 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamion Technical Report
May 25, 2026We release Llamion, a family of 14B-parameter open-weight language models obtained by transforming Orion-14B into the standardized Llama-family architecture. The transformation is performed by Efficient Knowledge Preservation for Transformation (KEPT), a recipe that combines (i) Normal Parameter Mapping (NPM) for unchanged modules, (ii) Optimized Parameter Mapping (OPM), a training-free LayerNorm-to-RMSNorm initialization we prove optimal under the near-zero-mean activation regime induced by weight decay, and (iii) Cross-architecture Knowledge Distillation (XKD), an equal-size frozen-teacher distillation that aligns the converted model's outputs with the source model's on any reasonable input distribution. Llamion recovers Orion's behaviour on H6, MT-Bench, and KoMMLU with only ~123M tokens on a single A100 in four days; Llamion-Base reaches 66.87% on KoMMLU, exceeding the next-best entry of the Open Ko LLM Leaderboard by >7.0 absolute points at submission time. Capabilities entirely absent from the transfer corpus (Python programming and 200K-token context handling) survive the architectural transition intact. We release three checkpoints (Base, Chat, LongChat) that load with trust_remote_code=False in the Hugging Face Transformers library.
Post-hoc Utterance Refining Method by Entity Mining for Faithful Knowledge Grounded Conversations
Jun 16, 2024

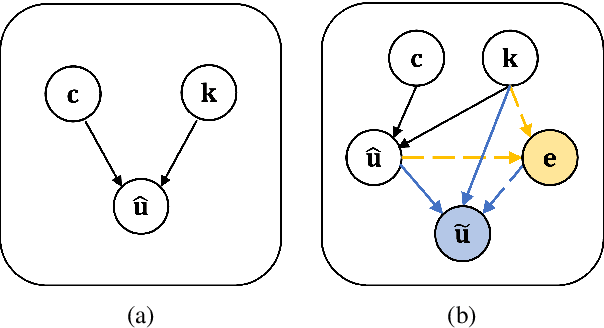
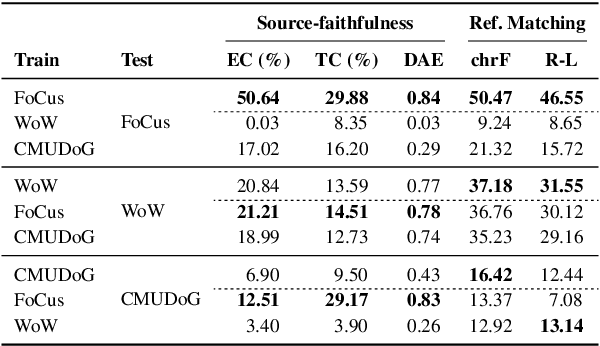
Despite the striking advances in recent language generation performance, model-generated responses have suffered from the chronic problem of hallucinations that are either untrue or unfaithful to a given source. Especially in the task of knowledge grounded conversation, the models are required to generate informative responses, but hallucinated utterances lead to miscommunication. In particular, entity-level hallucination that causes critical misinformation and undesirable conversation is one of the major concerns. To address this issue, we propose a post-hoc refinement method called REM. It aims to enhance the quality and faithfulness of hallucinated utterances by refining them based on the source knowledge. If the generated utterance has a low source-faithfulness score with the given knowledge, REM mines the key entities in the knowledge and implicitly uses them for refining the utterances. We verify that our method reduces entity hallucination in the utterance. Also, we show the adaptability and efficacy of REM with extensive experiments and generative results. Our code is available at https://github.com/YOONNAJANG/REM.
KoBigBird-large: Transformation of Transformer for Korean Language Understanding
Sep 19, 2023This work presents KoBigBird-large, a large size of Korean BigBird that achieves state-of-the-art performance and allows long sequence processing for Korean language understanding. Without further pretraining, we only transform the architecture and extend the positional encoding with our proposed Tapered Absolute Positional Encoding Representations (TAPER). In experiments, KoBigBird-large shows state-of-the-art overall performance on Korean language understanding benchmarks and the best performance on document classification and question answering tasks for longer sequences against the competitive baseline models. We publicly release our model here.
Who says like a style of Vitamin: Towards Syntax-Aware DialogueSummarization using Multi-task Learning
Sep 29, 2021
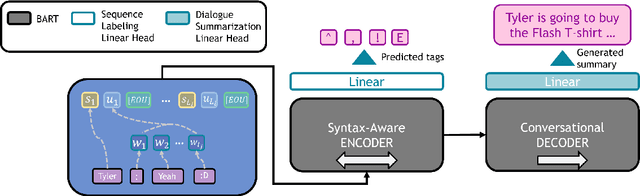
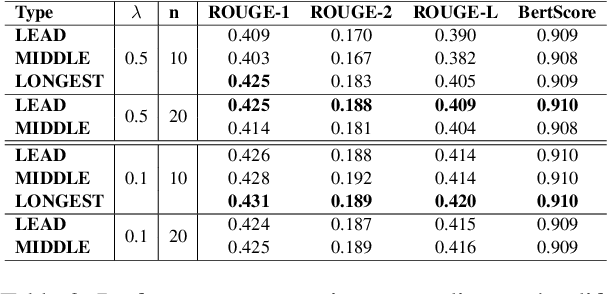
Abstractive dialogue summarization is a challenging task for several reasons. First, most of the important pieces of information in a conversation are scattered across utterances through multi-party interactions with different textual styles. Second, dialogues are often informal structures, wherein different individuals express personal perspectives, unlike text summarization, tasks that usually target formal documents such as news articles. To address these issues, we focused on the association between utterances from individual speakers and unique syntactic structures. Speakers have unique textual styles that can contain linguistic information, such as voiceprint. Therefore, we constructed a syntax-aware model by leveraging linguistic information (i.e., POS tagging), which alleviates the above issues by inherently distinguishing sentences uttered from individual speakers. We employed multi-task learning of both syntax-aware information and dialogue summarization. To the best of our knowledge, our approach is the first method to apply multi-task learning to the dialogue summarization task. Experiments on a SAMSum corpus (a large-scale dialogue summarization corpus) demonstrated that our method improved upon the vanilla model. We further analyze the costs and benefits of our approach relative to baseline models.
PicTalky: Augmentative and Alternative Communication Software for Language Developmental Disabilities
Sep 27, 2021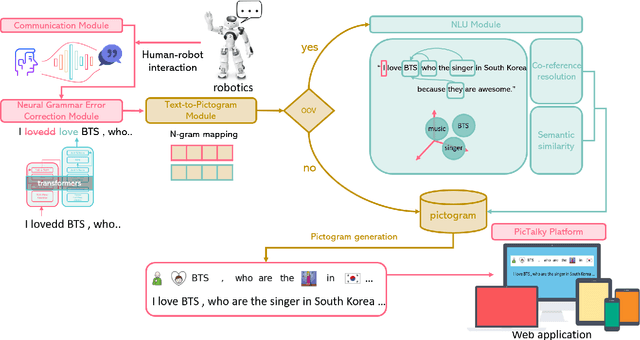

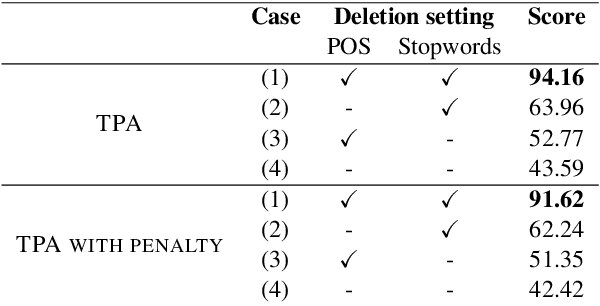
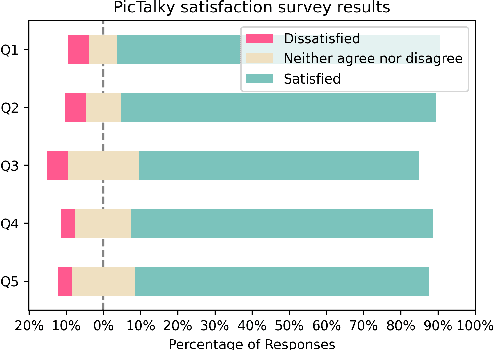
Augmentative and alternative communication (AAC) is a practical means of communication for people with language disabilities. In this study, we propose PicTalky, which is an AI-based AAC system that helps children with language developmental disabilities to improve their communication skills and language comprehension abilities. PicTalky can process both text and pictograms more accurately by connecting a series of neural-based NLP modules. Moreover, we perform quantitative and qualitative analyses on the essential features of PicTalky. It is expected that those suffering from language problems will be able to express their intentions or desires more easily and improve their quality of life by using this service. We have made the models freely available alongside a demonstration of the Web interface. Furthermore, we implemented robotics AAC for the first time by applying PicTalky to the NAO robot.
I Know What You Asked: Graph Path Learning using AMR for Commonsense Reasoning
Nov 06, 2020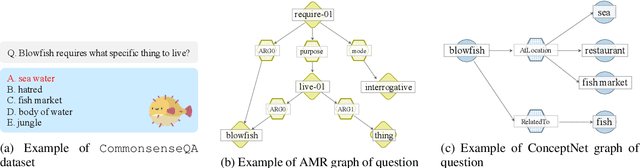
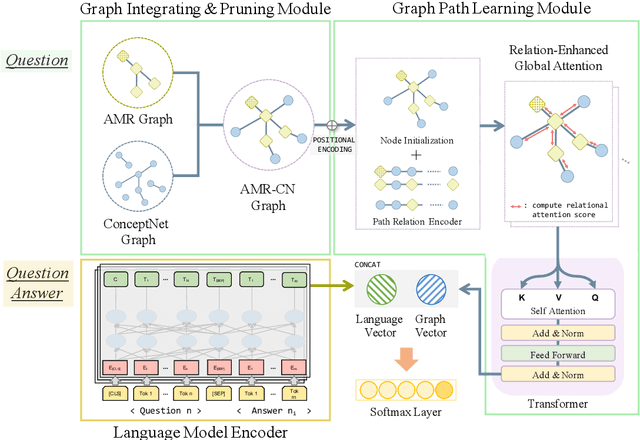
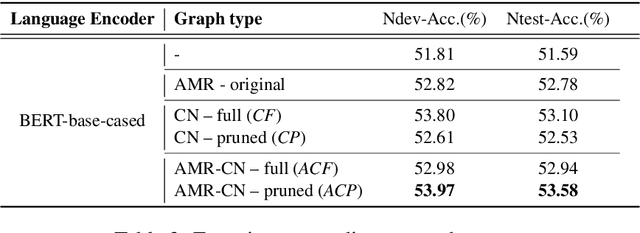
CommonsenseQA is a task in which a correct answer is predicted through commonsense reasoning with pre-defined knowledge. Most previous works have aimed to improve the performance with distributed representation without considering the process of predicting the answer from the semantic representation of the question. To shed light upon the semantic interpretation of the question, we propose an AMR-ConceptNet-Pruned (ACP) graph. The ACP graph is pruned from a full integrated graph encompassing Abstract Meaning Representation (AMR) graph generated from input questions and an external commonsense knowledge graph, ConceptNet (CN). Then the ACP graph is exploited to interpret the reasoning path as well as to predict the correct answer on the CommonsenseQA task. This paper presents the manner in which the commonsense reasoning process can be interpreted with the relations and concepts provided by the ACP graph. Moreover, ACP-based models are shown to outperform the baselines.
Domain Adaptive Training BERT for Response Selection
Aug 13, 2019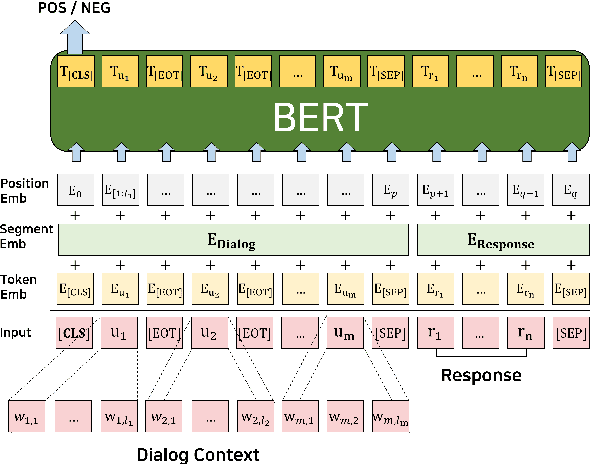
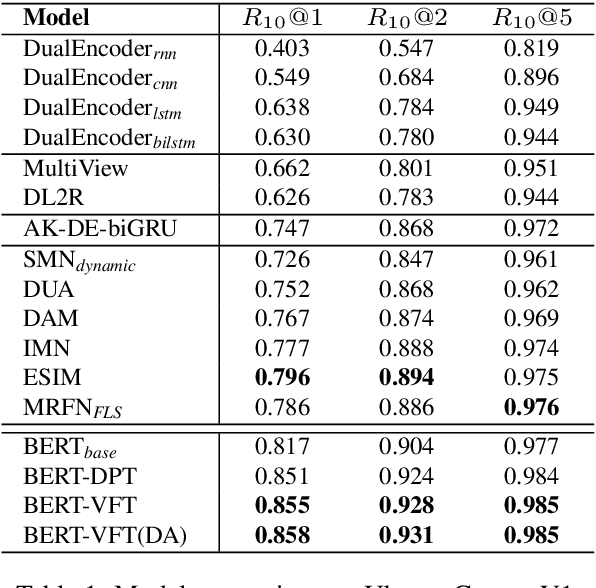
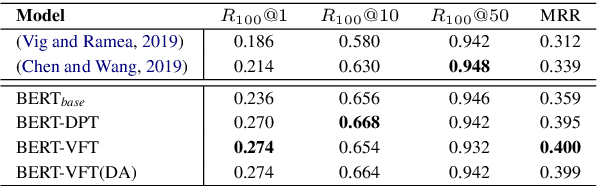
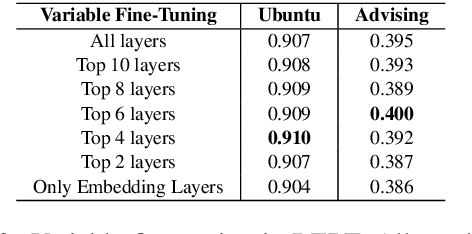
We focus on multi-turn response selection in a retrieval-based dialog system. In this paper, we utilize the powerful pre-trained language model Bi-directional Encoder Representations from Transformer (BERT) for a multi-turn dialog system and propose a highly effective post-training method on domain-specific corpus. Although BERT is easily adopted to various NLP tasks and outperforms previous baselines of each task, it still has limitations if a task corpus is too focused on a certain domain. Post-training on domain-specific corpus (e.g., Ubuntu Corpus) helps the model to train contextualized representations and words that do not appear in general corpus (e.g.,English Wikipedia). Experiment results show that our approach achieves new state-of-the-art on two response selection benchmark datasets (i.e.,Ubuntu Corpus V1, Advising Corpus) performance improvement by 5.9% and 6% on Recall@1.
EmotionX-KU: BERT-Max based Contextual Emotion Classifier
Jun 27, 2019
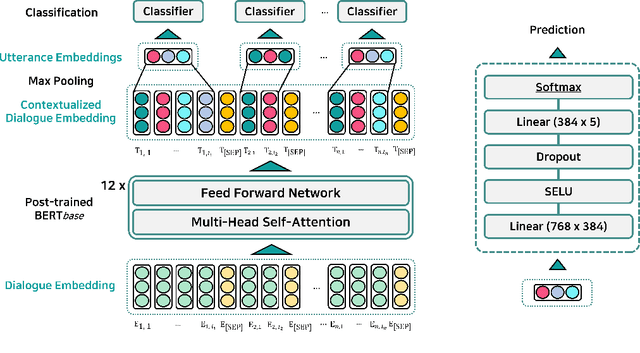


We propose a contextual emotion classifier based on a transferable language model and dynamic max pooling, which predicts the emotion of each utterance in a dialogue. A representative emotion analysis task, EmotionX, requires to consider contextual information from colloquial dialogues and to deal with a class imbalance problem. To alleviate these problems, our model leverages the self-attention based transferable language model and the weighted cross entropy loss. Furthermore, we apply post-training and fine-tuning mechanisms to enhance the domain adaptability of our model and utilize several machine learning techniques to improve its performance. We conduct experiments on two emotion-labeled datasets named Friends and EmotionPush. As a result, our model outperforms the previous state-of-the-art model and also shows competitive performance in the EmotionX 2019 challenge. The code will be available in the Github page.