 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Curious Class of Adpositional Multiword Expressions in Korean
Feb 17, 2026Multiword expressions (MWEs) have been widely studied in cross-lingual annotation frameworks such as PARSEME. However, Korean MWEs remain underrepresented in these efforts. In particular, Korean multiword adpositions lack systematic analysis, annotated resources, and integration into existing multilingual frameworks. In this paper, we study a class of Korean functional multiword expressions: postpositional verb-based constructions (PVCs). Using data from Korean Wikipedia, we survey and analyze several PVC expressions and contrast them with non-MWEs and light verb constructions (LVCs) with similar structure. Building on this analysis, we propose annotation guidelines designed to support future work in Korean multiword adpositions and facilitate alignment with cross-lingual frameworks.
\textsc{CantoNLU}: A benchmark for Cantonese natural language understanding
Oct 23, 2025Cantonese, although spoken by millions, remains under-resourced due to policy and diglossia. To address this scarcity of evaluation frameworks for Cantonese, we introduce \textsc{\textbf{CantoNLU}}, a benchmark for Cantonese natural language understanding (NLU). This novel benchmark spans seven tasks covering syntax and semantics, including word sense disambiguation, linguistic acceptability judgment, language detection, natural language inference, sentiment analysis, part-of-speech tagging, and dependency parsing. In addition to the benchmark, we provide model baseline performance across a set of models: a Mandarin model without Cantonese training, two Cantonese-adapted models obtained by continual pre-training a Mandarin model on Cantonese text, and a monolingual Cantonese model trained from scratch. Results show that Cantonese-adapted models perform best overall, while monolingual models perform better on syntactic tasks. Mandarin models remain competitive in certain settings, indicating that direct transfer may be sufficient when Cantonese domain data is scarce. We release all datasets, code, and model weights to facilitate future research in Cantonese NLP.
When Does Meaning Backfire? Investigating the Role of AMRs in NLI
Jun 17, 2025Natural Language Inference (NLI) relies heavily on adequately parsing the semantic content of the premise and hypothesis. In this work, we investigate whether adding semantic information in the form of an Abstract Meaning Representation (AMR) helps pretrained language models better generalize in NLI. Our experiments integrating AMR into NLI in both fine-tuning and prompting settings show that the presence of AMR in fine-tuning hinders model generalization while prompting with AMR leads to slight gains in \texttt{GPT-4o}. However, an ablation study reveals that the improvement comes from amplifying surface-level differences rather than aiding semantic reasoning. This amplification can mislead models to predict non-entailment even when the core meaning is preserved.
Building UD Cairo for Old English in the Classroom
Apr 25, 2025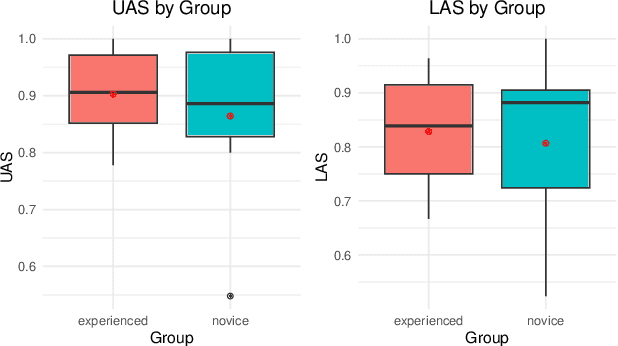
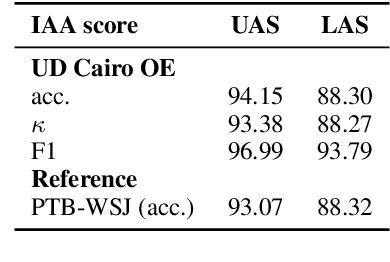
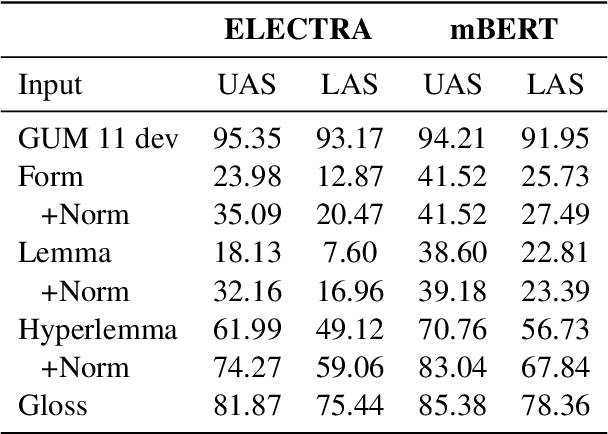
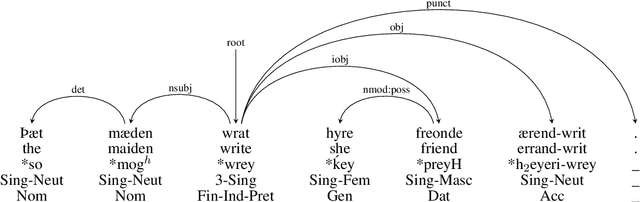
In this paper we present a sample treebank for Old English based on the UD Cairo sentences, collected and annotated as part of a classroom curriculum in Historical Linguistics. To collect the data, a sample of 20 sentences illustrating a range of syntactic constructions in the world's languages, we employ a combination of LLM prompting and searches in authentic Old English data. For annotation we assigned sentences to multiple students with limited prior exposure to UD, whose annotations we compare and adjudicate. Our results suggest that while current LLM outputs in Old English do not reflect authentic syntax, this can be mitigated by post-editing, and that although beginner annotators do not possess enough background to complete the task perfectly, taken together they can produce good results and learn from the experience. We also conduct preliminary parsing experiments using Modern English training data, and find that although performance on Old English is poor, parsing on annotated features (lemma, hyperlemma, gloss) leads to improved performance.
Punctuation Restoration Improves Structure Understanding without Supervision
Feb 21, 2024



Unsupervised learning objectives like language modeling and de-noising constitute a significant part in producing pre-trained models that perform various downstream applications from natural language understanding to conversational tasks. However, despite impressive generative capabilities of recent large language models, their abilities to capture syntactic or semantic structure within text lag behind. We hypothesize that the mismatch between linguistic performance and competence in machines is attributable to insufficient transfer of linguistic structure knowledge to computational systems with currently popular pre-training objectives. We show that punctuation restoration as a learning objective improves in- and out-of-distribution performance on structure-related tasks like named entity recognition, open information extraction, chunking, and part-of-speech tagging. Punctuation restoration is an effective learning objective that can improve structure understanding and yield a more robust structure-aware representations of natural language.
Structured Language Generation Model for Robust Structure Prediction
Feb 19, 2024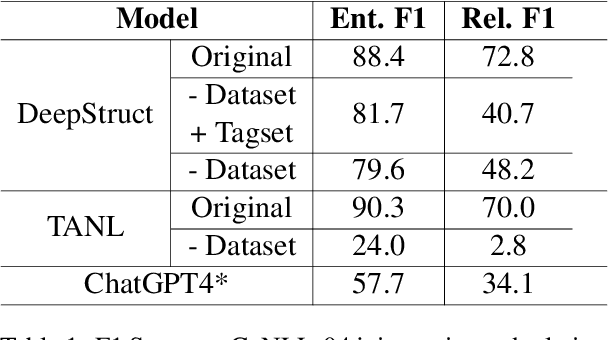

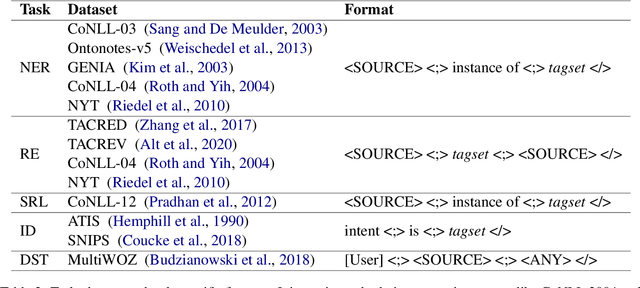
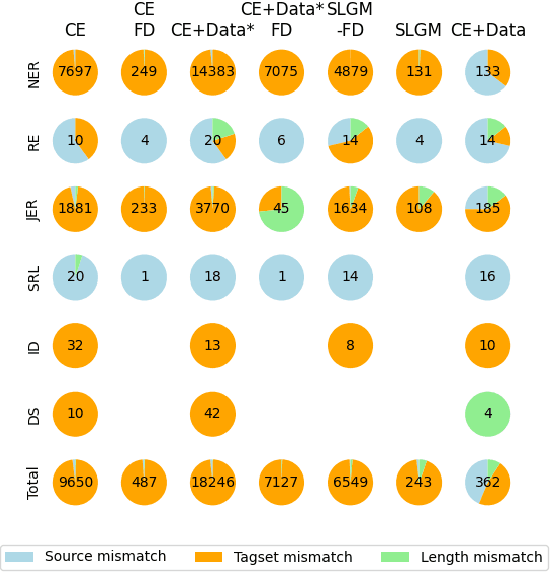
Previous work in structured prediction (e.g. NER, information extraction) using single model make use of explicit dataset information, which helps boost in-distribution performance but is orthogonal to robust generalization in real-world situations. To overcome this limitation, we propose the Structured Language Generation Model (SLGM), a framework that reduces sequence-to-sequence problems to classification problems via methodologies in loss calibration and decoding method. Our experimental results show that SLGM is able to maintain performance without explicit dataset information, follow and potentially replace dataset-specific fine-tuning.
Syntactic Data Augmentation Increases Robustness to Inference Heuristics
Apr 24, 2020
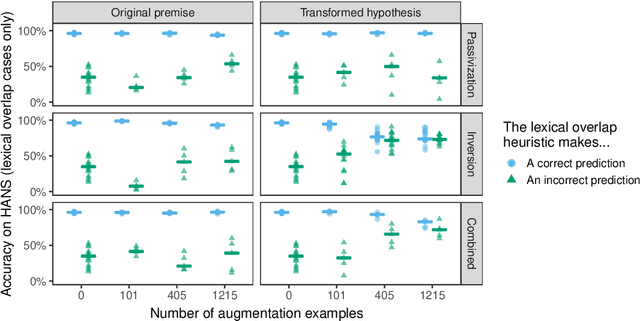
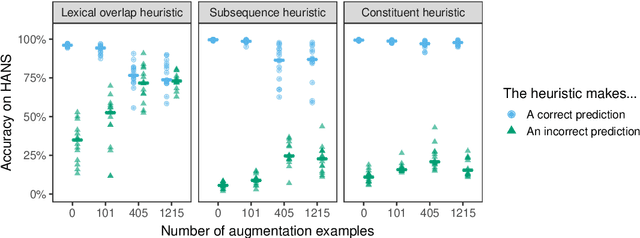

Pretrained neural models such as BERT, when fine-tuned to perform natural language inference (NLI), often show high accuracy on standard datasets, but display a surprising lack of sensitivity to word order on controlled challenge sets. We hypothesize that this issue is not primarily caused by the pretrained model's limitations, but rather by the paucity of crowdsourced NLI examples that might convey the importance of syntactic structure at the fine-tuning stage. We explore several methods to augment standard training sets with syntactically informative examples, generated by applying syntactic transformations to sentences from the MNLI corpus. The best-performing augmentation method, subject/object inversion, improved BERT's accuracy on controlled examples that diagnose sensitivity to word order from 0.28 to 0.73, without affecting performance on the MNLI test set. This improvement generalized beyond the particular construction used for data augmentation, suggesting that augmentation causes BERT to recruit abstract syntactic representations.
BERTs of a feather do not generalize together: Large variability in generalization across models with similar test set performance
Nov 07, 2019
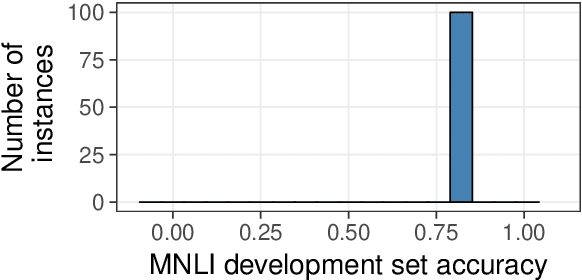
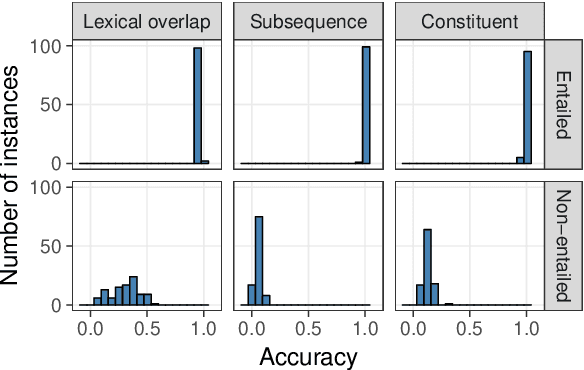
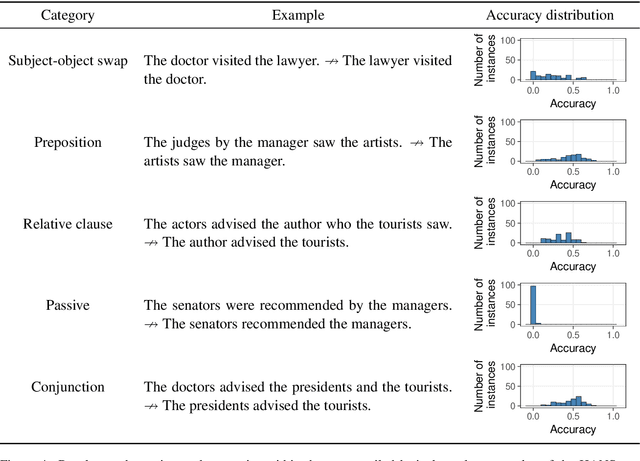
If the same neural architecture is trained multiple times on the same dataset, will it make similar linguistic generalizations across runs? To study this question, we fine-tuned 100 instances of BERT on the Multi-genre Natural Language Inference (MNLI) dataset and evaluated them on the HANS dataset, which measures syntactic generalization in natural language inference. On the MNLI development set, the behavior of all instances was remarkably consistent, with accuracy ranging between 83.6% and 84.8%. In stark contrast, the same models varied widely in their generalization performance. For example, on the simple case of subject-object swap (e.g., knowing that "the doctor visited the lawyer" does not entail "the lawyer visited the doctor"), accuracy ranged from 0.00% to 66.2%. Such variation likely arises from the presence of many local minima that are equally attractive to a low-bias learner such as a neural network; decreasing the variability may therefore require models with stronger inductive biases.