 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Independence of Association Bias and Empirical Fairness in Language Models
Paper and Code
Apr 20, 2023


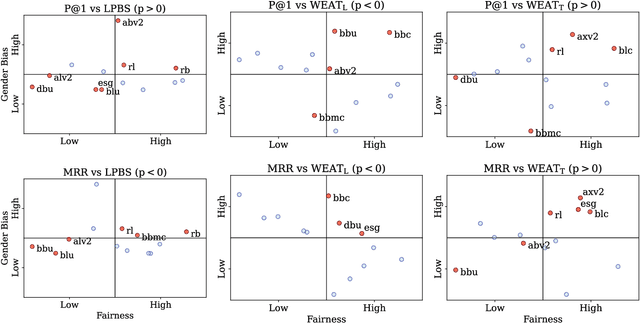
The societal impact of pre-trained language models has prompted researchers to probe them for strong associations between protected attributes and value-loaded terms, from slur to prestigious job titles. Such work is said to probe models for bias or fairness-or such probes 'into representational biases' are said to be 'motivated by fairness'-suggesting an intimate connection between bias and fairness. We provide conceptual clarity by distinguishing between association biases (Caliskan et al., 2022) and empirical fairness (Shen et al., 2022) and show the two can be independent. Our main contribution, however, is showing why this should not come as a surprise. To this end, we first provide a thought experiment, showing how association bias and empirical fairness can be completely orthogonal. Next, we provide empirical evidence that there is no correlation between bias metrics and fairness metrics across the most widely used language models. Finally, we survey the sociological and psychological literature and show how this literature provides ample support for expecting these metrics to be uncorrelated.