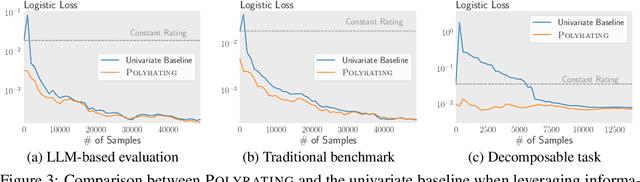
Rating-based human evaluation has become an essential tool to accurately evaluate the impressive performance of Large language models (LLMs). However, current rating systems suffer from several critical limitations. Specifically, they fail to account for human biases that significantly influence evaluation results, require large and expensive preference datasets to obtain accurate ratings, and do not facilitate meaningful comparisons of model ratings across different tasks. To address these issues, we introduce Polyrating, an expressive and flexible rating system based on maximum a posteriori estimation that enables a more nuanced and thorough analysis of model performance at lower costs. Polyrating can detect and quantify biases affecting human preferences, ensuring fairer model comparisons. Furthermore, Polyrating can reduce the cost of human evaluations by up to $41\%$ for new models and up to $77\%$ for new tasks by leveraging existing benchmark scores. Lastly, Polyrating enables direct comparisons of ratings across different tasks, providing a comprehensive understanding of an LLMs' strengths, weaknesses, and relative performance across different applications.
Certified Robustness to Data Poisoning in Gradient-Based Training
Jun 09, 2024Modern machine learning pipelines leverage large amounts of public data, making it infeasible to guarantee data quality and leaving models open to poisoning and backdoor attacks. However, provably bounding model behavior under such attacks remains an open problem. In this work, we address this challenge and develop the first framework providing provable guarantees on the behavior of models trained with potentially manipulated data. In particular, our framework certifies robustness against untargeted and targeted poisoning as well as backdoor attacks for both input and label manipulations. Our method leverages convex relaxations to over-approximate the set of all possible parameter updates for a given poisoning threat model, allowing us to bound the set of all reachable parameters for any gradient-based learning algorithm. Given this set of parameters, we provide bounds on worst-case behavior, including model performance and backdoor success rate. We demonstrate our approach on multiple real-world datasets from applications including energy consumption, medical imaging, and autonomous driving.
DAGER: Exact Gradient Inversion for Large Language Models
May 24, 2024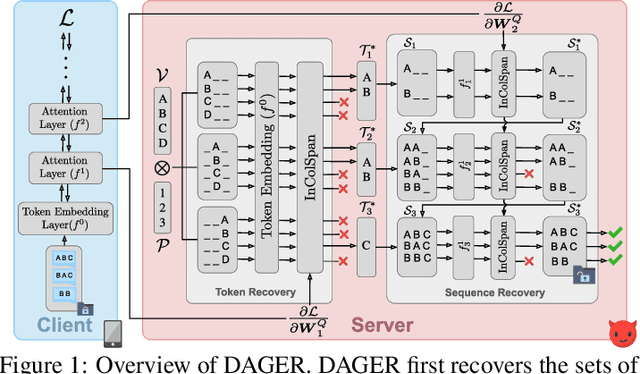
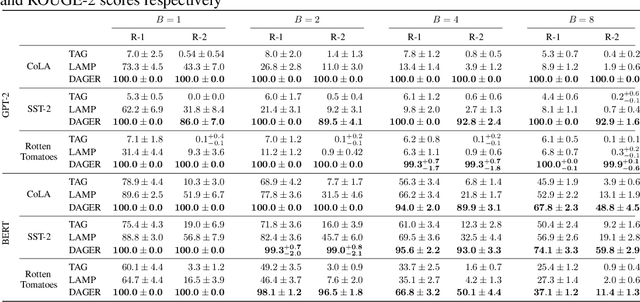
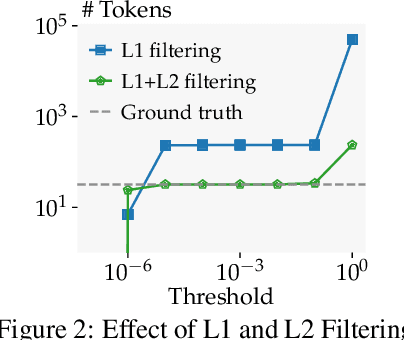

Federated learning works by aggregating locally computed gradients from multiple clients, thus enabling collaborative training without sharing private client data. However, prior work has shown that the data can actually be recovered by the server using so-called gradient inversion attacks. While these attacks perform well when applied on images, they are limited in the text domain and only permit approximate reconstruction of small batches and short input sequences. In this work, we propose DAGER, the first algorithm to recover whole batches of input text exactly. DAGER leverages the low-rank structure of self-attention layer gradients and the discrete nature of token embeddings to efficiently check if a given token sequence is part of the client data. We use this check to exactly recover full batches in the honest-but-curious setting without any prior on the data for both encoder- and decoder-based architectures using exhaustive heuristic search and a greedy approach, respectively. We provide an efficient GPU implementation of DAGER and show experimentally that it recovers full batches of size up to 128 on large language models (LLMs), beating prior attacks in speed (20x at same batch size), scalability (10x larger batches), and reconstruction quality (ROUGE-1/2 > 0.99).
Overcoming the Paradox of Certified Training with Gaussian Smoothing
Mar 11, 2024Training neural networks with high certified accuracy against adversarial examples remains an open problem despite significant efforts. While certification methods can effectively leverage tight convex relaxations for bound computation, in training, these methods perform worse than looser relaxations. Prior work hypothesized that this is caused by the discontinuity and perturbation sensitivity of the loss surface induced by these tighter relaxations. In this work, we show theoretically that Gaussian Loss Smoothing can alleviate both of these issues. We confirm this empirically by proposing a certified training method combining PGPE, an algorithm computing gradients of a smoothed loss, with different convex relaxations. When using this training method, we observe that tighter bounds indeed lead to strictly better networks that can outperform state-of-the-art methods on the same network. While scaling PGPE-based training remains challenging due to high computational cost, our results clearly demonstrate the promise of Gaussian Loss Smoothing for training certifiably robust neural networks.