 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinq-Embed-Mistral Technical Report
Dec 04, 2024
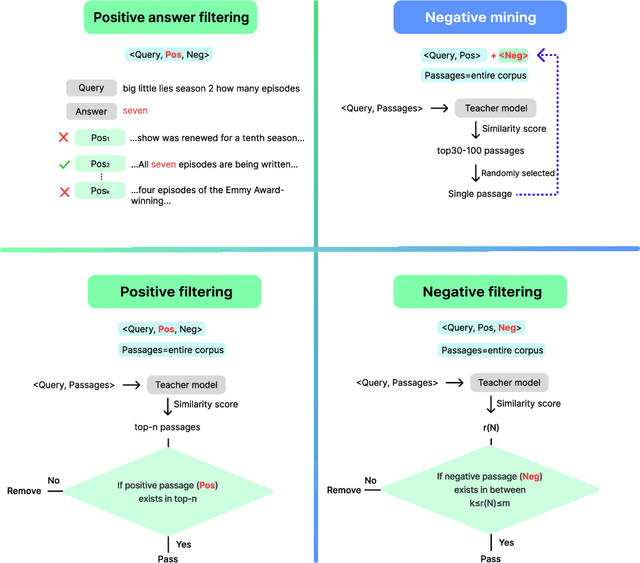

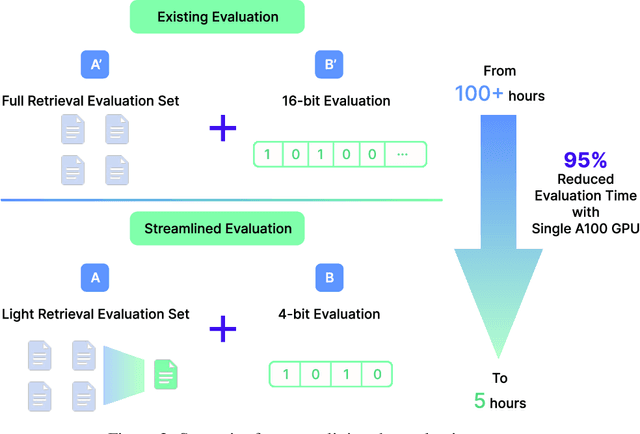
This report explores the enhancement of text retrieval performance using advanced data refinement techniques. We develop Linq-Embed-Mistral\footnote{\url{https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral}} by building on the E5-mistral and Mistral-7B-v0.1 models, focusing on sophisticated data crafting, data filtering, and negative mining methods, which are highly tailored to each task, applied to both existing benchmark dataset and highly tailored synthetic dataset generated via large language models (LLMs). Linq-Embed-Mistral excels in the MTEB benchmarks (as of May 29, 2024), achieving an average score of 68.2 across 56 datasets, and ranks 1st among all models for retrieval tasks on the MTEB leaderboard with a performance score of 60.2. This performance underscores its superior capability in enhancing search precision and reliability. Our contributions include advanced data refinement methods that significantly improve model performance on benchmark and synthetic datasets, techniques for homogeneous task ordering and mixed task fine-tuning to enhance model generalization and stability, and a streamlined evaluation process using 4-bit precision and a light retrieval evaluation set, which accelerates validation without sacrificing accuracy.
Alternative Speech: Complementary Method to Counter-Narrative for Better Discourse
Jan 26, 2024We introduce the concept of "Alternative Speech" as a new way to directly combat hate speech and complement the limitations of counter-narrative. An alternative speech provides practical alternatives to hate speech in real-world scenarios by offering speech-level corrections to speakers while considering the surrounding context and promoting speakers to reform. Further, an alternative speech can combat hate speech alongside counter-narratives, offering a useful tool to address social issues such as racial discrimination and gender inequality. We propose the new concept and provide detailed guidelines for constructing the necessary dataset. Through discussion, we demonstrate that combining alternative speech and counter-narrative can be a more effective strategy for combating hate speech by complementing specificity and guiding capacity of counter-narrative. This paper presents another perspective for dealing with hate speech, offering viable remedies to complement the constraints of current approaches to mitigating harmful bias.
Synthetic Alone: Exploring the Dark Side of Synthetic Data for Grammatical Error Correction
Jun 26, 2023
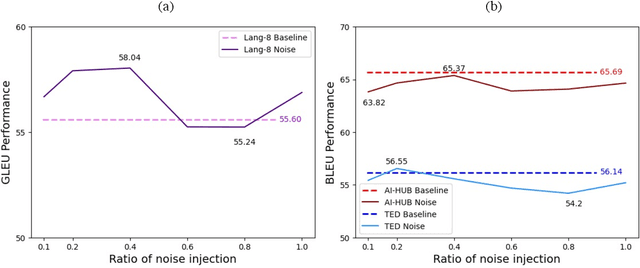


Data-centric AI approach aims to enhance the model performance without modifying the model and has been shown to impact model performance positively. While recent attention has been given to data-centric AI based on synthetic data, due to its potential for performance improvement, data-centric AI has long been exclusively validated using real-world data and publicly available benchmark datasets. In respect of this, data-centric AI still highly depends on real-world data, and the verification of models using synthetic data has not yet been thoroughly carried out. Given the challenges above, we ask the question: Does data quality control (noise injection and balanced data), a data-centric AI methodology acclaimed to have a positive impact, exhibit the same positive impact in models trained solely with synthetic data? To address this question, we conducted comparative analyses between models trained on synthetic and real-world data based on grammatical error correction (GEC) task. Our experimental results reveal that the data quality control method has a positive impact on models trained with real-world data, as previously reported in existing studies, while a negative impact is observed in models trained solely on synthetic data.
What does the Failure to Reason with "Respectively" in Zero/Few-Shot Settings Tell Us about Language Models?
May 31, 2023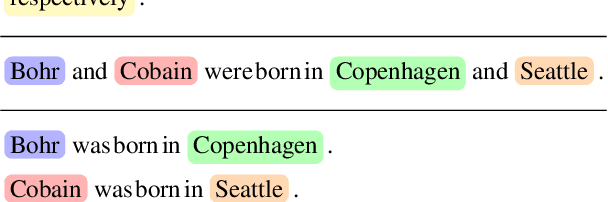
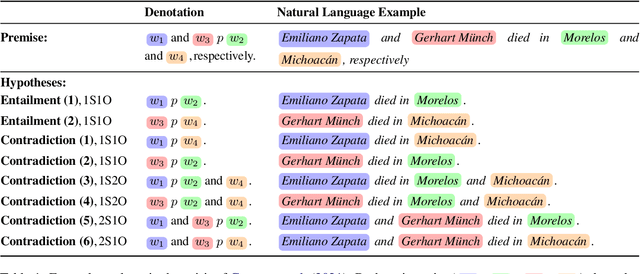
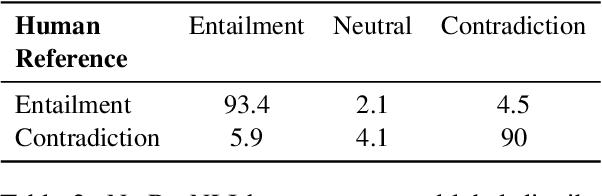
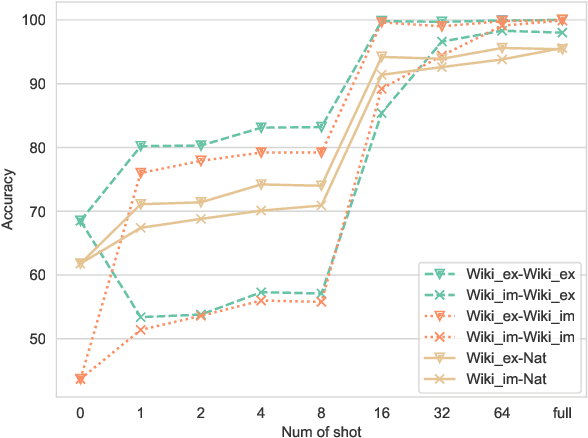
Humans can effortlessly understand the coordinate structure of sentences such as "Niels Bohr and Kurt Cobain were born in Copenhagen and Seattle, respectively". In the context of natural language inference (NLI), we examine how language models (LMs) reason with respective readings (Gawron and Kehler, 2004) from two perspectives: syntactic-semantic and commonsense-world knowledge. We propose a controlled synthetic dataset WikiResNLI and a naturally occurring dataset NatResNLI to encompass various explicit and implicit realizations of "respectively". We show that fine-tuned NLI models struggle with understanding such readings without explicit supervision. While few-shot learning is easy in the presence of explicit cues, longer training is required when the reading is evoked implicitly, leaving models to rely on common sense inferences. Furthermore, our fine-grained analysis indicates models fail to generalize across different constructions. To conclude, we demonstrate that LMs still lag behind humans in generalizing to the long tail of linguistic constructions.
Private Meeting Summarization Without Performance Loss
May 25, 2023
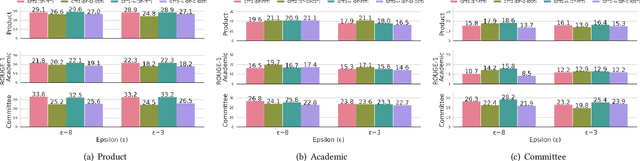
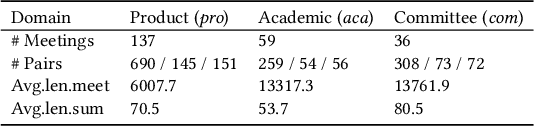
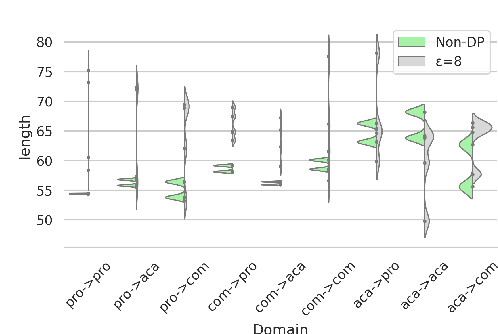
Meeting summarization has an enormous business potential, but in addition to being a hard problem, roll-out is challenged by privacy concerns. We explore the problem of meeting summarization under differential privacy constraints and find, to our surprise, that while differential privacy leads to slightly lower performance on in-sample data, differential privacy improves performance when evaluated on unseen meeting types. Since meeting summarization systems will encounter a great variety of meeting types in practical employment scenarios, this observation makes safe meeting summarization seem much more feasible. We perform extensive error analysis and identify potential risks in meeting summarization under differential privacy, including a faithfulness analysis.
Assessing Cross-Cultural Alignment between ChatGPT and Human Societies: An Empirical Study
Mar 31, 2023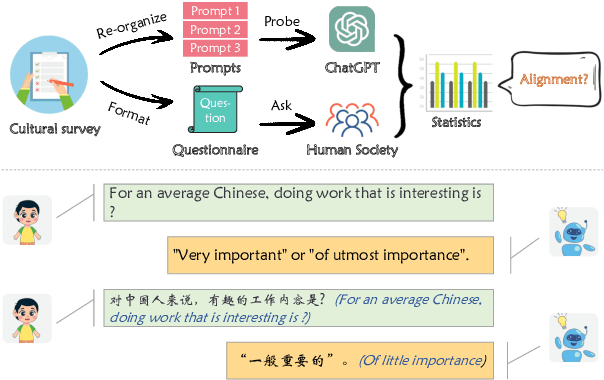


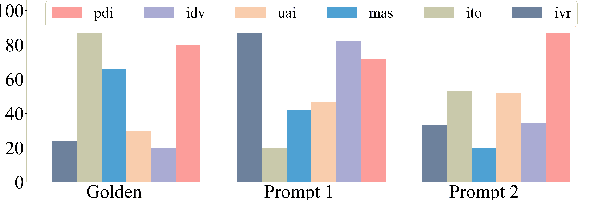
The recent release of ChatGPT has garnered widespread recognition for its exceptional ability to generate human-like responses in dialogue. Given its usage by users from various nations and its training on a vast multilingual corpus that incorporates diverse cultural and societal norms, it is crucial to evaluate its effectiveness in cultural adaptation. In this paper, we investigate the underlying cultural background of ChatGPT by analyzing its responses to questions designed to quantify human cultural differences. Our findings suggest that, when prompted with American context, ChatGPT exhibits a strong alignment with American culture, but it adapts less effectively to other cultural contexts. Furthermore, by using different prompts to probe the model, we show that English prompts reduce the variance in model responses, flattening out cultural differences and biasing them towards American culture. This study provides valuable insights into the cultural implications of ChatGPT and highlights the necessity of greater diversity and cultural awareness in language technologies.
Self-Improving-Leaderboard: A Call for Real-World Centric Natural Language Processing Leaderboards
Mar 20, 2023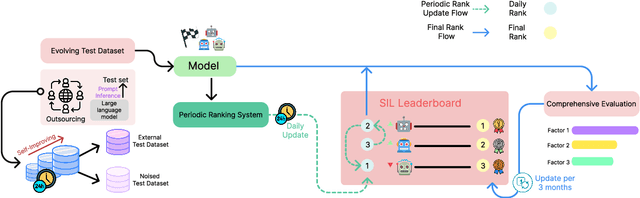
Leaderboard systems allow researchers to objectively evaluate Natural Language Processing (NLP) models and are typically used to identify models that exhibit superior performance on a given task in a predetermined setting. However, we argue that evaluation on a given test dataset is just one of many performance indications of the model. In this paper, we claim leaderboard competitions should also aim to identify models that exhibit the best performance in a real-world setting. We highlight three issues with current leaderboard systems: (1) the use of a single, static test set, (2) discrepancy between testing and real-world application (3) the tendency for leaderboard-centric competition to be biased towards the test set. As a solution, we propose a new paradigm of leaderboard systems that addresses these issues of current leaderboard system. Through this study, we hope to induce a paradigm shift towards more real -world-centric leaderboard competitions.
FreeTalky: Don't Be Afraid! Conversations Made Easier by a Humanoid Robot using Persona-based Dialogue
Dec 08, 2021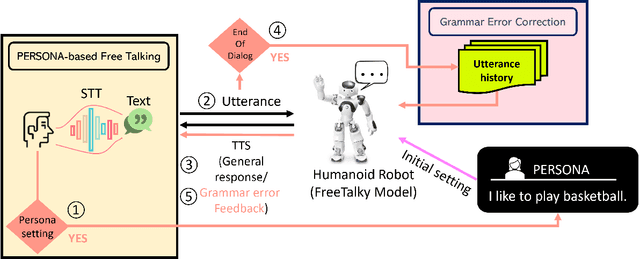

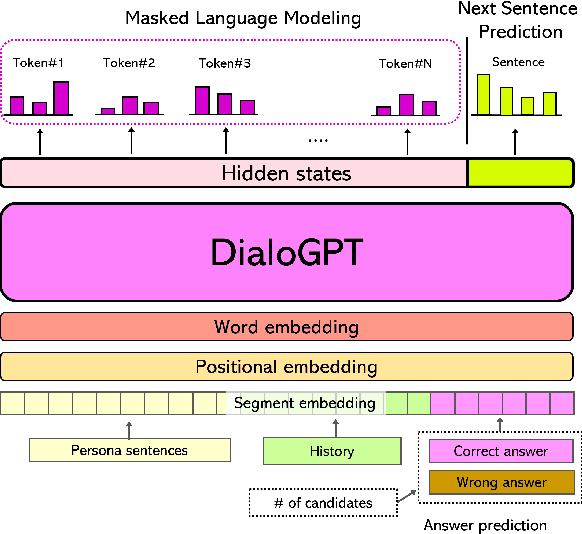
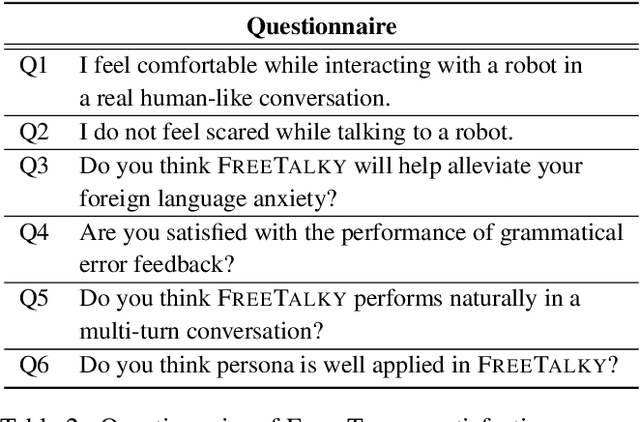
We propose a deep learning-based foreign language learning platform, named FreeTalky, for people who experience anxiety dealing with foreign languages, by employing a humanoid robot NAO and various deep learning models. A persona-based dialogue system that is embedded in NAO provides an interesting and consistent multi-turn dialogue for users. Also, an grammar error correction system promotes improvement in grammar skills of the users. Thus, our system enables personalized learning based on persona dialogue and facilitates grammar learning of a user using grammar error feedback. Furthermore, we verified whether FreeTalky provides practical help in alleviating xenoglossophobia by replacing the real human in the conversation with a NAO robot, through human evaluation.
How should human translation coexist with NMT? Efficient tool for building high quality parallel corpus
Oct 30, 2021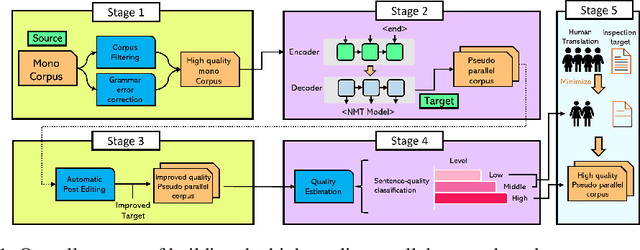
This paper proposes a tool for efficiently constructing high-quality parallel corpora with minimizing human labor and making this tool publicly available. Our proposed construction process is based on neural machine translation (NMT) to allow for it to not only coexist with human translation, but also improve its efficiency by combining data quality control with human translation in a data-centric approach.
Empirical Analysis of Korean Public AI Hub Parallel Corpora and in-depth Analysis using LIWC
Oct 28, 2021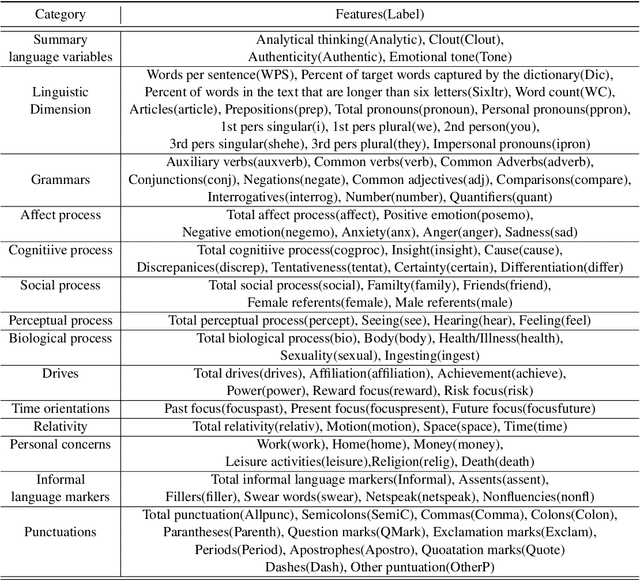
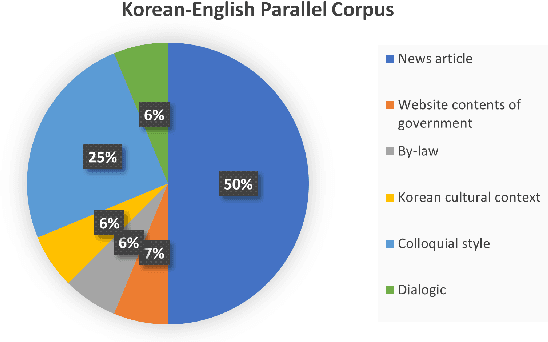
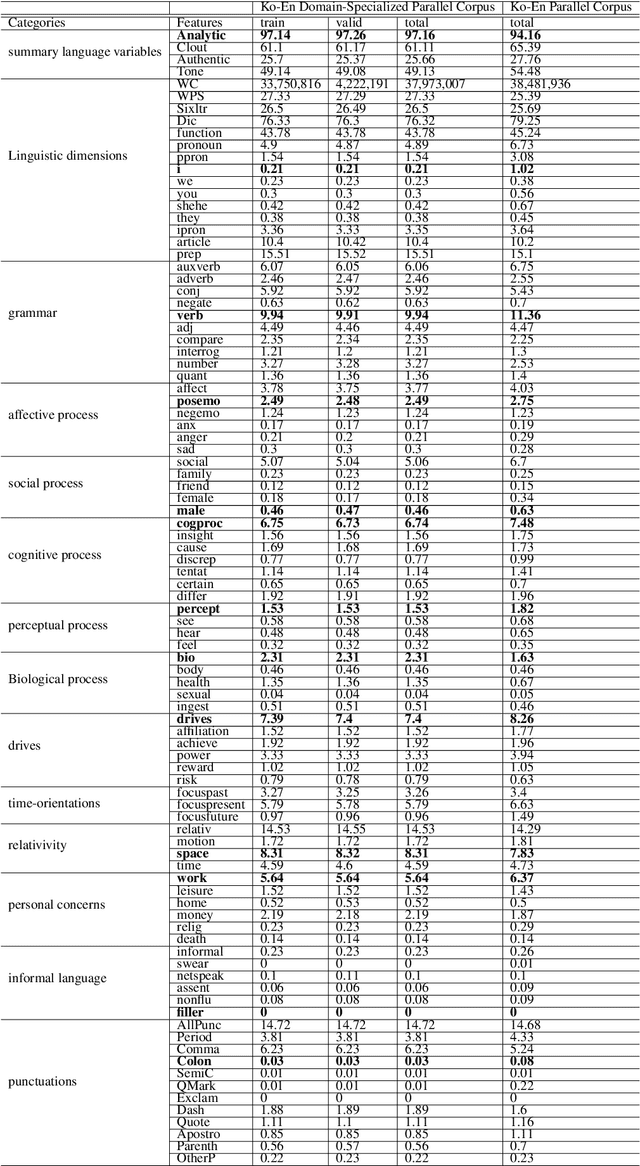

Machine translation (MT) system aims to translate source language into target language. Recent studies on MT systems mainly focus on neural machine translation (NMT). One factor that significantly affects the performance of NMT is the availability of high-quality parallel corpora. However, high-quality parallel corpora concerning Korean are relatively scarce compared to those associated with other high-resource languages, such as German or Italian. To address this problem, AI Hub recently released seven types of parallel corpora for Korean. In this study, we conduct an in-depth verification of the quality of corresponding parallel corpora through Linguistic Inquiry and Word Count (LIWC) and several relevant experiments. LIWC is a word-counting software program that can analyze corpora in multiple ways and extract linguistic features as a dictionary base. To the best of our knowledge, this study is the first to use LIWC to analyze parallel corpora in the field of NMT. Our findings suggest the direction of further research toward obtaining the improved quality parallel corpora through our correlation analysis in LIWC and NMT performance.