 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEG: Medical Knowledge-Augmented Large Language Models for Question Answering
Nov 07, 2024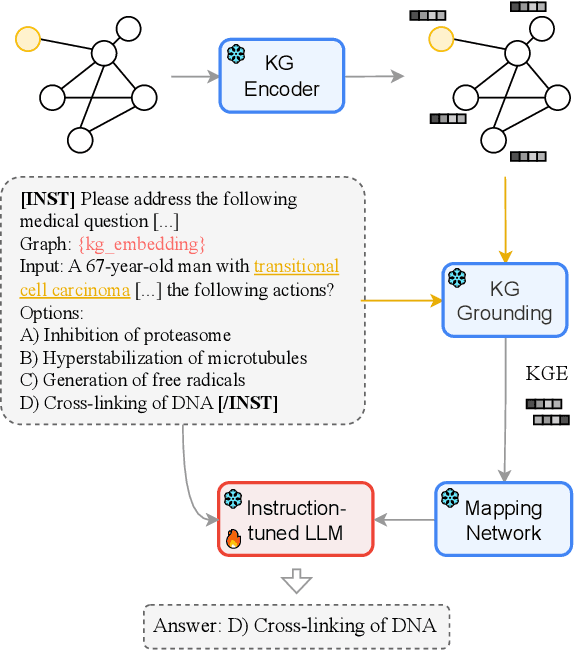

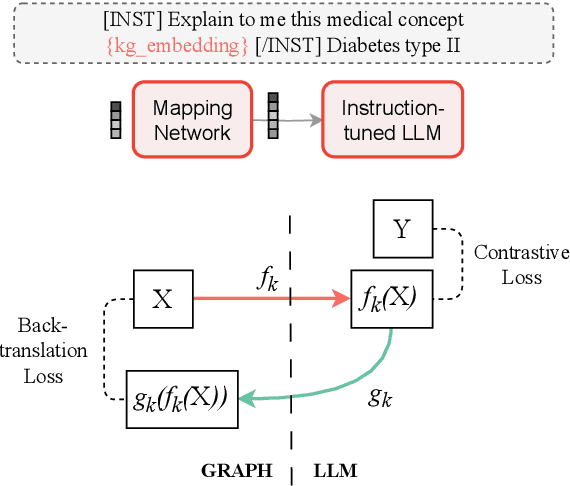

Question answering is a natural language understanding task that involves reasoning over both explicit context and unstated, relevant domain knowledge. Large language models (LLMs), which underpin most contemporary question answering systems, struggle to induce how concepts relate in specialized domains such as medicine. Existing medical LLMs are also costly to train. In this work, we present MEG, a parameter-efficient approach for medical knowledge-augmented LLMs. MEG uses a lightweight mapping network to integrate graph embeddings into the LLM, enabling it to leverage external knowledge in a cost-effective way. We evaluate our method on four popular medical multiple-choice datasets and show that LLMs greatly benefit from the factual grounding provided by knowledge graph embeddings. MEG attains an average of +10.2% accuracy over the Mistral-Instruct baseline, and +6.7% over specialized models like BioMistral. We also show results based on Llama-3. Finally, we show that MEG's performance remains robust to the choice of graph encoder.
It is Simple Sometimes: A Study On Improving Aspect-Based Sentiment Analysis Performance
May 31, 2024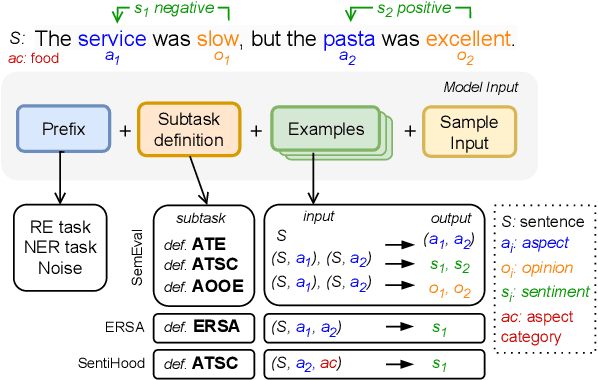
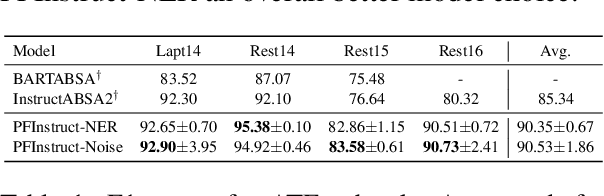
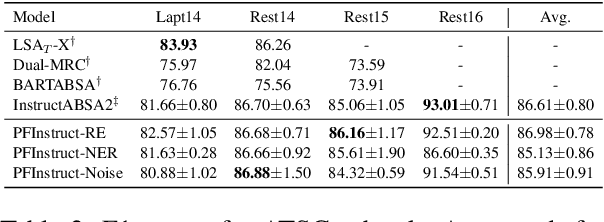
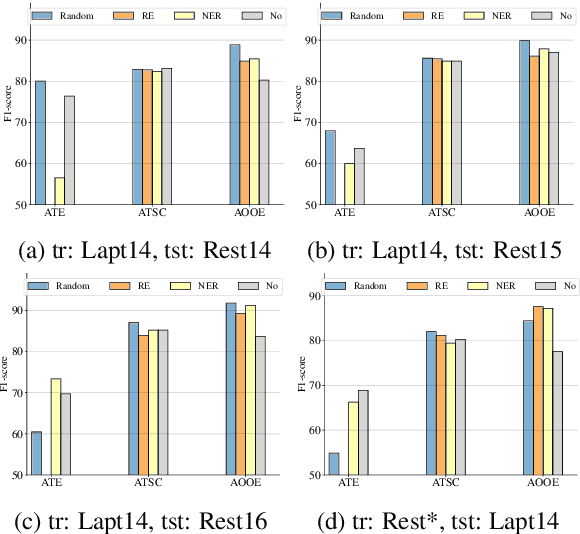
Aspect-Based Sentiment Analysis (ABSA) involves extracting opinions from textual data about specific entities and their corresponding aspects through various complementary subtasks. Several prior research has focused on developing ad hoc designs of varying complexities for these subtasks. In this paper, we present a generative framework extensible to any ABSA subtask. We build upon the instruction tuned model proposed by Scaria et al. (2023), who present an instruction-based model with task descriptions followed by in-context examples on ABSA subtasks. We propose PFInstruct, an extension to this instruction learning paradigm by appending an NLP-related task prefix to the task description. This simple approach leads to improved performance across all tested SemEval subtasks, surpassing previous state-of-the-art (SOTA) on the ATE subtask (Rest14) by +3.28 F1-score, and on the AOOE subtask by an average of +5.43 F1-score across SemEval datasets. Furthermore, we explore the impact of the prefix-enhanced prompt quality on the ABSA subtasks and find that even a noisy prefix enhances model performance compared to the baseline. Our method also achieves competitive results on a biomedical domain dataset (ERSA).
Evaluating Bias and Fairness in Gender-Neutral Pretrained Vision-and-Language Models
Oct 26, 2023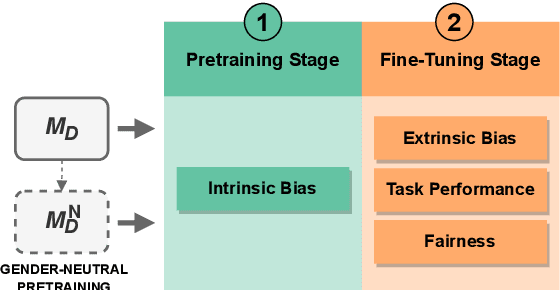

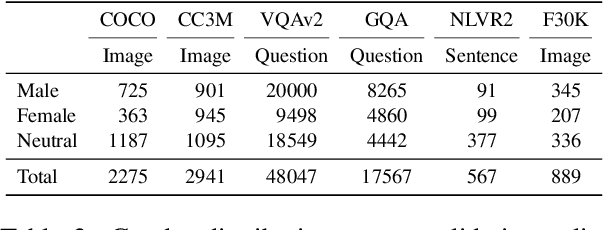
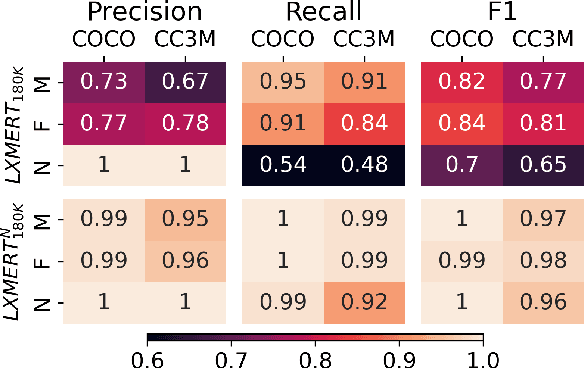
Pretrained machine learning models are known to perpetuate and even amplify existing biases in data, which can result in unfair outcomes that ultimately impact user experience. Therefore, it is crucial to understand the mechanisms behind those prejudicial biases to ensure that model performance does not result in discriminatory behaviour toward certain groups or populations. In this work, we define gender bias as our case study. We quantify bias amplification in pretraining and after fine-tuning on three families of vision-and-language models. We investigate the connection, if any, between the two learning stages, and evaluate how bias amplification reflects on model performance. Overall, we find that bias amplification in pretraining and after fine-tuning are independent. We then examine the effect of continued pretraining on gender-neutral data, finding that this reduces group disparities, i.e., promotes fairness, on VQAv2 and retrieval tasks without significantly compromising task performance.
Rather a Nurse than a Physician -- Contrastive Explanations under Investigation
Oct 18, 2023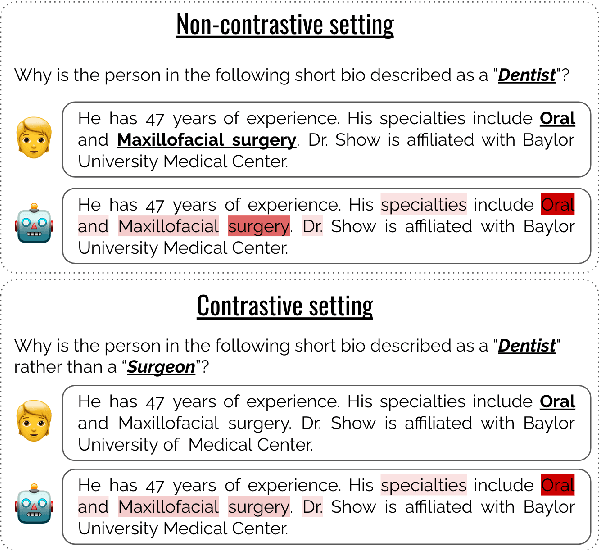
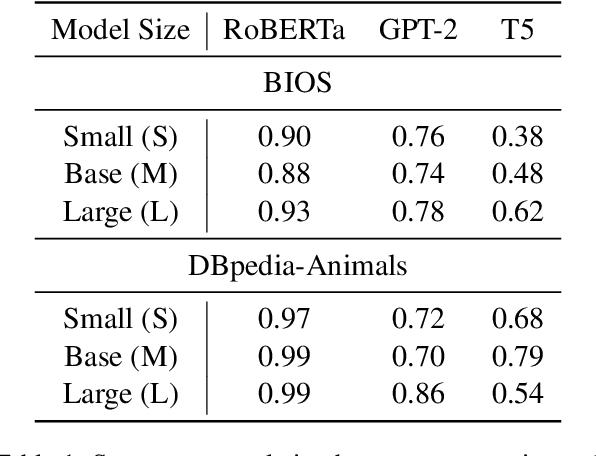

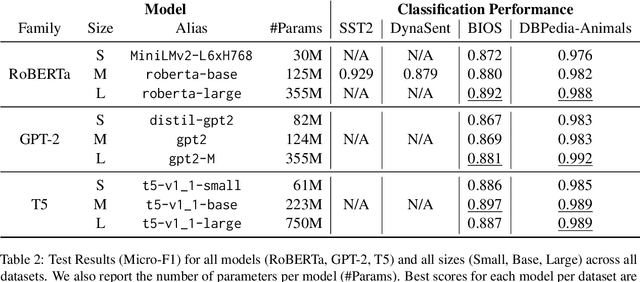
Contrastive explanations, where one decision is explained in contrast to another, are supposed to be closer to how humans explain a decision than non-contrastive explanations, where the decision is not necessarily referenced to an alternative. This claim has never been empirically validated. We analyze four English text-classification datasets (SST2, DynaSent, BIOS and DBpedia-Animals). We fine-tune and extract explanations from three different models (RoBERTa, GTP-2, and T5), each in three different sizes and apply three post-hoc explainability methods (LRP, GradientxInput, GradNorm). We furthermore collect and release human rationale annotations for a subset of 100 samples from the BIOS dataset for contrastive and non-contrastive settings. A cross-comparison between model-based rationales and human annotations, both in contrastive and non-contrastive settings, yields a high agreement between the two settings for models as well as for humans. Moreover, model-based explanations computed in both settings align equally well with human rationales. Thus, we empirically find that humans do not necessarily explain in a contrastive manner.9 pages, long paper at ACL 2022 proceedings.
PokemonChat: Auditing ChatGPT for Pokémon Universe Knowledge
Jun 05, 2023The recently released ChatGPT model demonstrates unprecedented capabilities in zero-shot question-answering. In this work, we probe ChatGPT for its conversational understanding and introduce a conversational framework (protocol) that can be adopted in future studies. The Pok\'emon universe serves as an ideal testing ground for auditing ChatGPT's reasoning capabilities due to its closed world assumption. After bringing ChatGPT's background knowledge (on the Pok\'emon universe) to light, we test its reasoning process when using these concepts in battle scenarios. We then evaluate its ability to acquire new knowledge and include it in its reasoning process. Our ultimate goal is to assess ChatGPT's ability to generalize, combine features, and to acquire and reason over newly introduced knowledge from human feedback. We find that ChatGPT has prior knowledge of the Pokemon universe, which can reason upon in battle scenarios to a great extent, even when new information is introduced. The model performs better with collaborative feedback and if there is an initial phase of information retrieval, but also hallucinates occasionally and is susceptible to adversarial attacks.
Being Right for Whose Right Reasons?
Jun 01, 2023


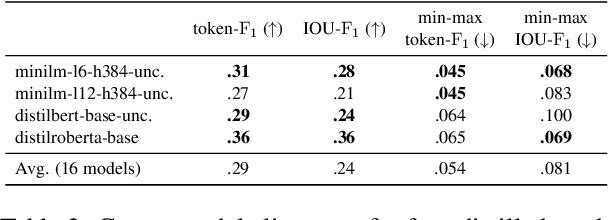
Explainability methods are used to benchmark the extent to which model predictions align with human rationales i.e., are 'right for the right reasons'. Previous work has failed to acknowledge, however, that what counts as a rationale is sometimes subjective. This paper presents what we think is a first of its kind, a collection of human rationale annotations augmented with the annotators demographic information. We cover three datasets spanning sentiment analysis and common-sense reasoning, and six demographic groups (balanced across age and ethnicity). Such data enables us to ask both what demographics our predictions align with and whose reasoning patterns our models' rationales align with. We find systematic inter-group annotator disagreement and show how 16 Transformer-based models align better with rationales provided by certain demographic groups: We find that models are biased towards aligning best with older and/or white annotators. We zoom in on the effects of model size and model distillation, finding -- contrary to our expectations -- negative correlations between model size and rationale agreement as well as no evidence that either model size or model distillation improves fairness.
On the Independence of Association Bias and Empirical Fairness in Language Models
Apr 20, 2023


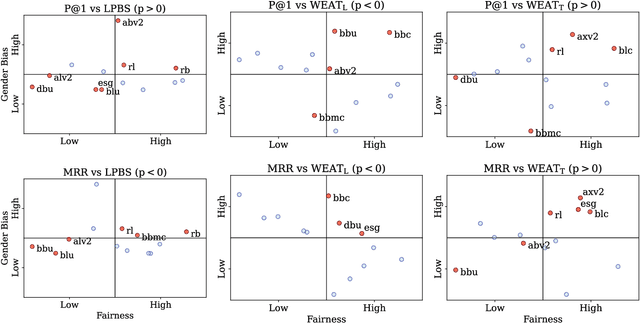
The societal impact of pre-trained language models has prompted researchers to probe them for strong associations between protected attributes and value-loaded terms, from slur to prestigious job titles. Such work is said to probe models for bias or fairness-or such probes 'into representational biases' are said to be 'motivated by fairness'-suggesting an intimate connection between bias and fairness. We provide conceptual clarity by distinguishing between association biases (Caliskan et al., 2022) and empirical fairness (Shen et al., 2022) and show the two can be independent. Our main contribution, however, is showing why this should not come as a surprise. To this end, we first provide a thought experiment, showing how association bias and empirical fairness can be completely orthogonal. Next, we provide empirical evidence that there is no correlation between bias metrics and fairness metrics across the most widely used language models. Finally, we survey the sociological and psychological literature and show how this literature provides ample support for expecting these metrics to be uncorrelated.
Cross-Cultural Transfer Learning for Chinese Offensive Language Detection
Mar 31, 2023Detecting offensive language is a challenging task. Generalizing across different cultures and languages becomes even more challenging: besides lexical, syntactic and semantic differences, pragmatic aspects such as cultural norms and sensitivities, which are particularly relevant in this context, vary greatly. In this paper, we target Chinese offensive language detection and aim to investigate the impact of transfer learning using offensive language detection data from different cultural backgrounds, specifically Korean and English. We find that culture-specific biases in what is considered offensive negatively impact the transferability of language models (LMs) and that LMs trained on diverse cultural data are sensitive to different features in Chinese offensive language detection. In a few-shot learning scenario, however, our study shows promising prospects for non-English offensive language detection with limited resources. Our findings highlight the importance of cross-cultural transfer learning in improving offensive language detection and promoting inclusive digital spaces.
Assessing Cross-Cultural Alignment between ChatGPT and Human Societies: An Empirical Study
Mar 31, 2023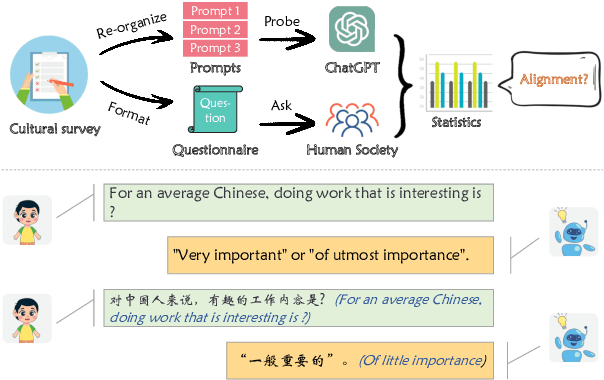


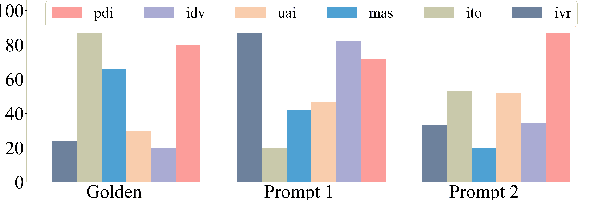
The recent release of ChatGPT has garnered widespread recognition for its exceptional ability to generate human-like responses in dialogue. Given its usage by users from various nations and its training on a vast multilingual corpus that incorporates diverse cultural and societal norms, it is crucial to evaluate its effectiveness in cultural adaptation. In this paper, we investigate the underlying cultural background of ChatGPT by analyzing its responses to questions designed to quantify human cultural differences. Our findings suggest that, when prompted with American context, ChatGPT exhibits a strong alignment with American culture, but it adapts less effectively to other cultural contexts. Furthermore, by using different prompts to probe the model, we show that English prompts reduce the variance in model responses, flattening out cultural differences and biasing them towards American culture. This study provides valuable insights into the cultural implications of ChatGPT and highlights the necessity of greater diversity and cultural awareness in language technologies.