 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Relatedness for Keyword Disambiguation: Exploiting Different Embeddings
Feb 25, 2020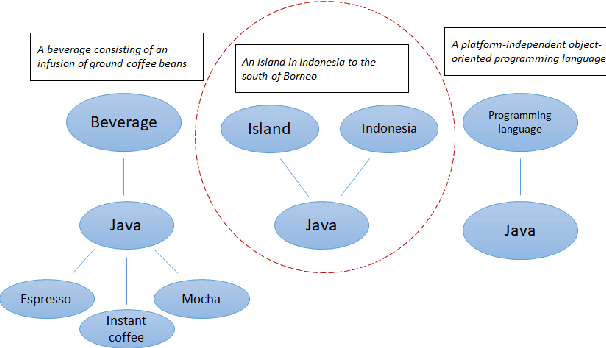
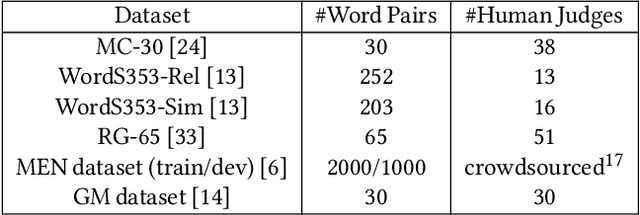
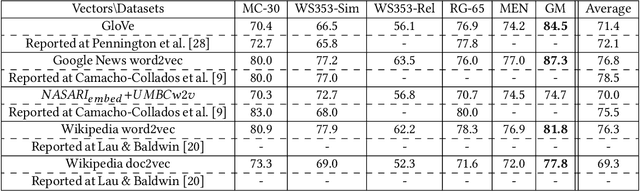

Understanding the meaning of words is crucial for many tasks that involve human-machine interaction. This has been tackled by research in Word Sense Disambiguation (WSD) in the Natural Language Processing (NLP) field. Recently, WSD and many other NLP tasks have taken advantage of embeddings-based representation of words, sentences, and documents. However, when it comes to WSD, most embeddings models suffer from ambiguity as they do not capture the different possible meanings of the words. Even when they do, the list of possible meanings for a word (sense inventory) has to be known in advance at training time to be included in the embeddings space. Unfortunately, there are situations in which such a sense inventory is not known in advance (e.g., an ontology selected at run-time), or it evolves with time and its status diverges from the one at training time. This hampers the use of embeddings models for WSD. Furthermore, traditional WSD techniques do not perform well in situations in which the available linguistic information is very scarce, such as the case of keyword-based queries. In this paper, we propose an approach to keyword disambiguation which grounds on a semantic relatedness between words and senses provided by an external inventory (ontology) that is not known at training time. Building on previous works, we present a semantic relatedness measure that uses word embeddings, and explore different disambiguation algorithms to also exploit both word and sentence representations. Experimental results show that this approach achieves results comparable with the state of the art when applied for WSD, without training for a particular domain.