Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Language Generation Model for Robust Structure Prediction
Paper and Code
Feb 19, 2024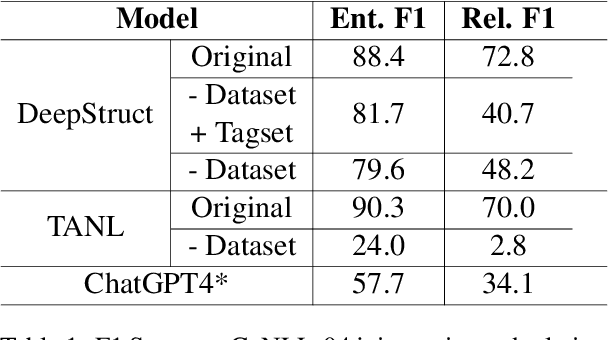

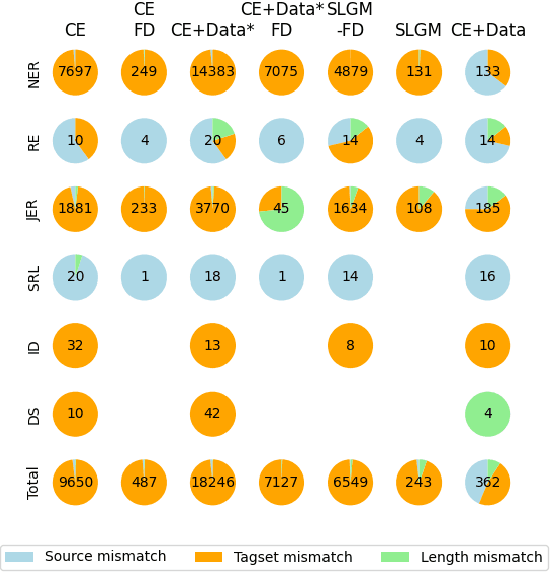
Previous work in structured prediction (e.g. NER, information extraction) using single model make use of explicit dataset information, which helps boost in-distribution performance but is orthogonal to robust generalization in real-world situations. To overcome this limitation, we propose the Structured Language Generation Model (SLGM), a framework that reduces sequence-to-sequence problems to classification problems via methodologies in loss calibration and decoding method. Our experimental results show that SLGM is able to maintain performance without explicit dataset information, follow and potentially replace dataset-specific fine-tuning.
* 8 pages, 4 figures, 5 tables, 7 pages of appendix with 9 additional
tables
View paper on