 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget and Explain: Transparent Verification of GNN Unlearning
Dec 08, 2025


Graph neural networks (GNNs) are increasingly used to model complex patterns in graph-structured data. However, enabling them to "forget" designated information remains challenging, especially under privacy regulations such as the GDPR. Existing unlearning methods largely optimize for efficiency and scalability, yet they offer little transparency, and the black-box nature of GNNs makes it difficult to verify whether forgetting has truly occurred. We propose an explainability-driven verifier for GNN unlearning that snapshots the model before and after deletion, using attribution shifts and localized structural changes (for example, graph edit distance) as transparent evidence. The verifier uses five explainability metrics: residual attribution, heatmap shift, explainability score deviation, graph edit distance, and a diagnostic graph rule shift. We evaluate two backbones (GCN, GAT) and four unlearning strategies (Retrain, GraphEditor, GNNDelete, IDEA) across five benchmarks (Cora, Citeseer, Pubmed, Coauthor-CS, Coauthor-Physics). Results show that Retrain and GNNDelete achieve near-complete forgetting, GraphEditor provides partial erasure, and IDEA leaves residual signals. These explanation deltas provide the primary, human-readable evidence of forgetting; we also report membership-inference ROC-AUC as a complementary, graph-wide privacy signal.
Toward Practical Automatic Speech Recognition and Post-Processing: a Call for Explainable Error Benchmark Guideline
Jan 26, 2024Automatic speech recognition (ASR) outcomes serve as input for downstream tasks, substantially impacting the satisfaction level of end-users. Hence, the diagnosis and enhancement of the vulnerabilities present in the ASR model bear significant importance. However, traditional evaluation methodologies of ASR systems generate a singular, composite quantitative metric, which fails to provide comprehensive insight into specific vulnerabilities. This lack of detail extends to the post-processing stage, resulting in further obfuscation of potential weaknesses. Despite an ASR model's ability to recognize utterances accurately, subpar readability can negatively affect user satisfaction, giving rise to a trade-off between recognition accuracy and user-friendliness. To effectively address this, it is imperative to consider both the speech-level, crucial for recognition accuracy, and the text-level, critical for user-friendliness. Consequently, we propose the development of an Error Explainable Benchmark (EEB) dataset. This dataset, while considering both speech- and text-level, enables a granular understanding of the model's shortcomings. Our proposition provides a structured pathway for a more `real-world-centric' evaluation, a marked shift away from abstracted, traditional methods, allowing for the detection and rectification of nuanced system weaknesses, ultimately aiming for an improved user experience.
Towards Diverse and Effective Question-Answer Pair Generation from Children Storybooks
Jun 11, 2023Recent advances in QA pair generation (QAG) have raised interest in applying this technique to the educational field. However, the diversity of QA types remains a challenge despite its contributions to comprehensive learning and assessment of children. In this paper, we propose a QAG framework that enhances QA type diversity by producing different interrogative sentences and implicit/explicit answers. Our framework comprises a QFS-based answer generator, an iterative QA generator, and a relevancy-aware ranker. The two generators aim to expand the number of candidates while covering various types. The ranker trained on the in-context negative samples clarifies the top-N outputs based on the ranking score. Extensive evaluations and detailed analyses demonstrate that our approach outperforms previous state-of-the-art results by significant margins, achieving improved diversity and quality. Our task-oriented processes are consistent with real-world demand, which highlights our system's high applicability.
You Truly Understand What I Need: Intellectual and Friendly Dialogue Agents grounding Knowledge and Persona
Jan 06, 2023
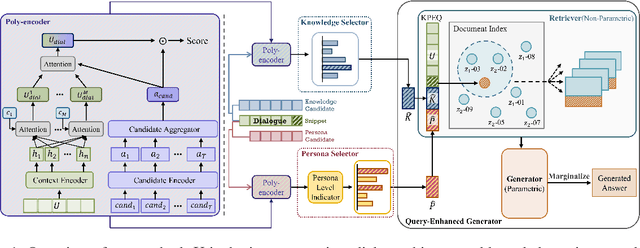


To build a conversational agent that interacts fluently with humans, previous studies blend knowledge or personal profile into the pre-trained language model. However, the model that considers knowledge and persona at the same time is still limited, leading to hallucination and a passive way of using personas. We propose an effective dialogue agent that grounds external knowledge and persona simultaneously. The agent selects the proper knowledge and persona to use for generating the answers with our candidate scoring implemented with a poly-encoder. Then, our model generates the utterance with lesser hallucination and more engagingness utilizing retrieval augmented generation with knowledge-persona enhanced query. We conduct experiments on the persona-knowledge chat and achieve state-of-the-art performance in grounding and generation tasks on the automatic metrics. Moreover, we validate the answers from the models regarding hallucination and engagingness through human evaluation and qualitative results. We show our retriever's effectiveness in extracting relevant documents compared to the other previous retrievers, along with the comparison of multiple candidate scoring methods. Code is available at https://github.com/dlawjddn803/INFO
GRASP: Guiding model with RelAtional Semantics using Prompt
Aug 29, 2022
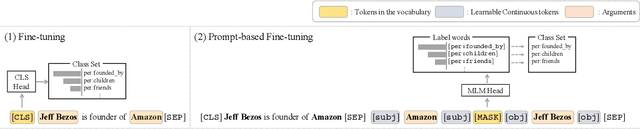
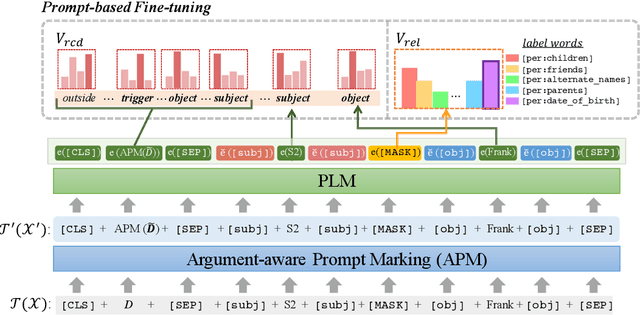

The dialogue-based relation extraction (DialogRE) task aims to predict the relations between argument pairs that appear in dialogue. Most previous studies utilize fine-tuning pre-trained language models (PLMs) only with extensive features to supplement the low information density of the dialogue by multiple speakers. To effectively exploit inherent knowledge of PLMs without extra layers and consider scattered semantic cues on the relation between the arguments, we propose a Guiding model with RelAtional Semantics using Prompt (GRASP). We adopt a prompt-based fine-tuning approach and capture relational semantic clues of a given dialogue with 1) an argument-aware prompt marker strategy and 2) the relational clue detection task. In the experiments, GRASP achieves state-of-the-art performance in terms of both F1 and F1c scores on a DialogRE dataset even though our method only leverages PLMs without adding any extra layers.
Learning source-aware representations of music in a discrete latent space
Nov 26, 2021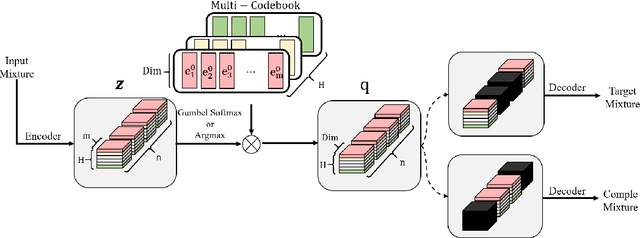
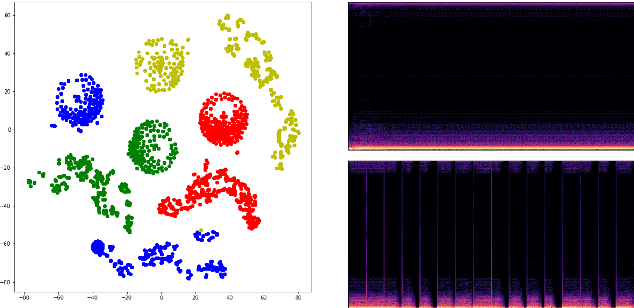
In recent years, neural network based methods have been proposed as a method that cangenerate representations from music, but they are not human readable and hardly analyzable oreditable by a human. To address this issue, we propose a novel method to learn source-awarelatent representations of music through Vector-Quantized Variational Auto-Encoder(VQ-VAE).We train our VQ-VAE to encode an input mixture into a tensor of integers in a discrete latentspace, and design them to have a decomposed structure which allows humans to manipulatethe latent vector in a source-aware manner. This paper also shows that we can generate basslines by estimating latent vectors in a discrete space.
LightSAFT: Lightweight Latent Source Aware Frequency Transform for Source Separation
Nov 24, 2021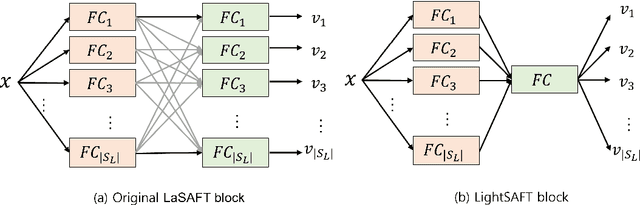

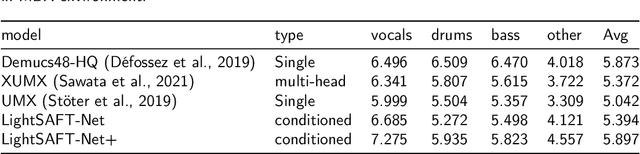
Conditioned source separations have attracted significant attention because of their flexibility, applicability and extensionality. Their performance was usually inferior to the existing approaches, such as the single source separation model. However, a recently proposed method called LaSAFT-Net has shown that conditioned models can show comparable performance against existing single-source separation models. This paper presents LightSAFT-Net, a lightweight version of LaSAFT-Net. As a baseline, it provided a sufficient SDR performance for comparison during the Music Demixing Challenge at ISMIR 2021. This paper also enhances the existing LightSAFT-Net by replacing the LightSAFT blocks in the encoder with TFC-TDF blocks. Our enhanced LightSAFT-Net outperforms the previous one with fewer parameters.