 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-hoc Utterance Refining Method by Entity Mining for Faithful Knowledge Grounded Conversations
Jun 16, 2024

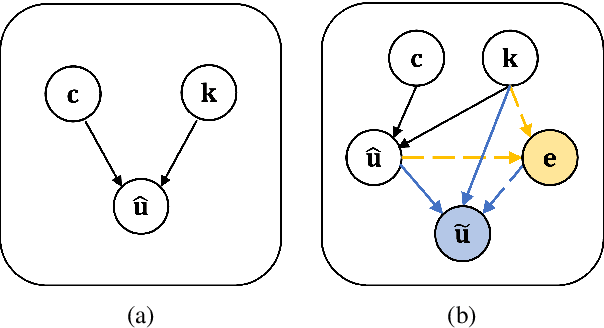
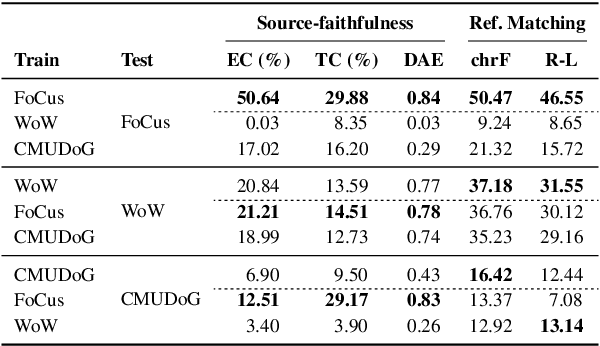
Despite the striking advances in recent language generation performance, model-generated responses have suffered from the chronic problem of hallucinations that are either untrue or unfaithful to a given source. Especially in the task of knowledge grounded conversation, the models are required to generate informative responses, but hallucinated utterances lead to miscommunication. In particular, entity-level hallucination that causes critical misinformation and undesirable conversation is one of the major concerns. To address this issue, we propose a post-hoc refinement method called REM. It aims to enhance the quality and faithfulness of hallucinated utterances by refining them based on the source knowledge. If the generated utterance has a low source-faithfulness score with the given knowledge, REM mines the key entities in the knowledge and implicitly uses them for refining the utterances. We verify that our method reduces entity hallucination in the utterance. Also, we show the adaptability and efficacy of REM with extensive experiments and generative results. Our code is available at https://github.com/YOONNAJANG/REM.
Towards Diverse and Effective Question-Answer Pair Generation from Children Storybooks
Jun 11, 2023Recent advances in QA pair generation (QAG) have raised interest in applying this technique to the educational field. However, the diversity of QA types remains a challenge despite its contributions to comprehensive learning and assessment of children. In this paper, we propose a QAG framework that enhances QA type diversity by producing different interrogative sentences and implicit/explicit answers. Our framework comprises a QFS-based answer generator, an iterative QA generator, and a relevancy-aware ranker. The two generators aim to expand the number of candidates while covering various types. The ranker trained on the in-context negative samples clarifies the top-N outputs based on the ranking score. Extensive evaluations and detailed analyses demonstrate that our approach outperforms previous state-of-the-art results by significant margins, achieving improved diversity and quality. Our task-oriented processes are consistent with real-world demand, which highlights our system's high applicability.
You Truly Understand What I Need: Intellectual and Friendly Dialogue Agents grounding Knowledge and Persona
Jan 06, 2023
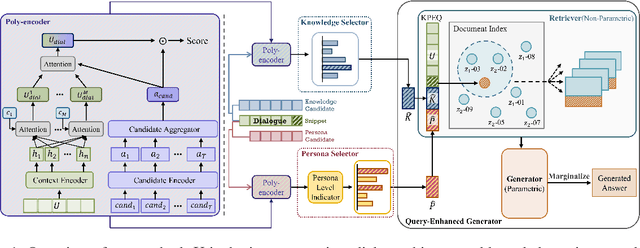


To build a conversational agent that interacts fluently with humans, previous studies blend knowledge or personal profile into the pre-trained language model. However, the model that considers knowledge and persona at the same time is still limited, leading to hallucination and a passive way of using personas. We propose an effective dialogue agent that grounds external knowledge and persona simultaneously. The agent selects the proper knowledge and persona to use for generating the answers with our candidate scoring implemented with a poly-encoder. Then, our model generates the utterance with lesser hallucination and more engagingness utilizing retrieval augmented generation with knowledge-persona enhanced query. We conduct experiments on the persona-knowledge chat and achieve state-of-the-art performance in grounding and generation tasks on the automatic metrics. Moreover, we validate the answers from the models regarding hallucination and engagingness through human evaluation and qualitative results. We show our retriever's effectiveness in extracting relevant documents compared to the other previous retrievers, along with the comparison of multiple candidate scoring methods. Code is available at https://github.com/dlawjddn803/INFO
Call for Customized Conversation: Customized Conversation Grounding Persona and Knowledge
Dec 16, 2021


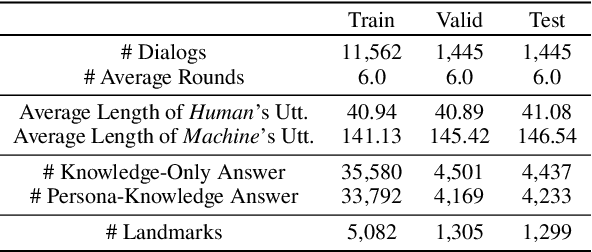
Humans usually have conversations by making use of prior knowledge about a topic and background information of the people whom they are talking to. However, existing conversational agents and datasets do not consider such comprehensive information, and thus they have a limitation in generating the utterances where the knowledge and persona are fused properly. To address this issue, we introduce a call For Customized conversation (FoCus) dataset where the customized answers are built with the user's persona and Wikipedia knowledge. To evaluate the abilities to make informative and customized utterances of pre-trained language models, we utilize BART and GPT-2 as well as transformer-based models. We assess their generation abilities with automatic scores and conduct human evaluations for qualitative results. We examine whether the model reflects adequate persona and knowledge with our proposed two sub-tasks, persona grounding (PG) and knowledge grounding (KG). Moreover, we show that the utterances of our data are constructed with the proper knowledge and persona through grounding quality assessment.