 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training of Neural Stochastic Differential Equations by Matching Finite Dimensional Distributions
Oct 04, 2024



Neural Stochastic Differential Equations (Neural SDEs) have emerged as powerful mesh-free generative models for continuous stochastic processes, with critical applications in fields such as finance, physics, and biology. Previous state-of-the-art methods have relied on adversarial training, such as GANs, or on minimizing distance measures between processes using signature kernels. However, GANs suffer from issues like instability, mode collapse, and the need for specialized training techniques, while signature kernel-based methods require solving linear PDEs and backpropagating gradients through the solver, whose computational complexity scales quadratically with the discretization steps. In this paper, we identify a novel class of strictly proper scoring rules for comparing continuous Markov processes. This theoretical finding naturally leads to a novel approach called Finite Dimensional Matching (FDM) for training Neural SDEs. Our method leverages the Markov property of SDEs to provide a computationally efficient training objective. This scoring rule allows us to bypass the computational overhead associated with signature kernels and reduces the training complexity from $O(D^2)$ to $O(D)$ per epoch, where $D$ represents the number of discretization steps of the process. We demonstrate that FDM achieves superior performance, consistently outperforming existing methods in terms of both computational efficiency and generative quality.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Evaluating the Impact of Model Scale for Compositional Generalization in Semantic Parsing
May 24, 2022
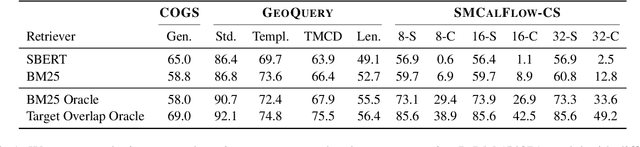
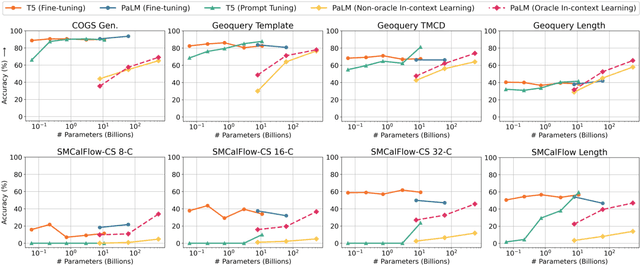
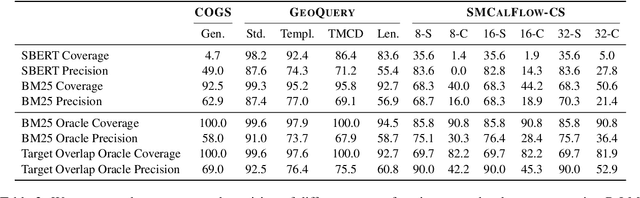
Despite their strong performance on many tasks, pre-trained language models have been shown to struggle on out-of-distribution compositional generalization. Meanwhile, recent work has shown considerable improvements on many NLP tasks from model scaling. Can scaling up model size also improve compositional generalization in semantic parsing? We evaluate encoder-decoder models up to 11B parameters and decoder-only models up to 540B parameters, and compare model scaling curves for three different methods for transfer learning: fine-tuning all parameters, prompt tuning, and in-context learning. We observe that fine-tuning generally has flat or negative scaling curves on out-of-distribution compositional generalization in semantic parsing evaluations. In-context learning has positive scaling curves, but is generally outperformed by much smaller fine-tuned models. Prompt-tuning can outperform fine-tuning, suggesting further potential improvements from scaling as it exhibits a more positive scaling curve. Additionally, we identify several error trends that vary with model scale. For example, larger models are generally better at modeling the syntax of the output space, but are also more prone to certain types of overfitting. Overall, our study highlights limitations of current techniques for effectively leveraging model scale for compositional generalization, while our analysis also suggests promising directions for future work.
Measuring and Reducing Gendered Correlations in Pre-trained Models
Oct 12, 2020
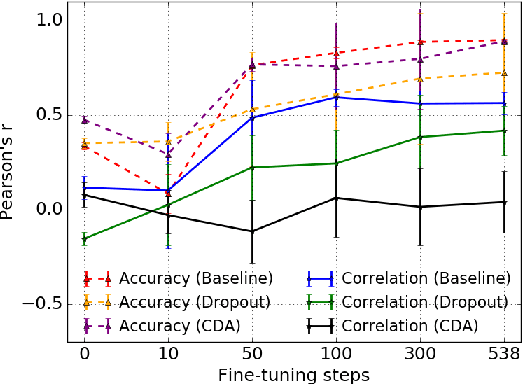
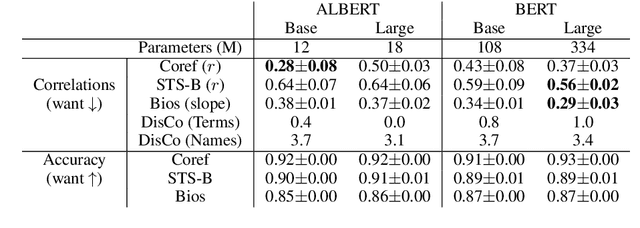
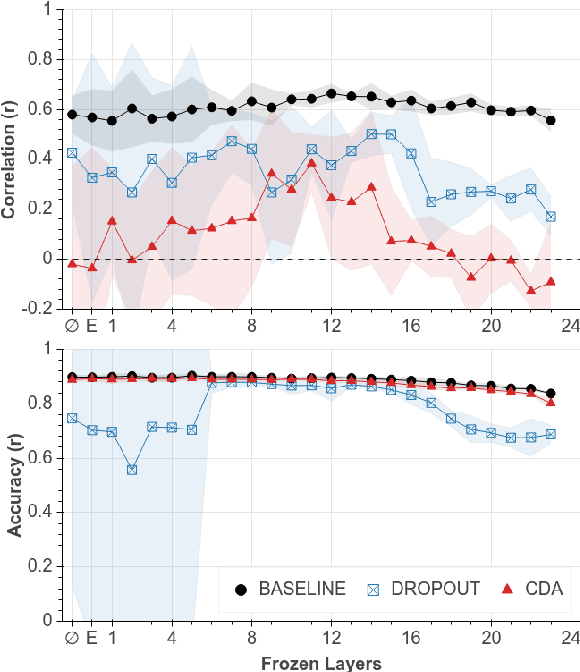
Pre-trained models have revolutionized natural language understanding. However, researchers have found they can encode artifacts undesired in many applications, such as professions correlating with one gender more than another. We explore such gendered correlations as a case study for how to address unintended correlations in pre-trained models. We define metrics and reveal that it is possible for models with similar accuracy to encode correlations at very different rates. We show how measured correlations can be reduced with general-purpose techniques, and highlight the trade offs different strategies have. With these results, we make recommendations for training robust models: (1) carefully evaluate unintended correlations, (2) be mindful of seemingly innocuous configuration differences, and (3) focus on general mitigations.
Scalable Cross Lingual Pivots to Model Pronoun Gender for Translation
Jun 16, 2020


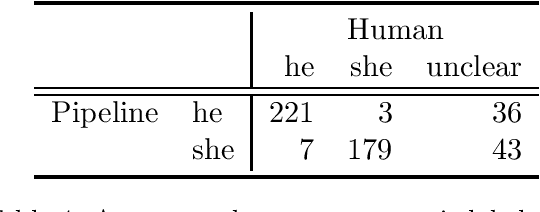
Machine translation systems with inadequate document understanding can make errors when translating dropped or neutral pronouns into languages with gendered pronouns (e.g., English). Predicting the underlying gender of these pronouns is difficult since it is not marked textually and must instead be inferred from coreferent mentions in the context. We propose a novel cross-lingual pivoting technique for automatically producing high-quality gender labels, and show that this data can be used to fine-tune a BERT classifier with 92% F1 for Spanish dropped feminine pronouns, compared with 30-51% for neural machine translation models and 54-71% for a non-fine-tuned BERT model. We augment a neural machine translation model with labels from our classifier to improve pronoun translation, while still having parallelizable translation models that translate a sentence at a time.
Syntactic Data Augmentation Increases Robustness to Inference Heuristics
Apr 24, 2020
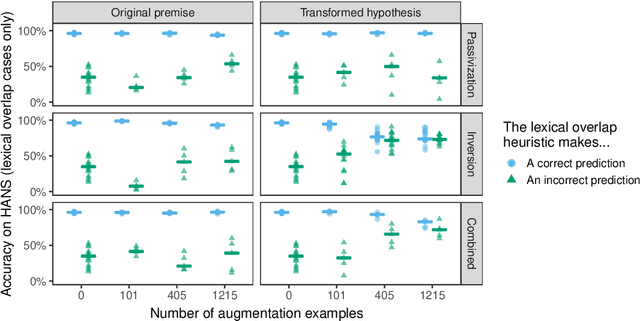
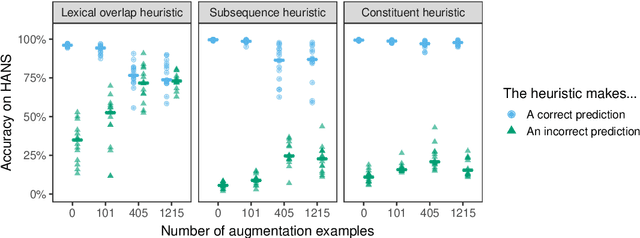

Pretrained neural models such as BERT, when fine-tuned to perform natural language inference (NLI), often show high accuracy on standard datasets, but display a surprising lack of sensitivity to word order on controlled challenge sets. We hypothesize that this issue is not primarily caused by the pretrained model's limitations, but rather by the paucity of crowdsourced NLI examples that might convey the importance of syntactic structure at the fine-tuning stage. We explore several methods to augment standard training sets with syntactically informative examples, generated by applying syntactic transformations to sentences from the MNLI corpus. The best-performing augmentation method, subject/object inversion, improved BERT's accuracy on controlled examples that diagnose sensitivity to word order from 0.28 to 0.73, without affecting performance on the MNLI test set. This improvement generalized beyond the particular construction used for data augmentation, suggesting that augmentation causes BERT to recruit abstract syntactic representations.
Collecting Entailment Data for Pretraining: New Protocols and Negative Results
Apr 24, 2020

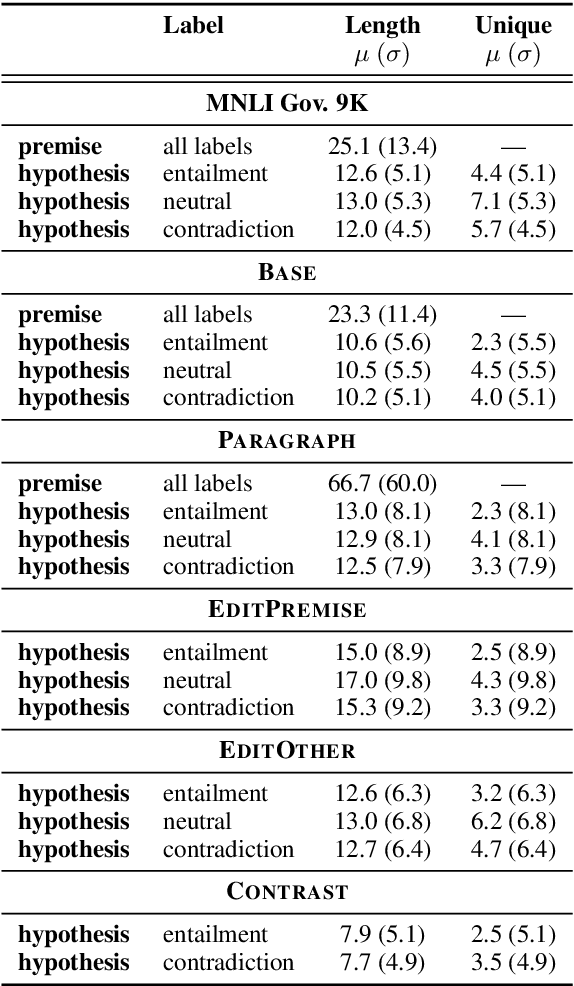
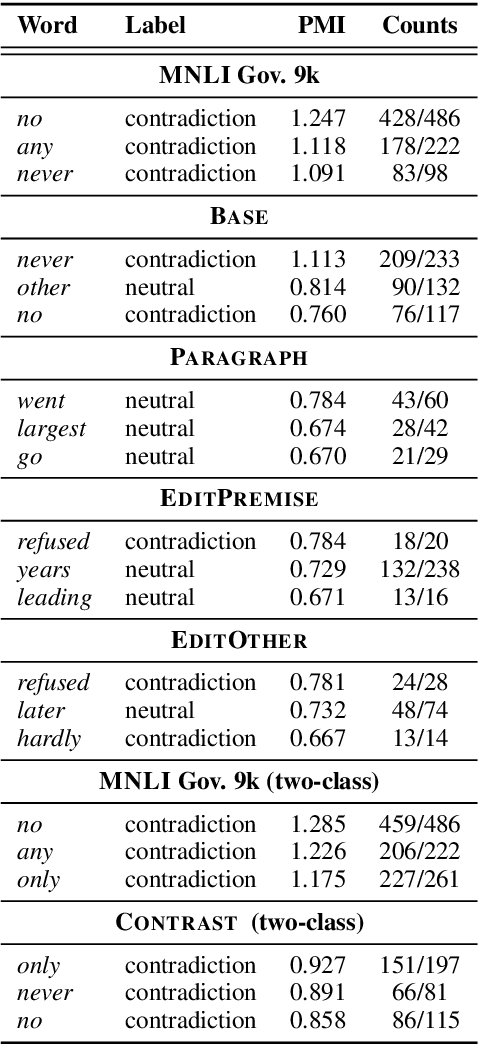
Textual entailment (or NLI) data has proven useful as pretraining data for tasks requiring language understanding, even when building on an already-pretrained model like RoBERTa. The standard protocol for collecting NLI was not designed for the creation of pretraining data, and it is likely far from ideal for this purpose. With this application in mind, we propose four alternative protocols, each aimed at improving either the ease with which annotators can produce sound training examples or the quality and diversity of those examples. Using these alternatives and a simple MNLI-based baseline, we collect and compare five new 8.5k-example training sets. Our primary results are solidly negative, with our baseline MNLI-style dataset yielding good transfer performance, but none of our four new methods (nor the recent ANLI) showing any improvements on that baseline. However, we do observe that all four of these interventions, especially the use of seed sentences for inspiration, reduce previously observed issues with annotation artifacts.
Giving BERT a Calculator: Finding Operations and Arguments with Reading Comprehension
Sep 12, 2019
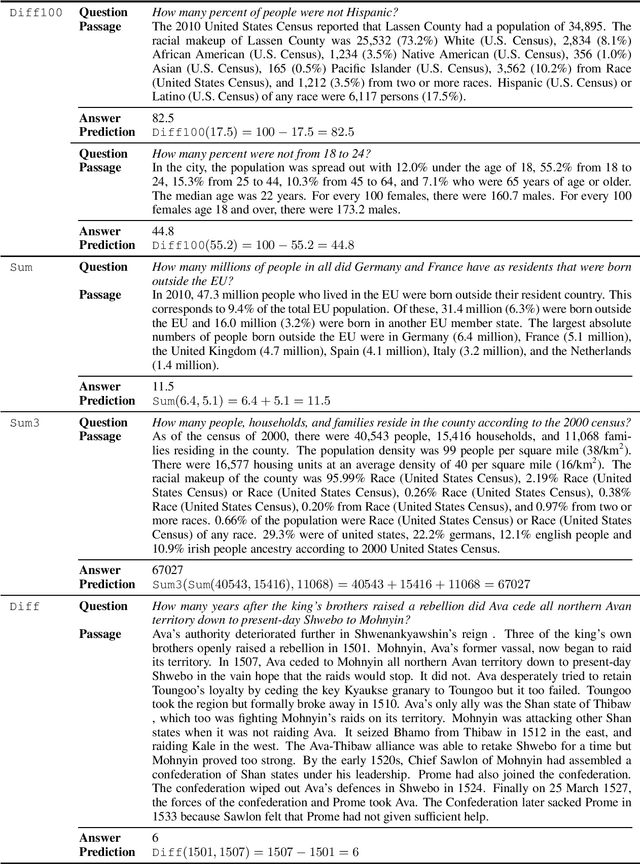
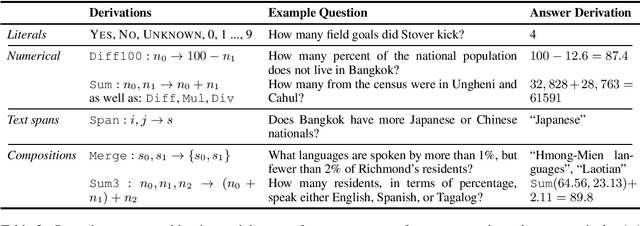

Reading comprehension models have been successfully applied to extractive text answers, but it is unclear how best to generalize these models to abstractive numerical answers. We enable a BERT-based reading comprehension model to perform lightweight numerical reasoning. We augment the model with a predefined set of executable 'programs' which encompass simple arithmetic as well as extraction. Rather than having to learn to manipulate numbers directly, the model can pick a program and execute it. On the recent Discrete Reasoning Over Passages (DROP) dataset, designed to challenge reading comprehension models, we show a 33% absolute improvement by adding shallow programs. The model can learn to predict new operations when appropriate in a math word problem setting (Roy and Roth, 2015) with very few training examples.
Synthetic QA Corpora Generation with Roundtrip Consistency
Jun 12, 2019
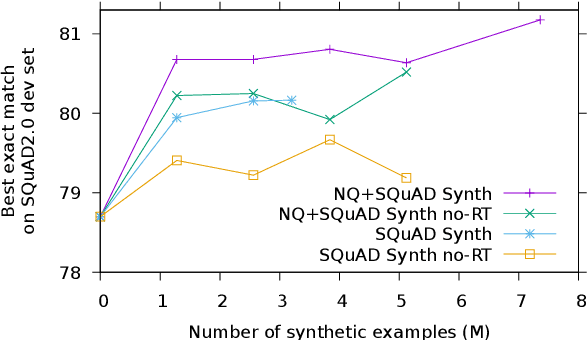
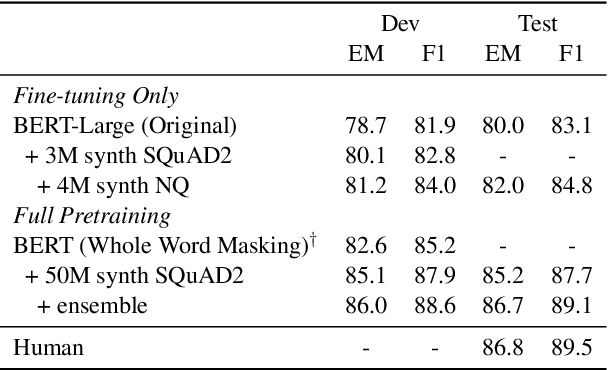
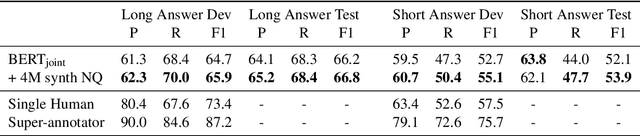
We introduce a novel method of generating synthetic question answering corpora by combining models of question generation and answer extraction, and by filtering the results to ensure roundtrip consistency. By pretraining on the resulting corpora we obtain significant improvements on SQuAD2 and NQ, establishing a new state-of-the-art on the latter. Our synthetic data generation models, for both question generation and answer extraction, can be fully reproduced by finetuning a publicly available BERT model on the extractive subsets of SQuAD2 and NQ. We also describe a more powerful variant that does full sequence-to-sequence pretraining for question generation, obtaining exact match and F1 at less than 0.1% and 0.4% from human performance on SQuAD2.
Morphosyntactic Tagging with a Meta-BiLSTM Model over Context Sensitive Token Encodings
May 21, 2018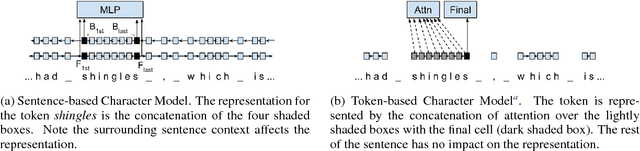
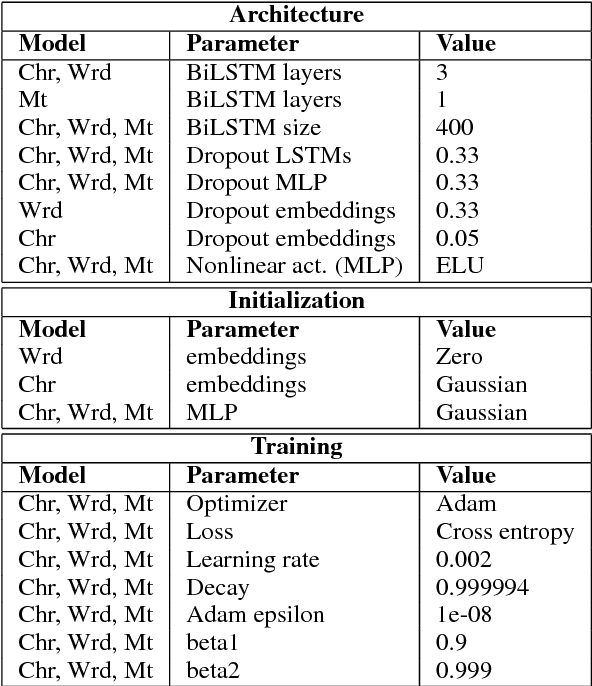
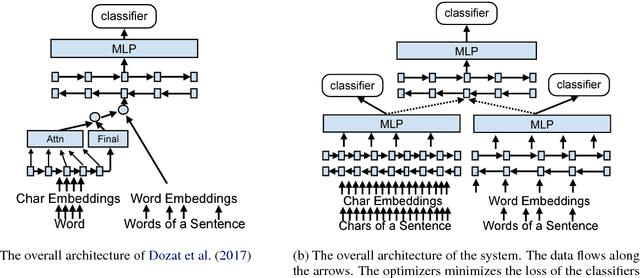
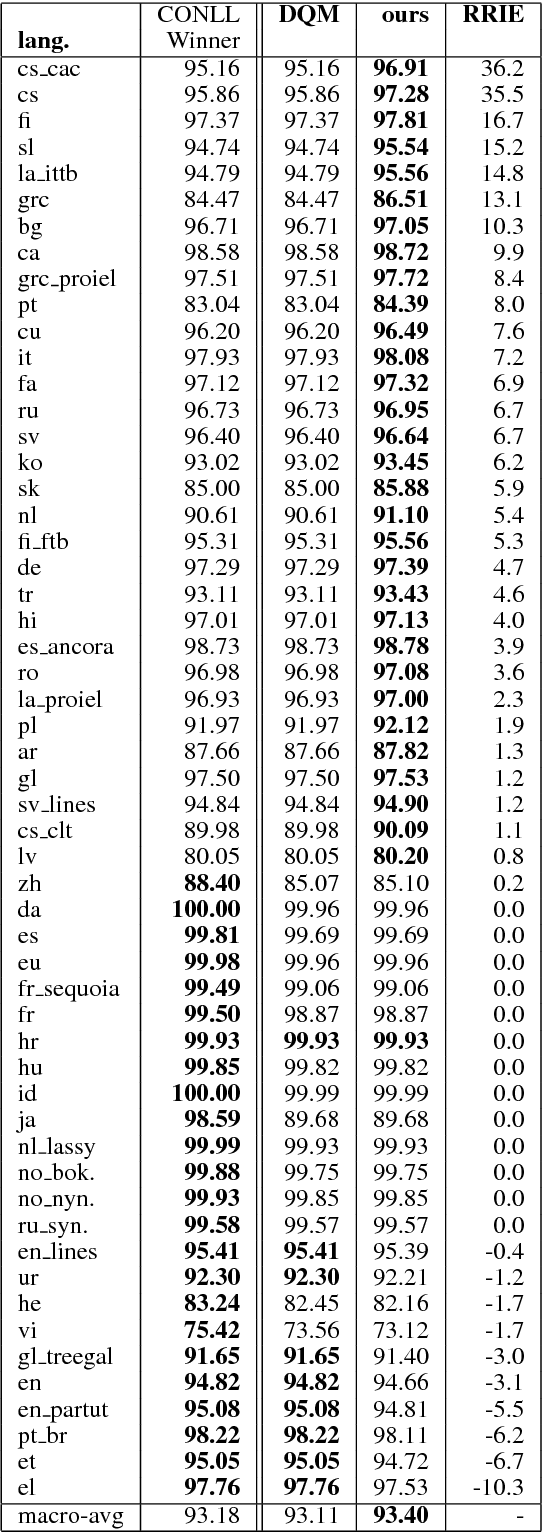
The rise of neural networks, and particularly recurrent neural networks, has produced significant advances in part-of-speech tagging accuracy. One characteristic common among these models is the presence of rich initial word encodings. These encodings typically are composed of a recurrent character-based representation with learned and pre-trained word embeddings. However, these encodings do not consider a context wider than a single word and it is only through subsequent recurrent layers that word or sub-word information interacts. In this paper, we investigate models that use recurrent neural networks with sentence-level context for initial character and word-based representations. In particular we show that optimal results are obtained by integrating these context sensitive representations through synchronized training with a meta-model that learns to combine their states. We present results on part-of-speech and morphological tagging with state-of-the-art performance on a number of languages.