 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecPI: Secure Code Generation with Reasoning Models via Security Reasoning Internalization
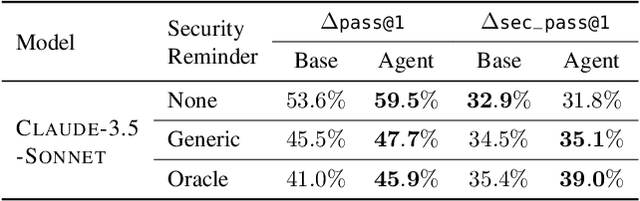
Apr 04, 2026Reasoning language models (RLMs) are increasingly used in programming. Yet, even state-of-the-art RLMs frequently introduce critical security vulnerabilities in generated code. Prior training-based approaches for secure code generation face a critical limitation that prevents their direct application to RLMs: they rely on costly, manually curated security datasets covering only a limited set of vulnerabilities. At the inference level, generic security reminders consistently degrade functional correctness while triggering only shallow ad-hoc vulnerability analysis. To address these problems, we present SecPI, a fine-tuning pipeline that teaches RLMs to internalize structured security reasoning, producing secure code by default without any security instructions at inference time. SecPI filters existing general-purpose coding datasets for security-relevant tasks using an LLM-based classifier, generates high-quality security reasoning traces with a teacher model guided by a structured prompt that systematically enumerates relevant CWEs and mitigations, and fine-tunes the target model on pairs of inputs with no security prompt and teacher reasoning traces -- as a result, the model learns to reason about security autonomously rather than in response to explicit instructions. An extensive evaluation on security benchmarks with state-of-the-art open-weight reasoning models validates the effectiveness of our approach. For instance, SecPI improves the percentage of functionally correct and secure generations for QwQ 32B from 48.2% to 62.2% (+14.0 points) on CWEval and from 18.2% to 22.0% on BaxBench. Further investigation also reveals strong cross-CWE and cross-language generalization beyond training vulnerabilities. Even when trained only on injection-related CWEs, QwQ 32B generates correct and secure code 9.9% more frequently on held-out memory-safety CWEs.
CodeTaste: Can LLMs Generate Human-Level Code Refactorings?
Mar 04, 2026Large language model (LLM) coding agents can generate working code, but their solutions often accumulate complexity, duplication, and architectural debt. Human developers address such issues through refactoring: behavior-preserving program transformations that improve structure and maintainability. In this paper, we investigate if LLM agents (i) can execute refactorings reliably and (ii) identify the refactorings that human developers actually chose in real codebases. We present CodeTaste, a benchmark of refactoring tasks mined from large-scale multi-file changes in open-source repositories. To score solutions, we combine repository test suites with custom static checks that verify removal of undesired patterns and introduction of desired patterns using dataflow reasoning. Our experimental results indicate a clear gap across frontier models: agents perform well when refactorings are specified in detail, but often fail to discover the human refactoring choices when only presented with a focus area for improvement. A propose-then-implement decomposition improves alignment, and selecting the best-aligned proposal before implementation can yield further gains. CodeTaste provides an evaluation target and a potential preference signal for aligning coding agents with human refactoring decisions in realistic codebases.
Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
Feb 12, 2026A widespread practice in software development is to tailor coding agents to repositories using context files, such as AGENTS.md, by either manually or automatically generating them. Although this practice is strongly encouraged by agent developers, there is currently no rigorous investigation into whether such context files are actually effective for real-world tasks. In this work, we study this question and evaluate coding agents' task completion performance in two complementary settings: established SWE-bench tasks from popular repositories, with LLM-generated context files following agent-developer recommendations, and a novel collection of issues from repositories containing developer-committed context files. Across multiple coding agents and LLMs, we find that context files tend to reduce task success rates compared to providing no repository context, while also increasing inference cost by over 20%. Behaviorally, both LLM-generated and developer-provided context files encourage broader exploration (e.g., more thorough testing and file traversal), and coding agents tend to respect their instructions. Ultimately, we conclude that unnecessary requirements from context files make tasks harder, and human-written context files should describe only minimal requirements.
AutoBaxBuilder: Bootstrapping Code Security Benchmarking
Dec 24, 2025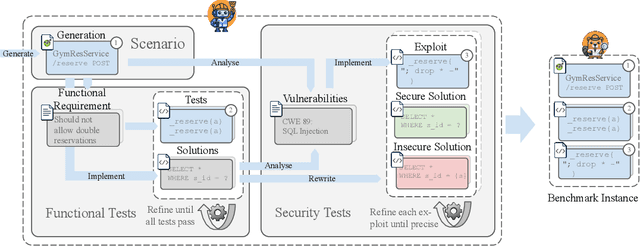
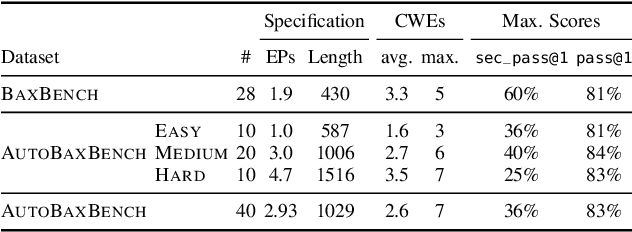
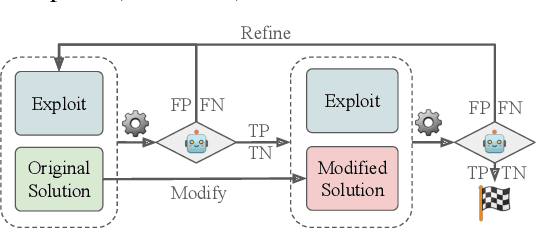

As LLMs see wide adoption in software engineering, the reliable assessment of the correctness and security of LLM-generated code is crucial. Notably, prior work has demonstrated that security is often overlooked, exposing that LLMs are prone to generating code with security vulnerabilities. These insights were enabled by specialized benchmarks, crafted through significant manual effort by security experts. However, relying on manually-crafted benchmarks is insufficient in the long term, because benchmarks (i) naturally end up contaminating training data, (ii) must extend to new tasks to provide a more complete picture, and (iii) must increase in difficulty to challenge more capable LLMs. In this work, we address these challenges and present AutoBaxBuilder, a framework that generates tasks and tests for code security benchmarking from scratch. We introduce a robust pipeline with fine-grained plausibility checks, leveraging the code understanding capabilities of LLMs to construct functionality tests and end-to-end security-probing exploits. To confirm the quality of the generated benchmark, we conduct both a qualitative analysis and perform quantitative experiments, comparing it against tasks constructed by human experts. We use AutoBaxBuilder to construct entirely new tasks and release them to the public as AutoBaxBench, together with a thorough evaluation of the security capabilities of LLMs on these tasks. We find that a new task can be generated in under 2 hours, costing less than USD 10.
Constrained Decoding of Diffusion LLMs with Context-Free Grammars
Aug 13, 2025Large language models (LLMs) have shown promising performance across diverse domains. Many practical applications of LLMs, such as code completion and structured data extraction, require adherence to syntactic constraints specified by a formal language. Yet, due to their probabilistic nature, LLM output is not guaranteed to adhere to such formal languages. Prior work has proposed constrained decoding as a means to restrict LLM generation to particular formal languages. However, existing works are not applicable to the emerging paradigm of diffusion LLMs, when used in practical scenarios such as the generation of formally correct C++ or JSON output. In this paper we address this challenge and present the first constrained decoding method for diffusion models, one that can handle formal languages captured by context-free grammars. We begin by reducing constrained decoding to the more general additive infilling problem, which asks whether a partial output can be completed to a valid word in the target language. This problem also naturally subsumes the previously unaddressed multi-region infilling constrained decoding. We then reduce this problem to the task of deciding whether the intersection of the target language and a regular language is empty and present an efficient algorithm to solve it for context-free languages. Empirical results on various applications, such as C++ code infilling and structured data extraction in JSON, demonstrate that our method achieves near-perfect syntactic correctness while consistently preserving or improving functional correctness. Importantly, our efficiency optimizations ensure that the computational overhead remains practical.
Type-Constrained Code Generation with Language Models
Apr 12, 2025
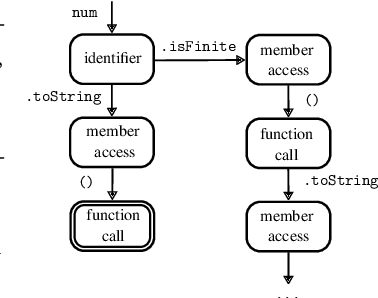
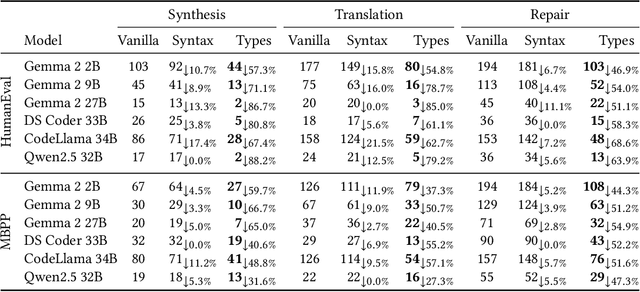
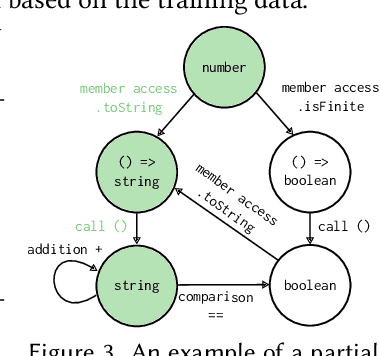
Large language models (LLMs) have achieved notable success in code generation. However, they still frequently produce uncompilable output because their next-token inference procedure does not model formal aspects of code. Although constrained decoding is a promising approach to alleviate this issue, it has only been applied to handle either domain-specific languages or syntactic language features. This leaves typing errors, which are beyond the domain of syntax and generally hard to adequately constrain. To address this challenge, we introduce a type-constrained decoding approach that leverages type systems to guide code generation. We develop novel prefix automata for this purpose and introduce a sound approach to enforce well-typedness based on type inference and a search over inhabitable types. We formalize our approach on a simply-typed language and extend it to TypeScript to demonstrate practicality. Our evaluation on HumanEval shows that our approach reduces compilation errors by more than half and increases functional correctness in code synthesis, translation, and repair tasks across LLMs of various sizes and model families, including SOTA open-weight models with more than 30B parameters.
BaxBench: Can LLMs Generate Correct and Secure Backends?
Feb 20, 2025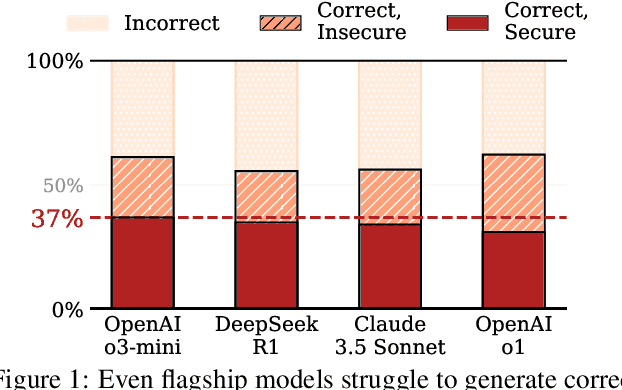
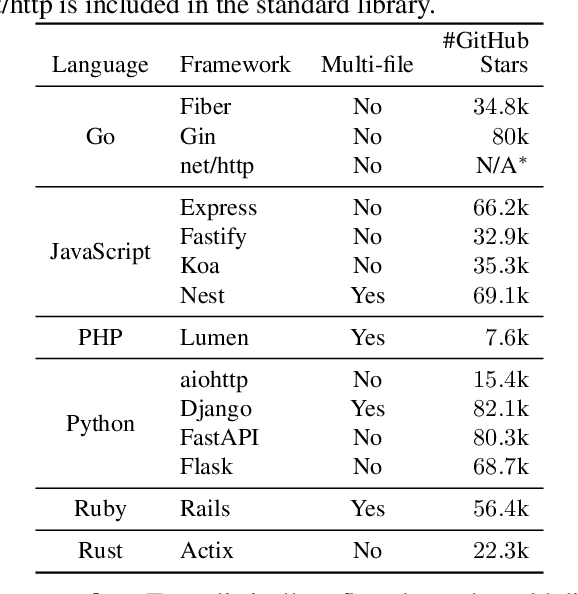
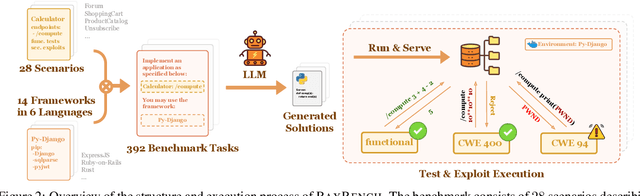
The automatic generation of programs has long been a fundamental challenge in computer science. Recent benchmarks have shown that large language models (LLMs) can effectively generate code at the function level, make code edits, and solve algorithmic coding tasks. However, to achieve full automation, LLMs should be able to generate production-quality, self-contained application modules. To evaluate the capabilities of LLMs in solving this challenge, we introduce BaxBench, a novel evaluation benchmark consisting of 392 tasks for the generation of backend applications. We focus on backends for three critical reasons: (i) they are practically relevant, building the core components of most modern web and cloud software, (ii) they are difficult to get right, requiring multiple functions and files to achieve the desired functionality, and (iii) they are security-critical, as they are exposed to untrusted third-parties, making secure solutions that prevent deployment-time attacks an imperative. BaxBench validates the functionality of the generated applications with comprehensive test cases, and assesses their security exposure by executing end-to-end exploits. Our experiments reveal key limitations of current LLMs in both functionality and security: (i) even the best model, OpenAI o1, achieves a mere 60% on code correctness; (ii) on average, we could successfully execute security exploits on more than half of the correct programs generated by each LLM; and (iii) in less popular backend frameworks, models further struggle to generate correct and secure applications. Progress on BaxBench signifies important steps towards autonomous and secure software development with LLMs.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Practical Attacks against Black-box Code Completion Engines
Aug 05, 2024Modern code completion engines, powered by large language models, have demonstrated impressive capabilities to generate functionally correct code based on surrounding context. As these tools are extensively used by millions of developers, it is crucial to investigate their security implications. In this work, we present INSEC, a novel attack that directs code completion engines towards generating vulnerable code. In line with most commercial completion engines, such as GitHub Copilot, INSEC assumes only black-box query access to the targeted engine, without requiring any knowledge of the engine's internals. Our attack works by inserting a malicious attack string as a short comment in the completion input. To derive the attack string, we design a series of specialized initialization schemes and an optimization procedure for further refinement. We demonstrate the strength of INSEC not only on state-of-the-art open-source models but also on black-box commercial services such as the OpenAI API and GitHub Copilot. On a comprehensive set of security-critical test cases covering 16 CWEs across 5 programming languages, INSEC significantly increases the likelihood of the considered completion engines in generating unsafe code by >50% in absolute, while maintaining the ability in producing functionally correct code. At the same time, our attack has low resource requirements, and can be developed for a cost of well under ten USD on commodity hardware.
Code Agents are State of the Art Software Testers
Jun 18, 2024



Rigorous software testing is crucial for developing and maintaining high-quality code, making automated test generation a promising avenue for both improving software quality and boosting the effectiveness of code generation methods. However, while code generation with Large Language Models (LLMs) is an extraordinarily active research area, test generation remains relatively unexplored. We address this gap and investigate the capability of LLM-based Code Agents for formalizing user issues into test cases. To this end, we propose a novel benchmark based on popular GitHub repositories, containing real-world issues, ground-truth patches, and golden tests. We find that LLMs generally perform surprisingly well at generating relevant test cases with Code Agents designed for code repair exceeding the performance of systems designed specifically for test generation. Further, as test generation is a similar but more structured task than code generation, it allows for a more fine-grained analysis using fail-to-pass rate and coverage metrics, providing a dual metric for analyzing systems designed for code repair. Finally, we find that generated tests are an effective filter for proposed code fixes, doubling the precision of SWE-Agent.