 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyrating: A Cost-Effective and Bias-Aware Rating System for LLM Evaluation
Paper and Code
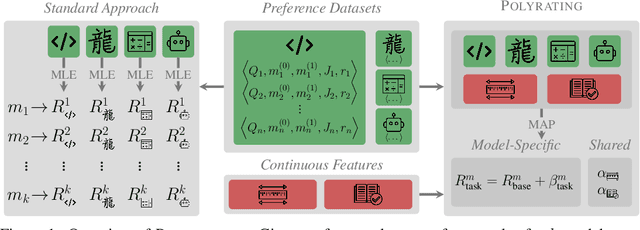
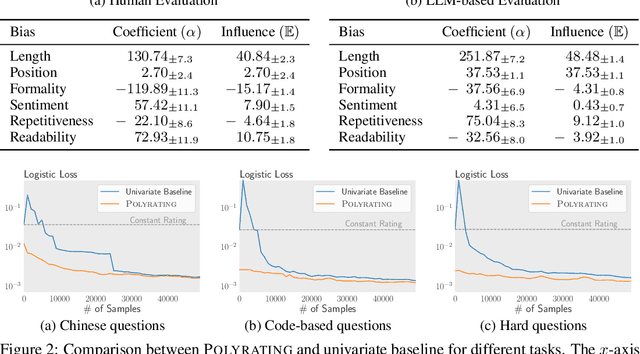
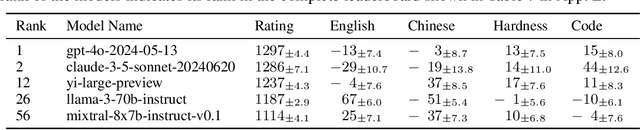
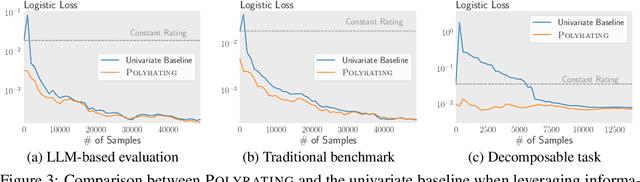
Rating-based human evaluation has become an essential tool to accurately evaluate the impressive performance of Large language models (LLMs). However, current rating systems suffer from several critical limitations. Specifically, they fail to account for human biases that significantly influence evaluation results, require large and expensive preference datasets to obtain accurate ratings, and do not facilitate meaningful comparisons of model ratings across different tasks. To address these issues, we introduce Polyrating, an expressive and flexible rating system based on maximum a posteriori estimation that enables a more nuanced and thorough analysis of model performance at lower costs. Polyrating can detect and quantify biases affecting human preferences, ensuring fairer model comparisons. Furthermore, Polyrating can reduce the cost of human evaluations by up to $41\%$ for new models and up to $77\%$ for new tasks by leveraging existing benchmark scores. Lastly, Polyrating enables direct comparisons of ratings across different tasks, providing a comprehensive understanding of an LLMs' strengths, weaknesses, and relative performance across different applications.