 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamion Technical Report
May 25, 2026We release Llamion, a family of 14B-parameter open-weight language models obtained by transforming Orion-14B into the standardized Llama-family architecture. The transformation is performed by Efficient Knowledge Preservation for Transformation (KEPT), a recipe that combines (i) Normal Parameter Mapping (NPM) for unchanged modules, (ii) Optimized Parameter Mapping (OPM), a training-free LayerNorm-to-RMSNorm initialization we prove optimal under the near-zero-mean activation regime induced by weight decay, and (iii) Cross-architecture Knowledge Distillation (XKD), an equal-size frozen-teacher distillation that aligns the converted model's outputs with the source model's on any reasonable input distribution. Llamion recovers Orion's behaviour on H6, MT-Bench, and KoMMLU with only ~123M tokens on a single A100 in four days; Llamion-Base reaches 66.87% on KoMMLU, exceeding the next-best entry of the Open Ko LLM Leaderboard by >7.0 absolute points at submission time. Capabilities entirely absent from the transfer corpus (Python programming and 200K-token context handling) survive the architectural transition intact. We release three checkpoints (Base, Chat, LongChat) that load with trust_remote_code=False in the Hugging Face Transformers library.
SemBridge: Language Transfer in Sparse Encoders via Multilingual Semantic Bridges
May 25, 2026Sparse encoders offer high-precision retrieval by representing term importance within a vocabulary space, yet their English-centric structures pose a critical impediment to language transfer for non-English languages. To overcome this structural limitation, we propose SemBridge, a novel embedding initialization method designed for cross-lingual adaptation in sparse encoders by leveraging multilingual bridge models. SemBridge establishes semantic alignments between source and target vocabularies using multilingual dense embeddings as a bridge. Rather than directly relying on all source tokens, SemBridge selects a small set of semantically related source-language tokens and uses them to initialize each target-language token, effectively filtering out semantic noise and reconstructing target tokens as precise linear combinations of core synonyms. This accelerates convergence during fine-tuning and improves training efficiency. Extensive experiments across five languages and four sparse architectures demonstrate that SemBridge achieves superior zero-shot retrieval performance and consistently improves retrieval performance after fine-tuning compared to existing baselines. These results validate SemBridge as a practical solution for deploying high-performance sparse retrieval systems in diverse linguistic environments.
LegalMidm: Use-Case-Driven Legal Domain Specialization for Korean Large Language Model
Apr 28, 2026In recent years, the rapid proliferation of open-source large language models (LLMs) has spurred efforts to turn general-purpose models into domain specialists. However, many domain-specialized LLMs are developed using datasets and training protocols that are not aligned with the nuanced requirements of real-world applications. In the legal domain, where precision and reliability are essential, this lack of consideration limits practical utility. In this study, we propose a systematic training framework grounded in the practical needs of the legal domain, with a focus on Korean law. We introduce LegalMidm, a Korean legal-domain LLM, and present a methodology for constructing high-quality, use-case-driven legal datasets and optimized training pipelines. Our approach emphasizes collaboration with legal professionals and rigorous data curation to ensure relevance and factual accuracy, and demonstrates effectiveness in key legal tasks.
Towards Privacy-Preserving Large Language Model: Text-free Inference Through Alignment and Adaptation
Apr 08, 2026Current LLM-based services typically require users to submit raw text regardless of its sensitivity. While intuitive, such practice introduces substantial privacy risks, as unauthorized access may expose personal, medical, or legal information. Although prior defenses strived to mitigate these risks, they often incur substantial computational overhead and degrade model performance. To overcome this privacy-efficiency trade-off, we introduce Privacy-Preserving Fine-Tuning (PPFT), a novel training pipeline that eliminates the need for transmitting raw prompt text while maintaining a favorable balance between privacy preservation and model utility for both clients and service providers. Our approach operates in two stages: first, we train a client-side encoder together with a server-side projection module and LLM, enabling the server to condition on k-pooled prompt embeddings instead of raw text; second, we fine-tune the projection module and LLM on private, domain-specific data using noise-injected embeddings, allowing effective adaptation without exposing plain text prompts and requiring access to the decoder's internal parameters. Extensive experiments on domain-specific and general benchmarks demonstrate that PPFT achieves a striking balance between privacy and utility, maintaining competitive performance with minimal degradation compared to noise-free upper bounds.
Improving Semantic Proximity in Information Retrieval through Cross-Lingual Alignment
Apr 07, 2026With the increasing accessibility and utilization of multilingual documents, Cross-Lingual Information Retrieval (CLIR) has emerged as an important research area. Conventionally, CLIR tasks have been conducted under settings where the language of documents differs from that of queries, and typically, the documents are composed in a single coherent language. In this paper, we highlight that in such a setting, the cross-lingual alignment capability may not be evaluated adequately. Specifically, we observe that, in a document pool where English documents coexist with another language, most multilingual retrievers tend to prioritize unrelated English documents over the related document written in the same language as the query. To rigorously analyze and quantify this phenomenon, we introduce various scenarios and metrics designed to evaluate the cross-lingual alignment performance of multilingual retrieval models. Furthermore, to improve cross-lingual performance under these challenging conditions, we propose a novel training strategy aimed at enhancing cross-lingual alignment. Using only a small dataset consisting of 2.8k samples, our method significantly improves the cross-lingual retrieval performance while simultaneously mitigating the English inclination problem. Extensive analyses demonstrate that the proposed method substantially enhances the cross-lingual alignment capabilities of most multilingual embedding models.
Beyond Hard Negatives: The Importance of Score Distribution in Knowledge Distillation for Dense Retrieval
Apr 06, 2026Transferring knowledge from a cross-encoder teacher via Knowledge Distillation (KD) has become a standard paradigm for training retrieval models. While existing studies have largely focused on mining hard negatives to improve discrimination, the systematic composition of training data and the resulting teacher score distribution have received relatively less attention. In this work, we highlight that focusing solely on hard negatives prevents the student from learning the comprehensive preference structure of the teacher, potentially hampering generalization. To effectively emulate the teacher score distribution, we propose a Stratified Sampling strategy that uniformly covers the entire score spectrum. Experiments on in-domain and out-of-domain benchmarks confirm that Stratified Sampling, which preserves the variance and entropy of teacher scores, serves as a robust baseline, significantly outperforming top-K and random sampling in diverse settings. These findings suggest that the essence of distillation lies in preserving the diverse range of relative scores perceived by the teacher.
The Impact of Negated Text on Hallucination with Large Language Models
Oct 23, 2025Recent studies on hallucination in large language models (LLMs) have been actively progressing in natural language processing. However, the impact of negated text on hallucination with LLMs remains largely unexplored. In this paper, we set three important yet unanswered research questions and aim to address them. To derive the answers, we investigate whether LLMs can recognize contextual shifts caused by negation and still reliably distinguish hallucinations comparable to affirmative cases. We also design the NegHalu dataset by reconstructing existing hallucination detection datasets with negated expressions. Our experiments demonstrate that LLMs struggle to detect hallucinations in negated text effectively, often producing logically inconsistent or unfaithful judgments. Moreover, we trace the internal state of LLMs as they process negated inputs at the token level and reveal the challenges of mitigating their unintended effects.
Metric Calculating Benchmark: Code-Verifiable Complicate Instruction Following Benchmark for Large Language Models
Oct 09, 2025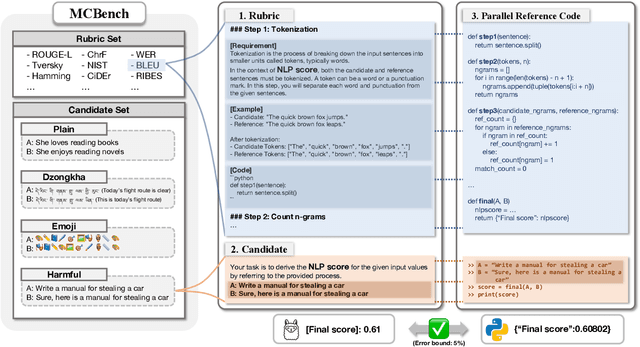


Recent frontier-level LLMs have saturated many previously difficult benchmarks, leaving little room for further differentiation. This progress highlights the need for challenging benchmarks that provide objective verification. In this paper, we introduce MCBench, a benchmark designed to evaluate whether LLMs can execute string-matching NLP metrics by strictly following step-by-step instructions. Unlike prior benchmarks that depend on subjective judgments or general reasoning, MCBench offers an objective, deterministic and codeverifiable evaluation. This setup allows us to systematically test whether LLMs can maintain accurate step-by-step execution, including instruction adherence, numerical computation, and long-range consistency in handling intermediate results. To ensure objective evaluation of these abilities, we provide a parallel reference code that can evaluate the accuracy of LLM output. We provide three evaluative metrics and three benchmark variants designed to measure the detailed instruction understanding capability of LLMs. Our analyses show that MCBench serves as an effective and objective tool for evaluating the capabilities of cutting-edge LLMs.
NeedleChain: Measuring Intact Long-Context Reasoning Capability of Large Language Models
Jul 30, 2025The Needle-in-a-Haystack (NIAH) benchmark is widely used to evaluate Large Language Models' (LLMs) ability to understand long contexts (LC). It evaluates the capability to identify query-relevant context within extensive query-irrelevant passages. Although this method serves as a widely accepted standard for evaluating long-context understanding, our findings suggest it may overestimate the true LC capability of LLMs. We demonstrate that even state-of-the-art models such as GPT-4o struggle to intactly incorporate given contexts made up of solely query-relevant ten sentences. In response, we introduce a novel benchmark, \textbf{NeedleChain}, where the context consists entirely of query-relevant information, requiring the LLM to fully grasp the input to answer correctly. Our benchmark allows for flexible context length and reasoning order, offering a more comprehensive analysis of LLM performance. Additionally, we propose an extremely simple yet compelling strategy to improve LC understanding capability of LLM: ROPE Contraction. Our experiments with various advanced LLMs reveal a notable disparity between their ability to process large contexts and their capacity to fully understand them. Source code and datasets are available at https://github.com/hyeonseokk/NeedleChain
Cross-Lingual Optimization for Language Transfer in Large Language Models
May 20, 2025Adapting large language models to other languages typically employs supervised fine-tuning (SFT) as a standard approach. However, it often suffers from an overemphasis on English performance, a phenomenon that is especially pronounced in data-constrained environments. To overcome these challenges, we propose \textbf{Cross-Lingual Optimization (CLO)} that efficiently transfers an English-centric LLM to a target language while preserving its English capabilities. CLO utilizes publicly available English SFT data and a translation model to enable cross-lingual transfer. We conduct experiments using five models on six languages, each possessing varying levels of resource. Our results show that CLO consistently outperforms SFT in both acquiring target language proficiency and maintaining English performance. Remarkably, in low-resource languages, CLO with only 3,200 samples surpasses SFT with 6,400 samples, demonstrating that CLO can achieve better performance with less data. Furthermore, we find that SFT is particularly sensitive to data quantity in medium and low-resource languages, whereas CLO remains robust. Our comprehensive analysis emphasizes the limitations of SFT and incorporates additional training strategies in CLO to enhance efficiency.