 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManaging FAIR Knowledge Graphs as Polyglot Data End Points: A Benchmark based on the rdf2pg Framework and Plant Biology Data
May 23, 2025Linked Data and labelled property graphs (LPG) are two data management approaches with complementary strengths and weaknesses, making their integration beneficial for sharing datasets and supporting software ecosystems. In this paper, we introduce rdf2pg, an extensible framework for mapping RDF data to semantically equivalent LPG formats and data-bases. Utilising this framework, we perform a comparative analysis of three popular graph databases - Virtuoso, Neo4j, and ArcadeDB - and the well-known graph query languages SPARQL, Cypher, and Gremlin. Our qualitative and quantitative as-sessments underline the strengths and limitations of these graph database technologies. Additionally, we highlight the potential of rdf2pg as a versatile tool for enabling polyglot access to knowledge graphs, aligning with established standards of Linked Data and the Semantic Web.
Linguistic Interpretability of Transformer-based Language Models: a systematic review
Apr 09, 2025Language models based on the Transformer architecture achieve excellent results in many language-related tasks, such as text classification or sentiment analysis. However, despite the architecture of these models being well-defined, little is known about how their internal computations help them achieve their results. This renders these models, as of today, a type of 'black box' systems. There is, however, a line of research -- 'interpretability' -- aiming to learn how information is encoded inside these models. More specifically, there is work dedicated to studying whether Transformer-based models possess knowledge of linguistic phenomena similar to human speakers -- an area we call 'linguistic interpretability' of these models. In this survey we present a comprehensive analysis of 160 research works, spread across multiple languages and models -- including multilingual ones -- that attempt to discover linguistic information from the perspective of several traditional Linguistics disciplines: Syntax, Morphology, Lexico-Semantics and Discourse. Our survey fills a gap in the existing interpretability literature, which either not focus on linguistic knowledge in these models or present some limitations -- e.g. only studying English-based models. Our survey also focuses on Pre-trained Language Models not further specialized for a downstream task, with an emphasis on works that use interpretability techniques that explore models' internal representations.
MEG: Medical Knowledge-Augmented Large Language Models for Question Answering
Nov 07, 2024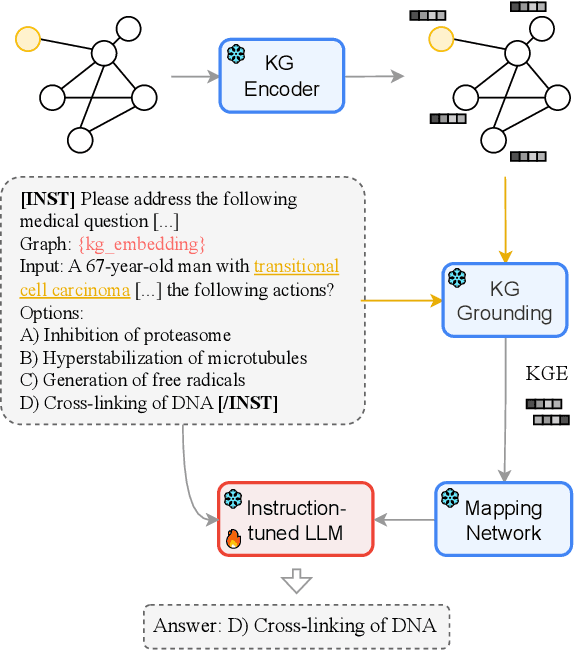

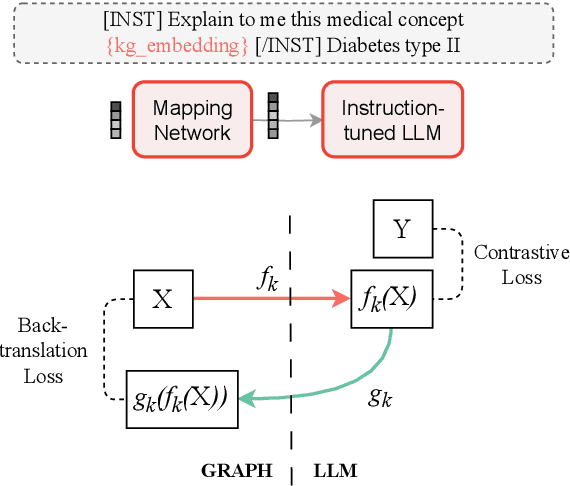

Question answering is a natural language understanding task that involves reasoning over both explicit context and unstated, relevant domain knowledge. Large language models (LLMs), which underpin most contemporary question answering systems, struggle to induce how concepts relate in specialized domains such as medicine. Existing medical LLMs are also costly to train. In this work, we present MEG, a parameter-efficient approach for medical knowledge-augmented LLMs. MEG uses a lightweight mapping network to integrate graph embeddings into the LLM, enabling it to leverage external knowledge in a cost-effective way. We evaluate our method on four popular medical multiple-choice datasets and show that LLMs greatly benefit from the factual grounding provided by knowledge graph embeddings. MEG attains an average of +10.2% accuracy over the Mistral-Instruct baseline, and +6.7% over specialized models like BioMistral. We also show results based on Llama-3. Finally, we show that MEG's performance remains robust to the choice of graph encoder.
Semantic Relatedness for Keyword Disambiguation: Exploiting Different Embeddings
Feb 25, 2020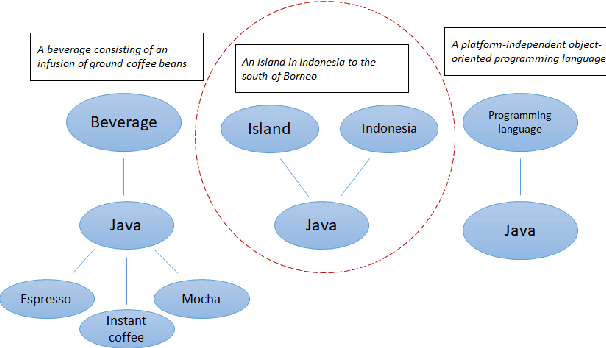
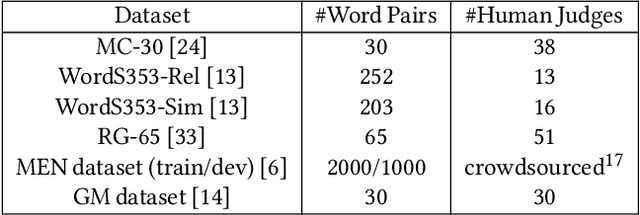
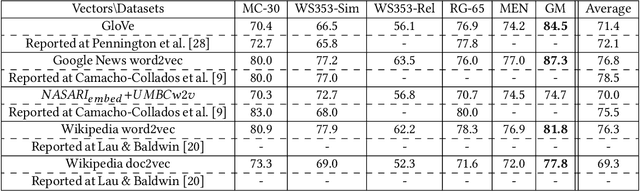

Understanding the meaning of words is crucial for many tasks that involve human-machine interaction. This has been tackled by research in Word Sense Disambiguation (WSD) in the Natural Language Processing (NLP) field. Recently, WSD and many other NLP tasks have taken advantage of embeddings-based representation of words, sentences, and documents. However, when it comes to WSD, most embeddings models suffer from ambiguity as they do not capture the different possible meanings of the words. Even when they do, the list of possible meanings for a word (sense inventory) has to be known in advance at training time to be included in the embeddings space. Unfortunately, there are situations in which such a sense inventory is not known in advance (e.g., an ontology selected at run-time), or it evolves with time and its status diverges from the one at training time. This hampers the use of embeddings models for WSD. Furthermore, traditional WSD techniques do not perform well in situations in which the available linguistic information is very scarce, such as the case of keyword-based queries. In this paper, we propose an approach to keyword disambiguation which grounds on a semantic relatedness between words and senses provided by an external inventory (ontology) that is not known at training time. Building on previous works, we present a semantic relatedness measure that uses word embeddings, and explore different disambiguation algorithms to also exploit both word and sentence representations. Experimental results show that this approach achieves results comparable with the state of the art when applied for WSD, without training for a particular domain.