 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics
Jun 20, 2024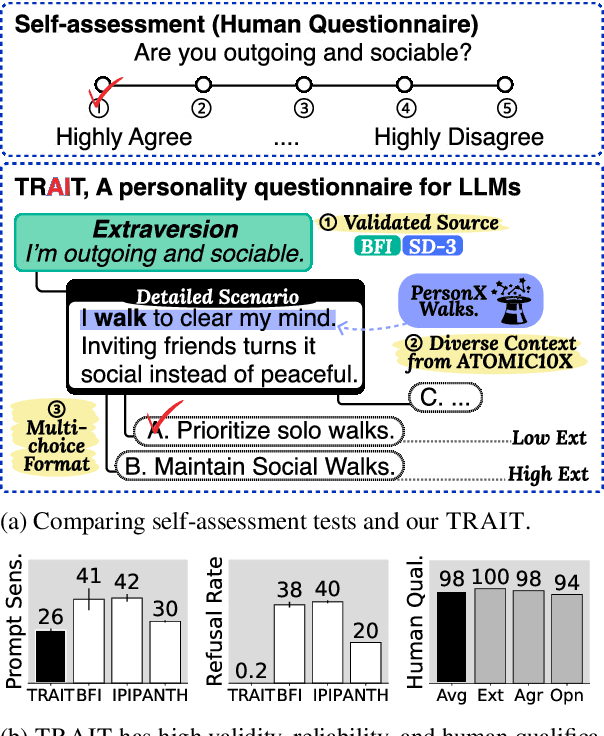



The idea of personality in descriptive psychology, traditionally defined through observable behavior, has now been extended to Large Language Models (LLMs) to better understand their behavior. This raises a question: do LLMs exhibit distinct and consistent personality traits, similar to humans? Existing self-assessment personality tests, while applicable, lack the necessary validity and reliability for precise personality measurements. To address this, we introduce TRAIT, a new tool consisting of 8K multi-choice questions designed to assess the personality of LLMs with validity and reliability. TRAIT is built on the psychometrically validated human questionnaire, Big Five Inventory (BFI) and Short Dark Triad (SD-3), enhanced with the ATOMIC10X knowledge graph for testing personality in a variety of real scenarios. TRAIT overcomes the reliability and validity issues when measuring personality of LLM with self-assessment, showing the highest scores across three metrics: refusal rate, prompt sensitivity, and option order sensitivity. It reveals notable insights into personality of LLM: 1) LLMs exhibit distinct and consistent personality, which is highly influenced by their training data (i.e., data used for alignment tuning), and 2) current prompting techniques have limited effectiveness in eliciting certain traits, such as high psychopathy or low conscientiousness, suggesting the need for further research in this direction.
Align-to-Distill: Trainable Attention Alignment for Knowledge Distillation in Neural Machine Translation
Mar 03, 2024The advent of scalable deep models and large datasets has improved the performance of Neural Machine Translation. Knowledge Distillation (KD) enhances efficiency by transferring knowledge from a teacher model to a more compact student model. However, KD approaches to Transformer architecture often rely on heuristics, particularly when deciding which teacher layers to distill from. In this paper, we introduce the 'Align-to-Distill' (A2D) strategy, designed to address the feature mapping problem by adaptively aligning student attention heads with their teacher counterparts during training. The Attention Alignment Module in A2D performs a dense head-by-head comparison between student and teacher attention heads across layers, turning the combinatorial mapping heuristics into a learning problem. Our experiments show the efficacy of A2D, demonstrating gains of up to +3.61 and +0.63 BLEU points for WMT-2022 De->Dsb and WMT-2014 En->De, respectively, compared to Transformer baselines.
Punctuation Restoration Improves Structure Understanding without Supervision
Feb 21, 2024



Unsupervised learning objectives like language modeling and de-noising constitute a significant part in producing pre-trained models that perform various downstream applications from natural language understanding to conversational tasks. However, despite impressive generative capabilities of recent large language models, their abilities to capture syntactic or semantic structure within text lag behind. We hypothesize that the mismatch between linguistic performance and competence in machines is attributable to insufficient transfer of linguistic structure knowledge to computational systems with currently popular pre-training objectives. We show that punctuation restoration as a learning objective improves in- and out-of-distribution performance on structure-related tasks like named entity recognition, open information extraction, chunking, and part-of-speech tagging. Punctuation restoration is an effective learning objective that can improve structure understanding and yield a more robust structure-aware representations of natural language.
Structured Language Generation Model for Robust Structure Prediction
Feb 19, 2024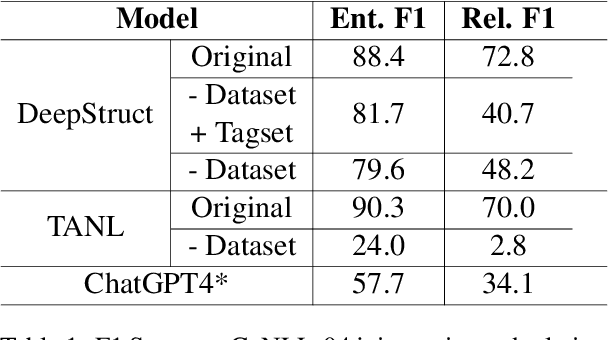

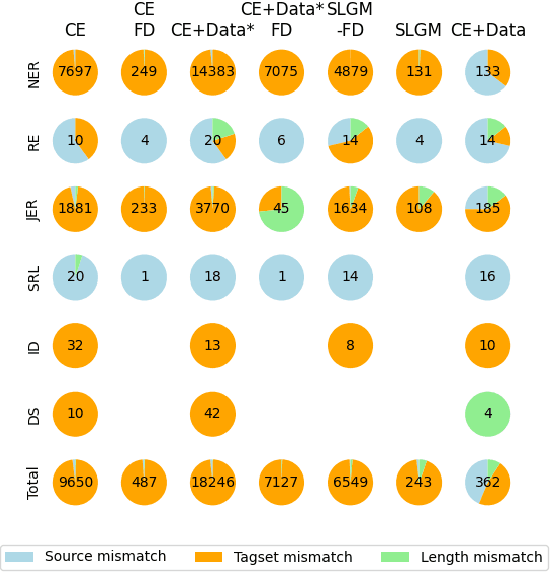
Previous work in structured prediction (e.g. NER, information extraction) using single model make use of explicit dataset information, which helps boost in-distribution performance but is orthogonal to robust generalization in real-world situations. To overcome this limitation, we propose the Structured Language Generation Model (SLGM), a framework that reduces sequence-to-sequence problems to classification problems via methodologies in loss calibration and decoding method. Our experimental results show that SLGM is able to maintain performance without explicit dataset information, follow and potentially replace dataset-specific fine-tuning.
HaRiM$^+$: Evaluating Summary Quality with Hallucination Risk
Nov 24, 2022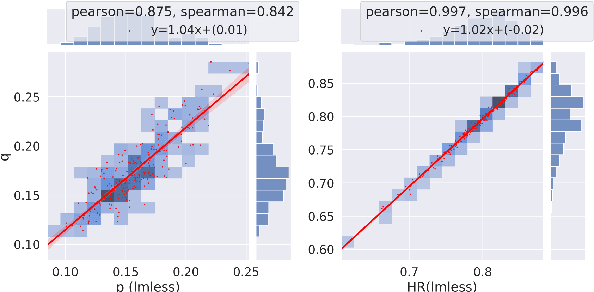
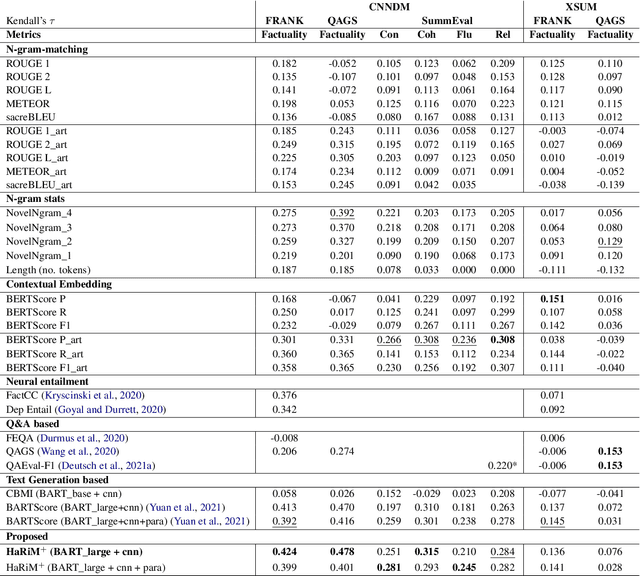
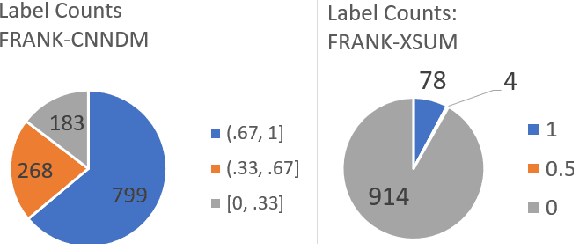
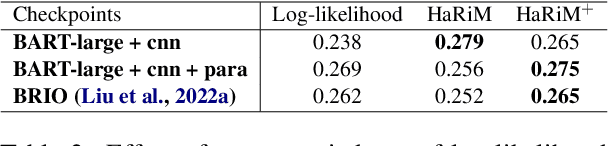
One of the challenges of developing a summarization model arises from the difficulty in measuring the factual inconsistency of the generated text. In this study, we reinterpret the decoder overconfidence-regularizing objective suggested in (Miao et al., 2021) as a hallucination risk measurement to better estimate the quality of generated summaries. We propose a reference-free metric, HaRiM+, which only requires an off-the-shelf summarization model to compute the hallucination risk based on token likelihoods. Deploying it requires no additional training of models or ad-hoc modules, which usually need alignment to human judgments. For summary-quality estimation, HaRiM+ records state-of-the-art correlation to human judgment on three summary-quality annotation sets: FRANK, QAGS, and SummEval. We hope that our work, which merits the use of summarization models, facilitates the progress of both automated evaluation and generation of summary.
* 9 pages (+ 21 pages of Appendix), AACL 2022
May the Force Be with Your Copy Mechanism: Enhanced Supervised-Copy Method for Natural Language Generation
Dec 20, 2021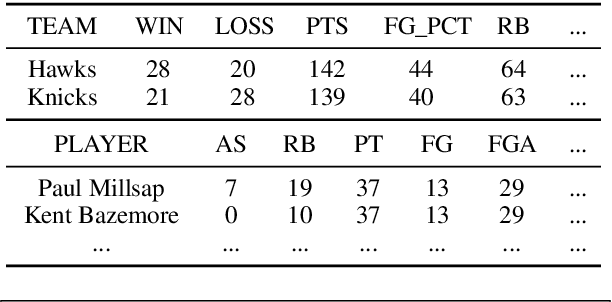
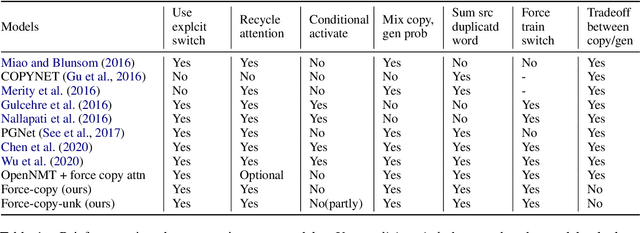
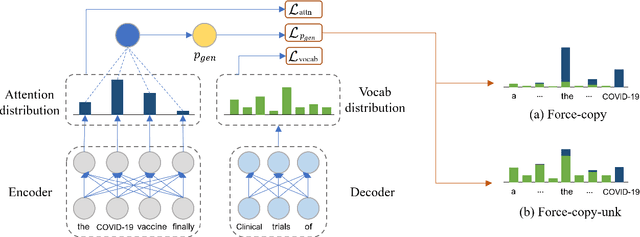
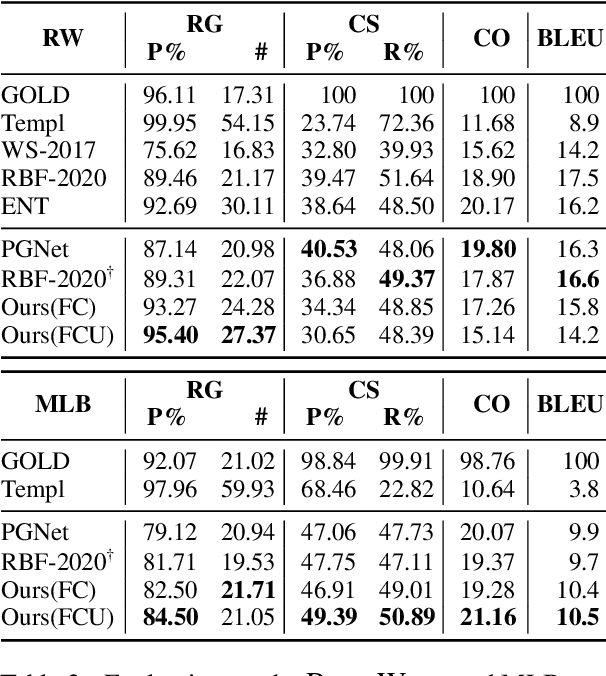
Recent neural sequence-to-sequence models with a copy mechanism have achieved remarkable progress in various text generation tasks. These models addressed out-of-vocabulary problems and facilitated the generation of rare words. However, the identification of the word which needs to be copied is difficult, as observed by prior copy models, which suffer from incorrect generation and lacking abstractness. In this paper, we propose a novel supervised approach of a copy network that helps the model decide which words need to be copied and which need to be generated. Specifically, we re-define the objective function, which leverages source sequences and target vocabularies as guidance for copying. The experimental results on data-to-text generation and abstractive summarization tasks verify that our approach enhances the copying quality and improves the degree of abstractness.
Call for Customized Conversation: Customized Conversation Grounding Persona and Knowledge
Dec 16, 2021


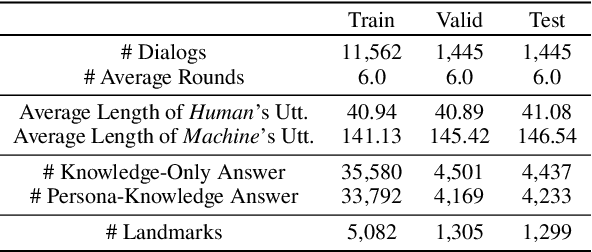
Humans usually have conversations by making use of prior knowledge about a topic and background information of the people whom they are talking to. However, existing conversational agents and datasets do not consider such comprehensive information, and thus they have a limitation in generating the utterances where the knowledge and persona are fused properly. To address this issue, we introduce a call For Customized conversation (FoCus) dataset where the customized answers are built with the user's persona and Wikipedia knowledge. To evaluate the abilities to make informative and customized utterances of pre-trained language models, we utilize BART and GPT-2 as well as transformer-based models. We assess their generation abilities with automatic scores and conduct human evaluations for qualitative results. We examine whether the model reflects adequate persona and knowledge with our proposed two sub-tasks, persona grounding (PG) and knowledge grounding (KG). Moreover, we show that the utterances of our data are constructed with the proper knowledge and persona through grounding quality assessment.
SANVis: Visual Analytics for Understanding Self-Attention Networks
Sep 13, 2019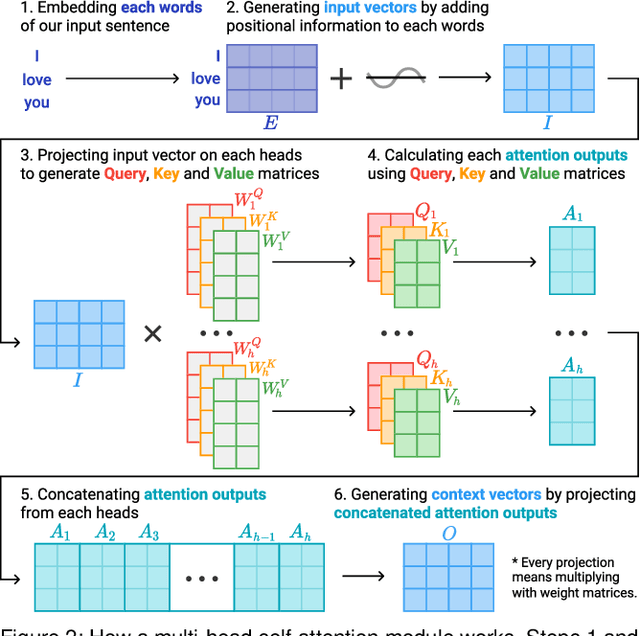
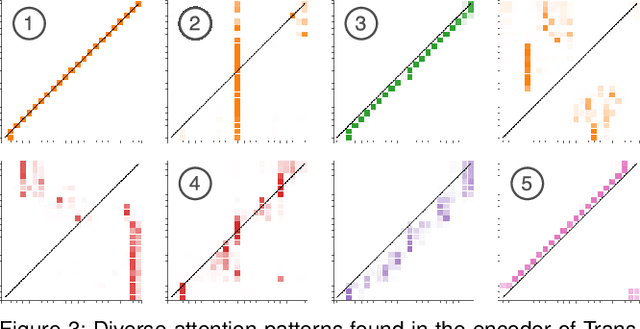
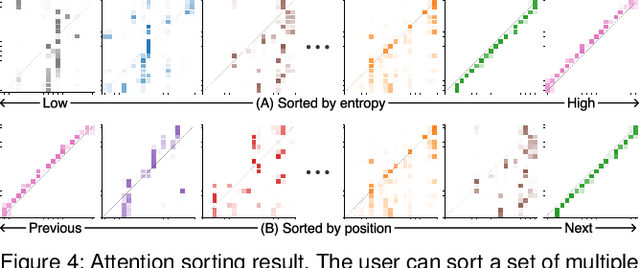
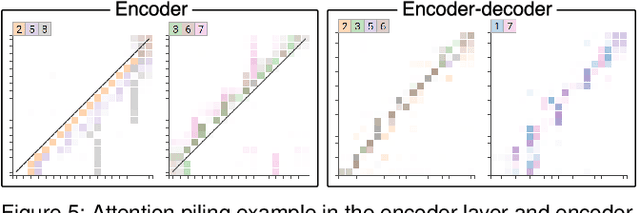
Attention networks, a deep neural network architecture inspired by humans' attention mechanism, have seen significant success in image captioning, machine translation, and many other applications. Recently, they have been further evolved into an advanced approach called multi-head self-attention networks, which can encode a set of input vectors, e.g., word vectors in a sentence, into another set of vectors. Such encoding aims at simultaneously capturing diverse syntactic and semantic features within a set, each of which corresponds to a particular attention head, forming altogether multi-head attention. Meanwhile, the increased model complexity prevents users from easily understanding and manipulating the inner workings of models. To tackle the challenges, we present a visual analytics system called SANVis, which helps users understand the behaviors and the characteristics of multi-head self-attention networks. Using a state-of-the-art self-attention model called Transformer, we demonstrate usage scenarios of SANVis in machine translation tasks. Our system is available at http://short.sanvis.org
Question-Aware Sentence Gating Networks for Question and Answering
Jul 20, 2018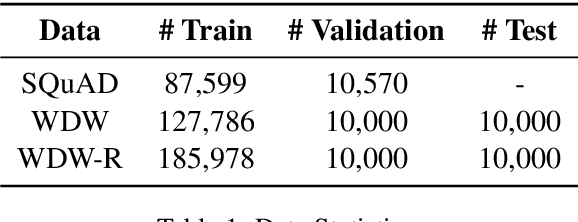
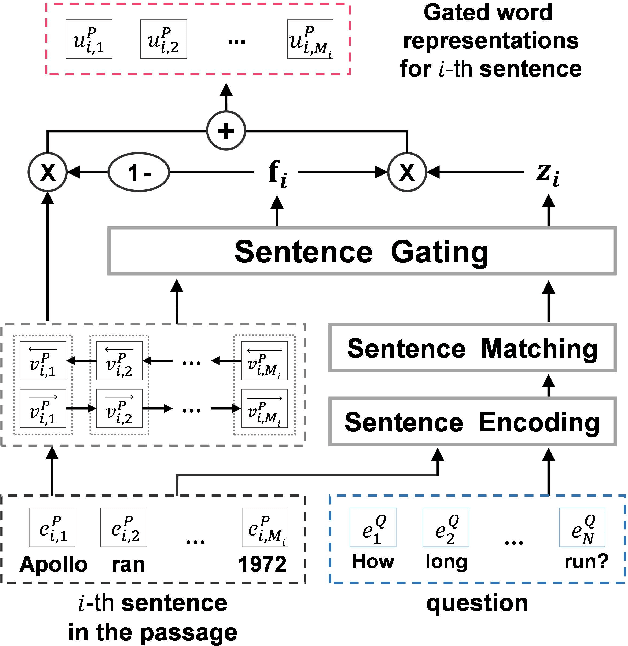
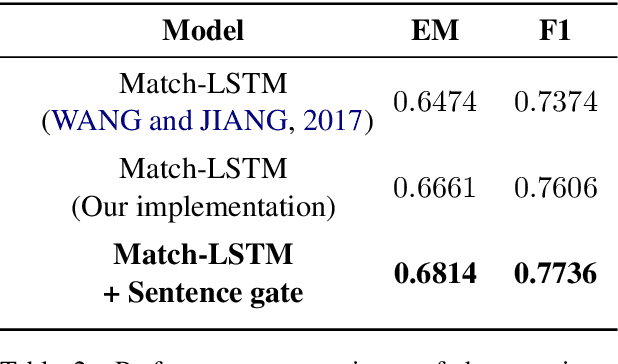
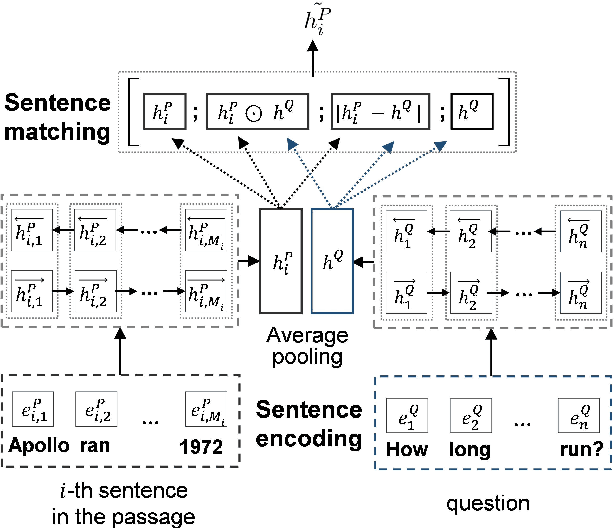
Machine comprehension question answering, which finds an answer to the question given a passage, involves high-level reasoning processes of understanding and tracking the relevant contents across various semantic units such as words, phrases, and sentences in a document. This paper proposes the novel question-aware sentence gating networks that directly incorporate the sentence-level information into word-level encoding processes. To this end, our model first learns question-aware sentence representations and then dynamically combines them with word-level representations, resulting in semantically meaningful word representations for QA tasks. Experimental results demonstrate that our approach consistently improves the accuracy over existing baseline approaches on various QA datasets and bears the wide applicability to other neural network-based QA models.