 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUE-M: Contextual Understanding and Enhanced Search with Multimodal Large Language Model
Nov 19, 2024
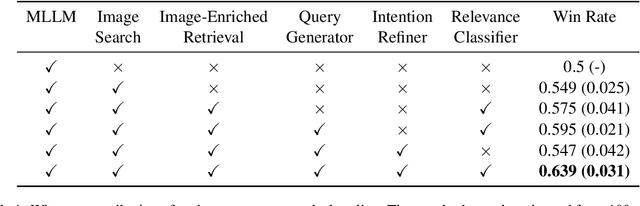
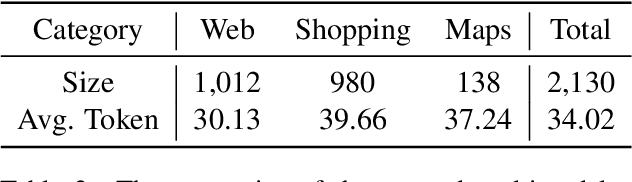
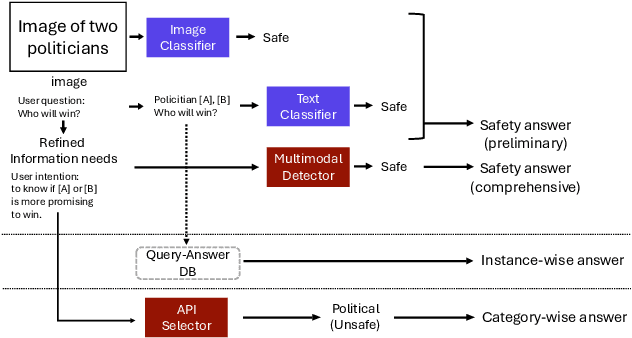
The integration of Retrieval-Augmented Generation (RAG) with Multimodal Large Language Models (MLLMs) has expanded the scope of multimodal query resolution. However, current systems struggle with intent understanding, information retrieval, and safety filtering, limiting their effectiveness. This paper introduces Contextual Understanding and Enhanced Search with MLLM (CUE-M), a novel multimodal search pipeline that addresses these challenges through a multi-stage framework comprising image context enrichment, intent refinement, contextual query generation, external API integration, and relevance-based filtering. CUE-M incorporates a robust safety framework combining image-based, text-based, and multimodal classifiers, dynamically adapting to instance- and category-specific risks. Evaluations on a multimodal Q&A dataset and a public safety benchmark demonstrate that CUE-M outperforms baselines in accuracy, knowledge integration, and safety, advancing the capabilities of multimodal retrieval systems.
Towards Reliable and Fluent Large Language Models: Incorporating Feedback Learning Loops in QA Systems
Sep 08, 2023Large language models (LLMs) have emerged as versatile tools in various daily applications. However, they are fraught with issues that undermine their utility and trustworthiness. These include the incorporation of erroneous references (citation), the generation of hallucinated information (correctness), and the inclusion of superfluous or omission of crucial details (fluency). To ameliorate these concerns, this study makes several key contributions. First, we build a dataset to train a critic model capable of evaluating the citation, correctness, and fluency of responses generated by LLMs in QA systems. Second, we propose an automated feedback mechanism that leverages the critic model to offer real-time feedback on heterogeneous aspects of generated text. Third, we introduce a feedback learning loop that uses this critic model to iteratively improve the performance of the LLM responsible for response generation. Experimental results demonstrate the efficacy of our approach, showing substantial improvements in citation and fluency metrics for ChatGPT, including a 4% precision increase in citation and an approximately 8% enhancement in the MAUVE metric for fluency, while maintaining high levels of correctness.
Deep Context- and Relation-Aware Learning for Aspect-based Sentiment Analysis
Jun 07, 2021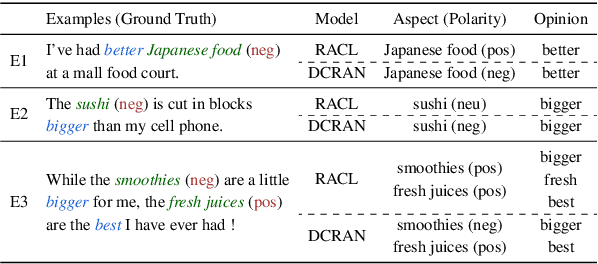
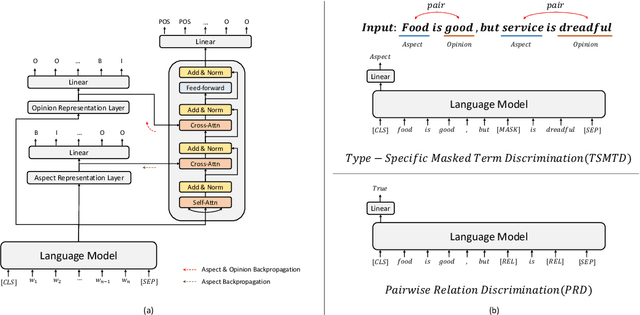
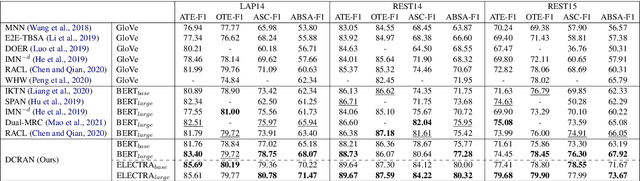
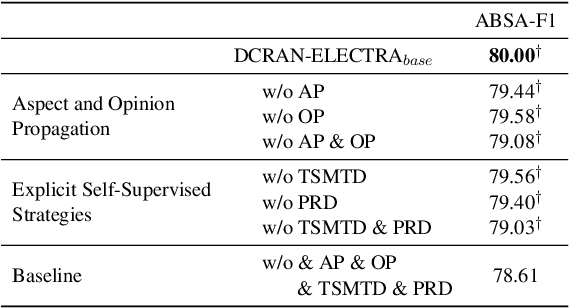
Existing works for aspect-based sentiment analysis (ABSA) have adopted a unified approach, which allows the interactive relations among subtasks. However, we observe that these methods tend to predict polarities based on the literal meaning of aspect and opinion terms and mainly consider relations implicitly among subtasks at the word level. In addition, identifying multiple aspect-opinion pairs with their polarities is much more challenging. Therefore, a comprehensive understanding of contextual information w.r.t. the aspect and opinion are further required in ABSA. In this paper, we propose Deep Contextualized Relation-Aware Network (DCRAN), which allows interactive relations among subtasks with deep contextual information based on two modules (i.e., Aspect and Opinion Propagation and Explicit Self-Supervised Strategies). Especially, we design novel self-supervised strategies for ABSA, which have strengths in dealing with multiple aspects. Experimental results show that DCRAN significantly outperforms previous state-of-the-art methods by large margins on three widely used benchmarks.
Auxiliary Sequence Labeling Tasks for Disfluency Detection
Oct 24, 2020
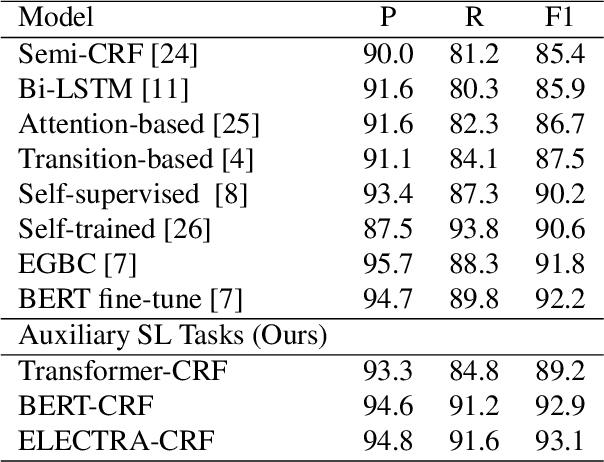
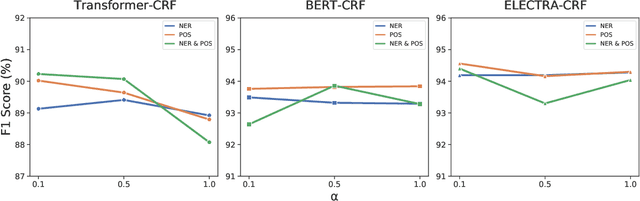
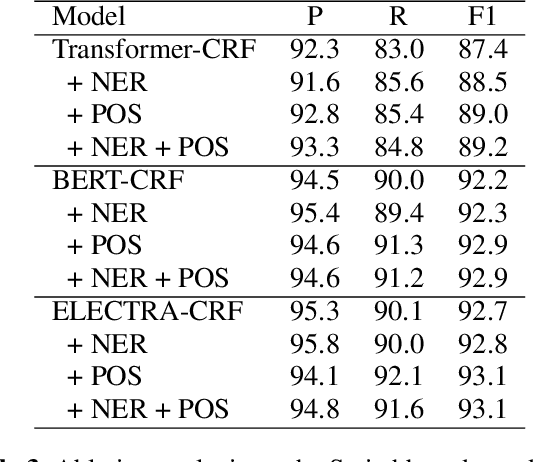
Detecting disfluencies in spontaneous speech is an important preprocessing step in natural language processing and speech recognition applications. In this paper, we propose a method utilizing named entity recognition (NER) and part-of-speech (POS) as auxiliary sequence labeling (SL) tasks for disfluency detection. First, we show that training a disfluency detection model with auxiliary SL tasks can improve its F-score in disfluency detection. Then, we analyze which auxiliary SL tasks are influential depending on baseline models. Experimental results on the widely used English Switchboard dataset show that our method outperforms the previous state-of-the-art in disfluency detection.
Do Response Selection Models Really Know What's Next? Utterance Manipulation Strategies for Multi-turn Response Selection
Sep 10, 2020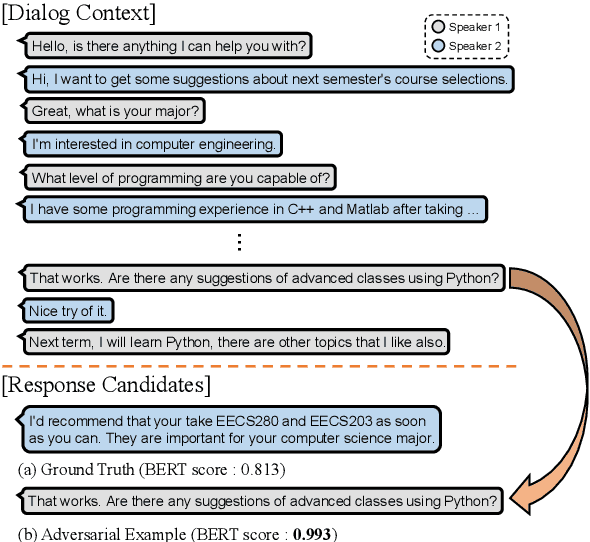

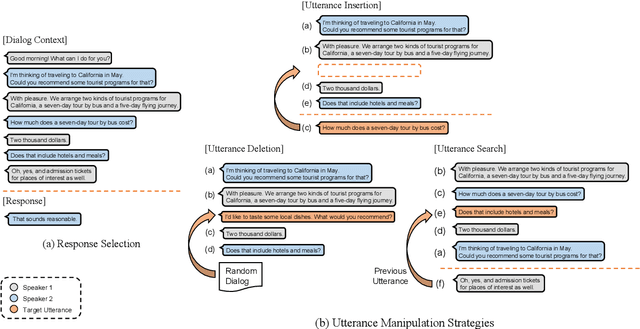
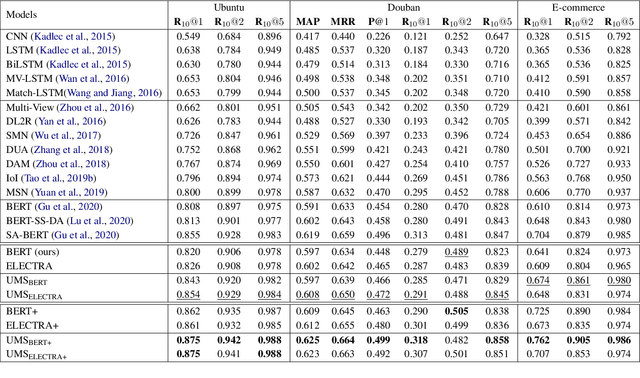
In this paper, we study the task of selecting optimal response given user and system utterance history in retrieval-based multi-turn dialog systems. Recently, pre-trained language models (e.g., BERT, RoBERTa, and ELECTRA) have shown significant improvements in various natural language processing tasks. This and similar response selection tasks can also be solved using such language models by formulating them as dialog-response binary classification tasks. Although existing works using this approach successfully obtained state-of-the-art results, we observe that language models trained in this manner tend to make predictions based on the relatedness of history and candidates, ignoring the sequential nature of multi-turn dialog systems. This suggests that the response selection task alone is insufficient in learning temporal dependencies between utterances. To this end, we propose utterance manipulation strategies (UMS) to address this problem. Specifically, UMS consist of several strategies (i.e., insertion, deletion, and search), which aid the response selection model towards maintaining dialog coherence. Further, UMS are self-supervised methods that do not require additional annotation and thus can be easily incorporated into existing approaches. Extensive evaluation across multiple languages and models shows that UMS are highly effective in teaching dialog consistency, which lead to models pushing the state-of-the-art with significant margins on multiple public benchmark datasets.
Multi-View Attention Networks for Visual Dialog
Apr 29, 2020



Visual dialog is a challenging vision-language task in which a series of questions visually grounded by a given image are answered. To resolve the visual dialog task, a high-level understanding of various multimodal inputs (e.g., question, dialog history, image, and answer) is required. Specifically, it is necessary for an agent to 1) understand question-relevant dialog history and 2) focus on question-relevant visual contents among the diverse visual contents in a given image. In this paper, we propose Multi-View Attention Network (MVAN), which considers complementary views of multimodal inputs based on attention mechanisms. MVAN effectively captures the question-relevant information from the dialog history with two different textual-views (i.e., Topic Aggregation and Context Matching), and integrates multimodal representations with two-step fusion process. Experimental results on VisDial v1.0 and v0.9 benchmarks show the effectiveness of our proposed model, which outperforms the previous state-of-the-art methods with respect to all evaluation metrics.
Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization
Apr 29, 2020
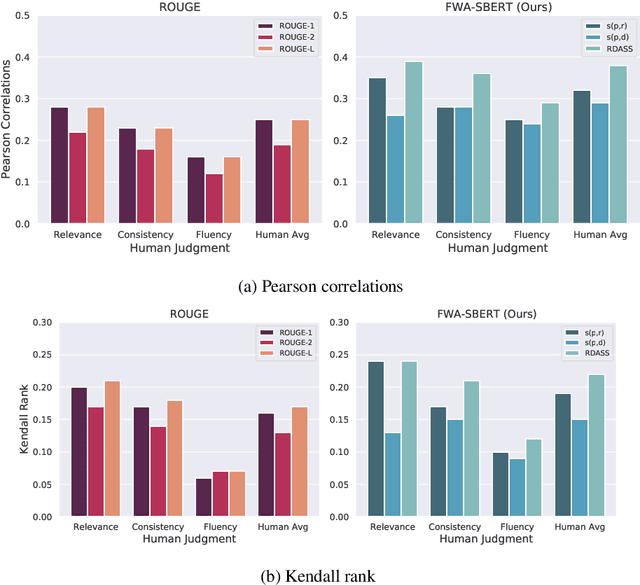

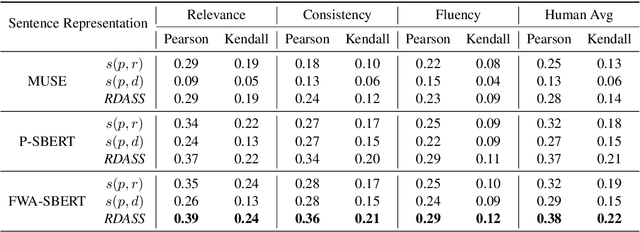
Text summarization refers to the process that generates a shorter form of text from the source document preserving salient information. Recently, many models for text summarization have been proposed. Most of those models were evaluated using recall-oriented understudy for gisting evaluation (ROUGE) scores. However, as ROUGE scores are computed based on n-gram overlap, they do not reflect semantic meaning correspondences between generated and reference summaries. Because Korean is an agglutinative language that combines various morphemes into a word that express several meanings, ROUGE is not suitable for Korean summarization. In this paper, we propose evaluation metrics that reflect semantic meanings of a reference summary and the original document, Reference and Document Aware Semantic Score (RDASS). We then propose a method for improving the correlation of the metrics with human judgment. Evaluation results show that the correlation with human judgment is significantly higher for our evaluation metrics than for ROUGE scores.
Domain Adaptive Training BERT for Response Selection
Aug 13, 2019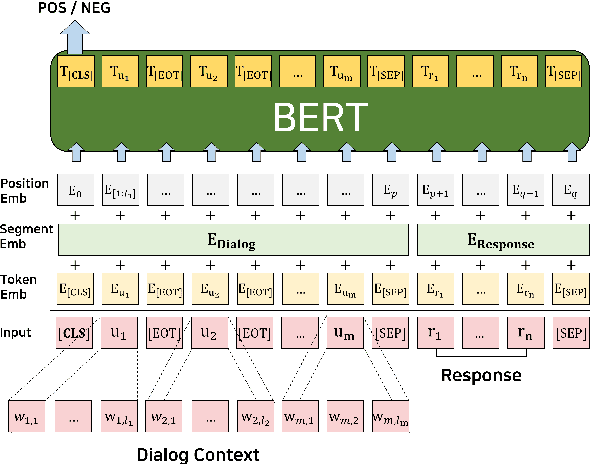
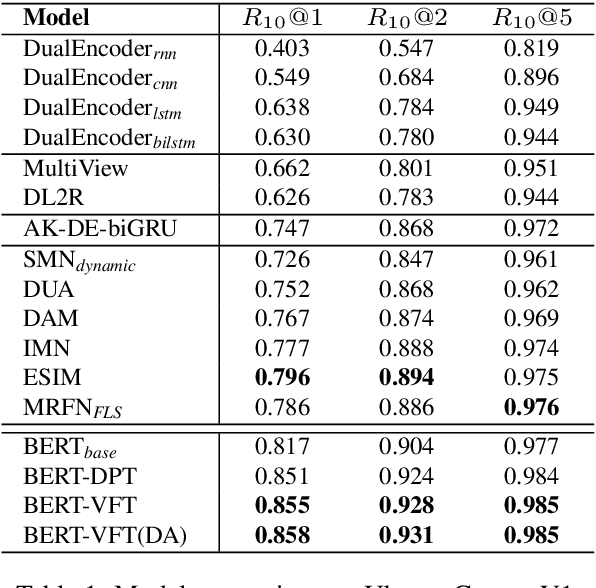
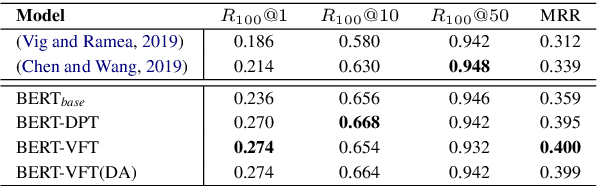
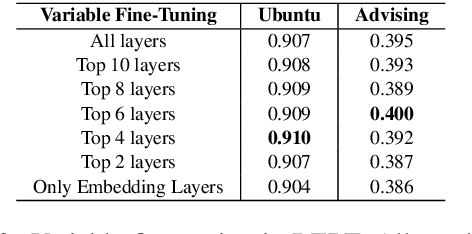
We focus on multi-turn response selection in a retrieval-based dialog system. In this paper, we utilize the powerful pre-trained language model Bi-directional Encoder Representations from Transformer (BERT) for a multi-turn dialog system and propose a highly effective post-training method on domain-specific corpus. Although BERT is easily adopted to various NLP tasks and outperforms previous baselines of each task, it still has limitations if a task corpus is too focused on a certain domain. Post-training on domain-specific corpus (e.g., Ubuntu Corpus) helps the model to train contextualized representations and words that do not appear in general corpus (e.g.,English Wikipedia). Experiment results show that our approach achieves new state-of-the-art on two response selection benchmark datasets (i.e.,Ubuntu Corpus V1, Advising Corpus) performance improvement by 5.9% and 6% on Recall@1.
EmotionX-KU: BERT-Max based Contextual Emotion Classifier
Jun 27, 2019
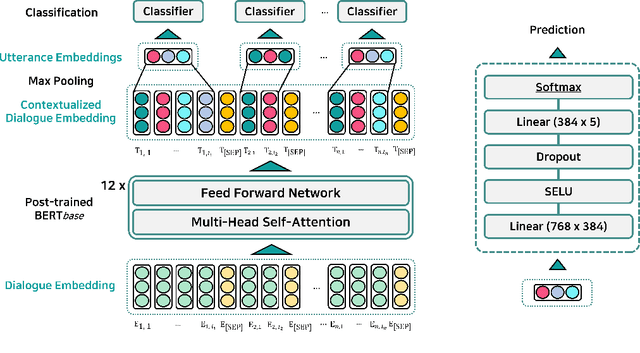


We propose a contextual emotion classifier based on a transferable language model and dynamic max pooling, which predicts the emotion of each utterance in a dialogue. A representative emotion analysis task, EmotionX, requires to consider contextual information from colloquial dialogues and to deal with a class imbalance problem. To alleviate these problems, our model leverages the self-attention based transferable language model and the weighted cross entropy loss. Furthermore, we apply post-training and fine-tuning mechanisms to enhance the domain adaptability of our model and utilize several machine learning techniques to improve its performance. We conduct experiments on two emotion-labeled datasets named Friends and EmotionPush. As a result, our model outperforms the previous state-of-the-art model and also shows competitive performance in the EmotionX 2019 challenge. The code will be available in the Github page.