 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEAR:Exact Gradient Inversion of Batches in Federated Learning
Paper and Code
Mar 06, 2024
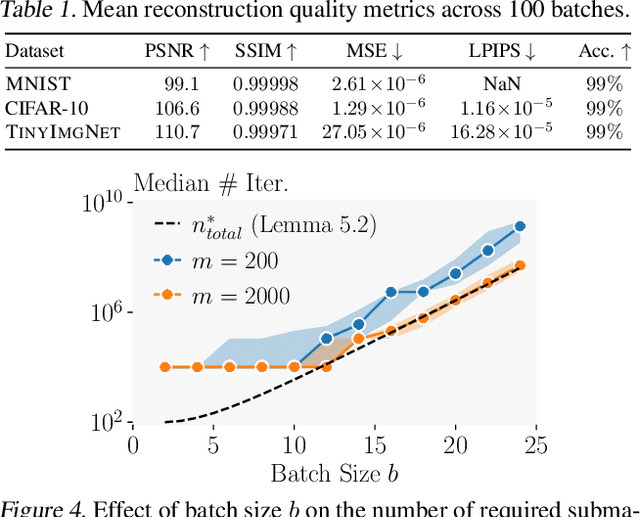
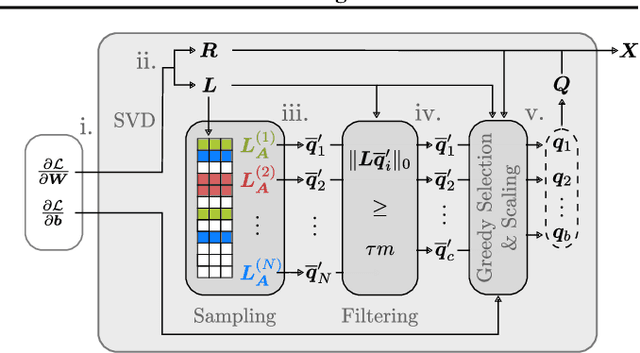

Federated learning is a popular framework for collaborative machine learning where multiple clients only share gradient updates on their local data with the server and not the actual data. Unfortunately, it was recently shown that gradient inversion attacks can reconstruct this data from these shared gradients. Existing attacks enable exact reconstruction only for a batch size of $b=1$ in the important honest-but-curious setting, with larger batches permitting only approximate reconstruction. In this work, we propose \emph{the first algorithm reconstructing whole batches with $b >1$ exactly}. This approach combines mathematical insights into the explicit low-rank structure of gradients with a sampling-based algorithm. Crucially, we leverage ReLU-induced gradient sparsity to precisely filter out large numbers of incorrect samples, making a final reconstruction step tractable. We provide an efficient GPU implementation for fully connected networks and show that it recovers batches of $b \lesssim 25$ elements exactly while being tractable for large network widths and depths.