 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Practical Automatic Speech Recognition and Post-Processing: a Call for Explainable Error Benchmark Guideline
Jan 26, 2024Automatic speech recognition (ASR) outcomes serve as input for downstream tasks, substantially impacting the satisfaction level of end-users. Hence, the diagnosis and enhancement of the vulnerabilities present in the ASR model bear significant importance. However, traditional evaluation methodologies of ASR systems generate a singular, composite quantitative metric, which fails to provide comprehensive insight into specific vulnerabilities. This lack of detail extends to the post-processing stage, resulting in further obfuscation of potential weaknesses. Despite an ASR model's ability to recognize utterances accurately, subpar readability can negatively affect user satisfaction, giving rise to a trade-off between recognition accuracy and user-friendliness. To effectively address this, it is imperative to consider both the speech-level, crucial for recognition accuracy, and the text-level, critical for user-friendliness. Consequently, we propose the development of an Error Explainable Benchmark (EEB) dataset. This dataset, while considering both speech- and text-level, enables a granular understanding of the model's shortcomings. Our proposition provides a structured pathway for a more `real-world-centric' evaluation, a marked shift away from abstracted, traditional methods, allowing for the detection and rectification of nuanced system weaknesses, ultimately aiming for an improved user experience.
Synthetic Alone: Exploring the Dark Side of Synthetic Data for Grammatical Error Correction
Jun 26, 2023
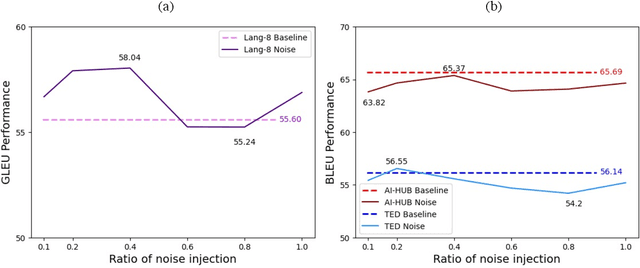


Data-centric AI approach aims to enhance the model performance without modifying the model and has been shown to impact model performance positively. While recent attention has been given to data-centric AI based on synthetic data, due to its potential for performance improvement, data-centric AI has long been exclusively validated using real-world data and publicly available benchmark datasets. In respect of this, data-centric AI still highly depends on real-world data, and the verification of models using synthetic data has not yet been thoroughly carried out. Given the challenges above, we ask the question: Does data quality control (noise injection and balanced data), a data-centric AI methodology acclaimed to have a positive impact, exhibit the same positive impact in models trained solely with synthetic data? To address this question, we conducted comparative analyses between models trained on synthetic and real-world data based on grammatical error correction (GEC) task. Our experimental results reveal that the data quality control method has a positive impact on models trained with real-world data, as previously reported in existing studies, while a negative impact is observed in models trained solely on synthetic data.