 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing zero-shot self-explanations with human rationales in multilingual text classification
Oct 04, 2024
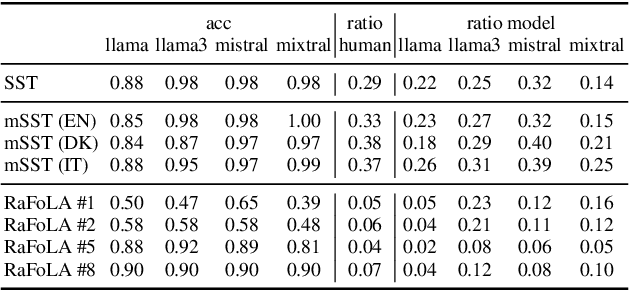

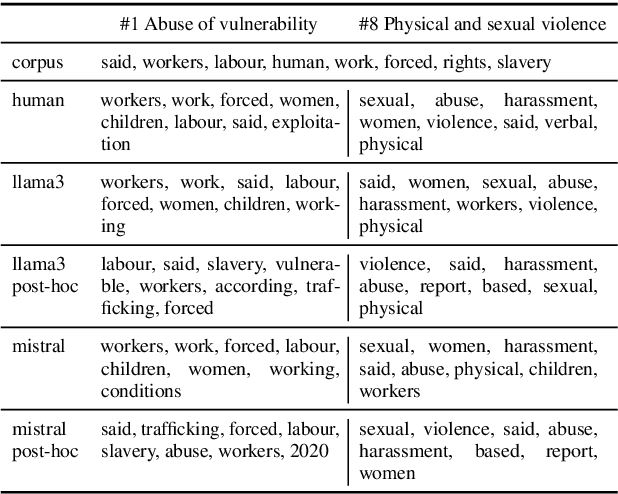
Instruction-tuned LLMs are able to provide an explanation about their output to users by generating self-explanations that do not require gradient computations or the application of possibly complex XAI methods. In this paper, we analyse whether this ability results in a good explanation by evaluating self-explanations in the form of input rationales with respect to their plausibility to humans as well as their faithfulness to models. For this, we apply two text classification tasks: sentiment classification and forced labour detection. Next to English, we further include Danish and Italian translations of the sentiment classification task and compare self-explanations to human annotations for all samples. To allow for direct comparisons, we also compute post-hoc feature attribution, i.e., layer-wise relevance propagation (LRP) and apply this pipeline to 4 LLMs (Llama2, Llama3, Mistral and Mixtral). Our results show that self-explanations align more closely with human annotations compared to LRP, while maintaining a comparable level of faithfulness.
Llama meets EU: Investigating the European Political Spectrum through the Lens of LLMs
Mar 22, 2024Instruction-finetuned Large Language Models inherit clear political leanings that have been shown to influence downstream task performance. We expand this line of research beyond the two-party system in the US and audit Llama Chat in the context of EU politics in various settings to analyze the model's political knowledge and its ability to reason in context. We adapt, i.e., further fine-tune, Llama Chat on speeches of individual euro-parties from debates in the European Parliament to reevaluate its political leaning based on the EUandI questionnaire. Llama Chat shows considerable knowledge of national parties' positions and is capable of reasoning in context. The adapted, party-specific, models are substantially re-aligned towards respective positions which we see as a starting point for using chat-based LLMs as data-driven conversational engines to assist research in political science.
Evaluating Webcam-based Gaze Data as an Alternative for Human Rationale Annotations
Feb 29, 2024Rationales in the form of manually annotated input spans usually serve as ground truth when evaluating explainability methods in NLP. They are, however, time-consuming and often biased by the annotation process. In this paper, we debate whether human gaze, in the form of webcam-based eye-tracking recordings, poses a valid alternative when evaluating importance scores. We evaluate the additional information provided by gaze data, such as total reading times, gaze entropy, and decoding accuracy with respect to human rationale annotations. We compare WebQAmGaze, a multilingual dataset for information-seeking QA, with attention and explainability-based importance scores for 4 different multilingual Transformer-based language models (mBERT, distil-mBERT, XLMR, and XLMR-L) and 3 languages (English, Spanish, and German). Our pipeline can easily be applied to other tasks and languages. Our findings suggest that gaze data offers valuable linguistic insights that could be leveraged to infer task difficulty and further show a comparable ranking of explainability methods to that of human rationales.
Evaluating Bias and Fairness in Gender-Neutral Pretrained Vision-and-Language Models
Oct 26, 2023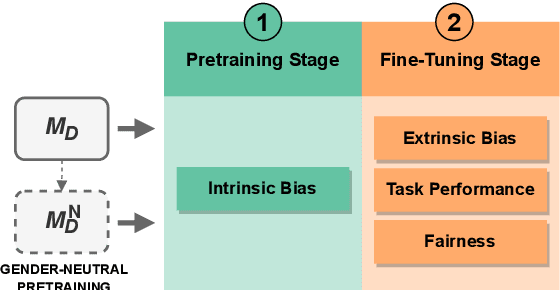

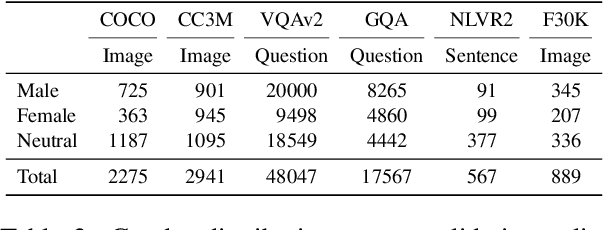
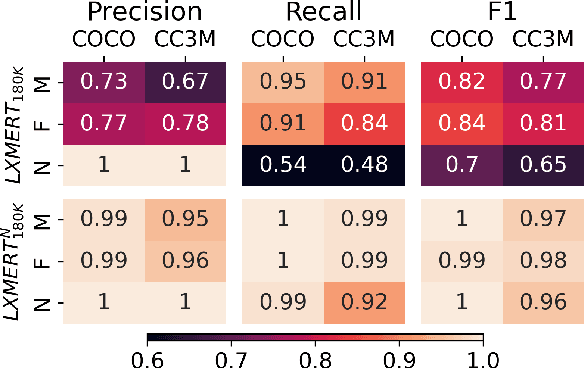
Pretrained machine learning models are known to perpetuate and even amplify existing biases in data, which can result in unfair outcomes that ultimately impact user experience. Therefore, it is crucial to understand the mechanisms behind those prejudicial biases to ensure that model performance does not result in discriminatory behaviour toward certain groups or populations. In this work, we define gender bias as our case study. We quantify bias amplification in pretraining and after fine-tuning on three families of vision-and-language models. We investigate the connection, if any, between the two learning stages, and evaluate how bias amplification reflects on model performance. Overall, we find that bias amplification in pretraining and after fine-tuning are independent. We then examine the effect of continued pretraining on gender-neutral data, finding that this reduces group disparities, i.e., promotes fairness, on VQAv2 and retrieval tasks without significantly compromising task performance.
On the Interplay between Fairness and Explainability
Oct 25, 2023



In order to build reliable and trustworthy NLP applications, models need to be both fair across different demographics and explainable. Usually these two objectives, fairness and explainability, are optimized and/or examined independently of each other. Instead, we argue that forthcoming, trustworthy NLP systems should consider both. In this work, we perform a first study to understand how they influence each other: do fair(er) models rely on more plausible rationales? and vice versa. To this end, we conduct experiments on two English multi-class text classification datasets, BIOS and ECtHR, that provide information on gender and nationality, respectively, as well as human-annotated rationales. We fine-tune pre-trained language models with several methods for (i) bias mitigation, which aims to improve fairness; (ii) rationale extraction, which aims to produce plausible explanations. We find that bias mitigation algorithms do not always lead to fairer models. Moreover, we discover that empirical fairness and explainability are orthogonal.
Rather a Nurse than a Physician -- Contrastive Explanations under Investigation
Oct 18, 2023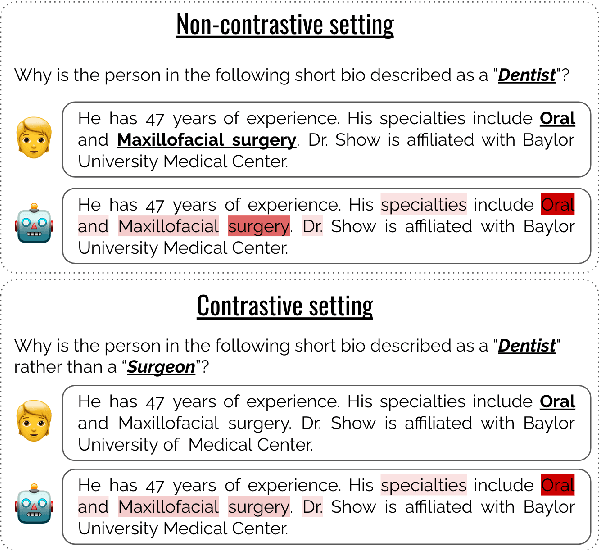
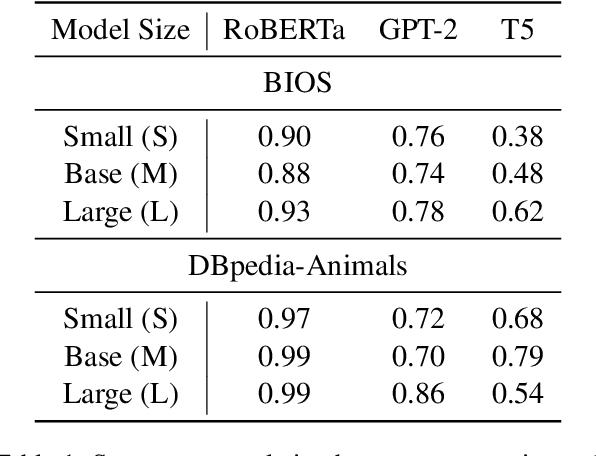

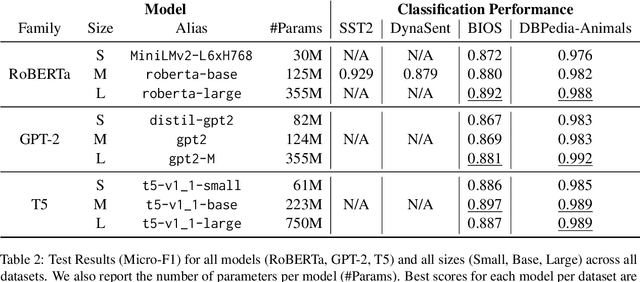
Contrastive explanations, where one decision is explained in contrast to another, are supposed to be closer to how humans explain a decision than non-contrastive explanations, where the decision is not necessarily referenced to an alternative. This claim has never been empirically validated. We analyze four English text-classification datasets (SST2, DynaSent, BIOS and DBpedia-Animals). We fine-tune and extract explanations from three different models (RoBERTa, GTP-2, and T5), each in three different sizes and apply three post-hoc explainability methods (LRP, GradientxInput, GradNorm). We furthermore collect and release human rationale annotations for a subset of 100 samples from the BIOS dataset for contrastive and non-contrastive settings. A cross-comparison between model-based rationales and human annotations, both in contrastive and non-contrastive settings, yields a high agreement between the two settings for models as well as for humans. Moreover, model-based explanations computed in both settings align equally well with human rationales. Thus, we empirically find that humans do not necessarily explain in a contrastive manner.9 pages, long paper at ACL 2022 proceedings.
WebQAmGaze: A Multilingual Webcam Eye-Tracking-While-Reading Dataset
Apr 14, 2023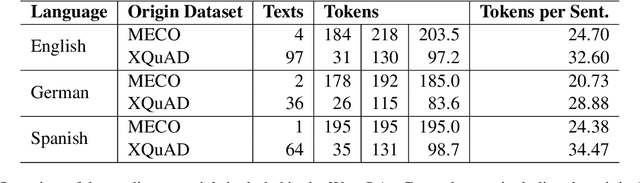
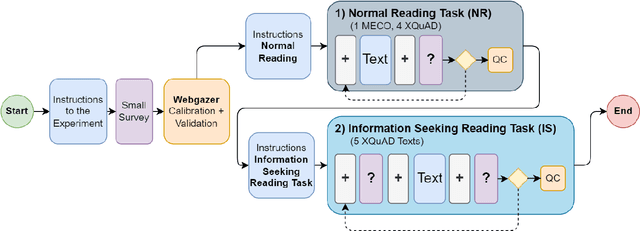
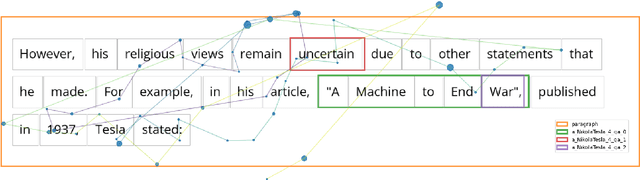
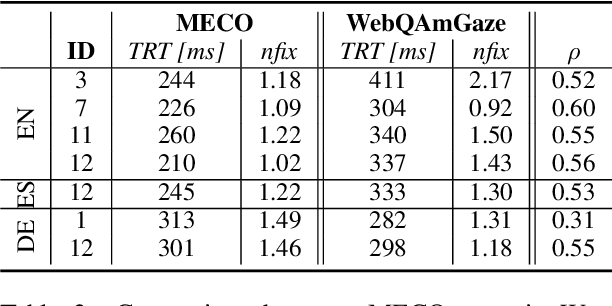
We create WebQAmGaze, a multilingual low-cost eye-tracking-while-reading dataset, designed to support the development of fair and transparent NLP models. WebQAmGaze includes webcam eye-tracking data from 332 participants naturally reading English, Spanish, and German texts. Each participant performs two reading tasks composed of five texts, a normal reading and an information-seeking task. After preprocessing the data, we find that fixations on relevant spans seem to indicate correctness when answering the comprehension questions. Additionally, we perform a comparative analysis of the data collected to high-quality eye-tracking data. The results show a moderate correlation between the features obtained with the webcam-ET compared to those of a commercial ET device. We believe this data can advance webcam-based reading studies and open a way to cheaper and more accessible data collection. WebQAmGaze is useful to learn about the cognitive processes behind question answering (QA) and to apply these insights to computational models of language understanding.
Domain-Specific Word Embeddings with Structure Prediction
Oct 06, 2022
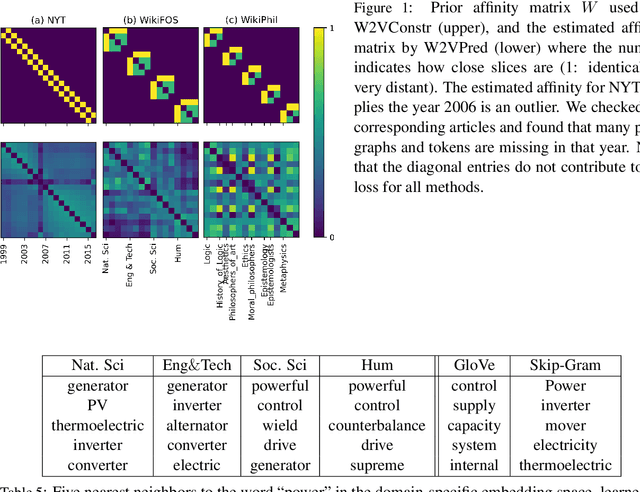
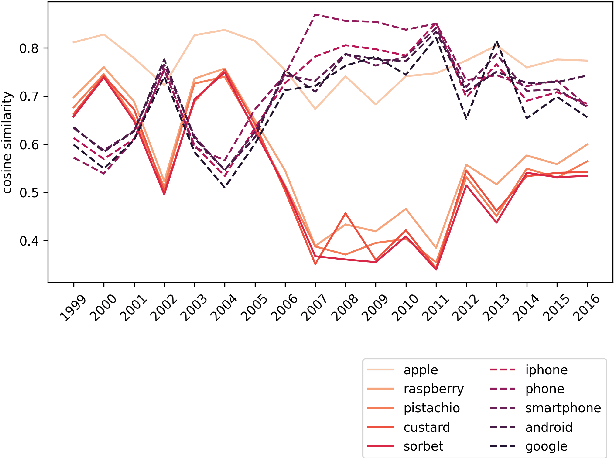
Complementary to finding good general word embeddings, an important question for representation learning is to find dynamic word embeddings, e.g., across time or domain. Current methods do not offer a way to use or predict information on structure between sub-corpora, time or domain and dynamic embeddings can only be compared after post-alignment. We propose novel word embedding methods that provide general word representations for the whole corpus, domain-specific representations for each sub-corpus, sub-corpus structure, and embedding alignment simultaneously. We present an empirical evaluation on New York Times articles and two English Wikipedia datasets with articles on science and philosophy. Our method, called Word2Vec with Structure Prediction (W2VPred), provides better performance than baselines in terms of the general analogy tests, domain-specific analogy tests, and multiple specific word embedding evaluations as well as structure prediction performance when no structure is given a priori. As a use case in the field of Digital Humanities we demonstrate how to raise novel research questions for high literature from the German Text Archive.
Every word counts: A multilingual analysis of individual human alignment with model attention
Oct 05, 2022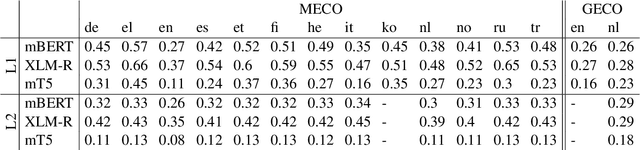
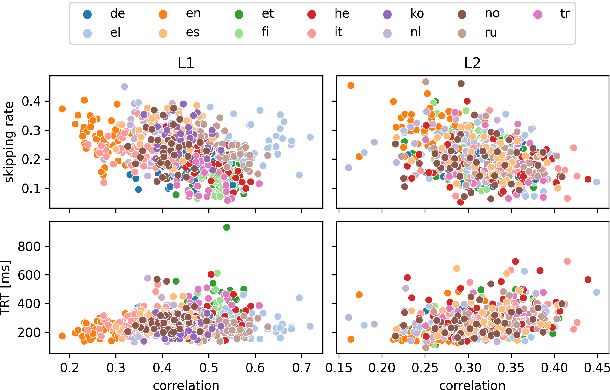
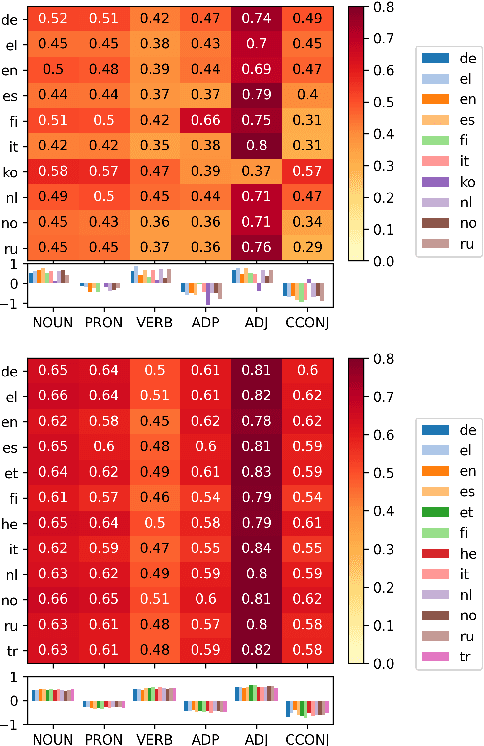
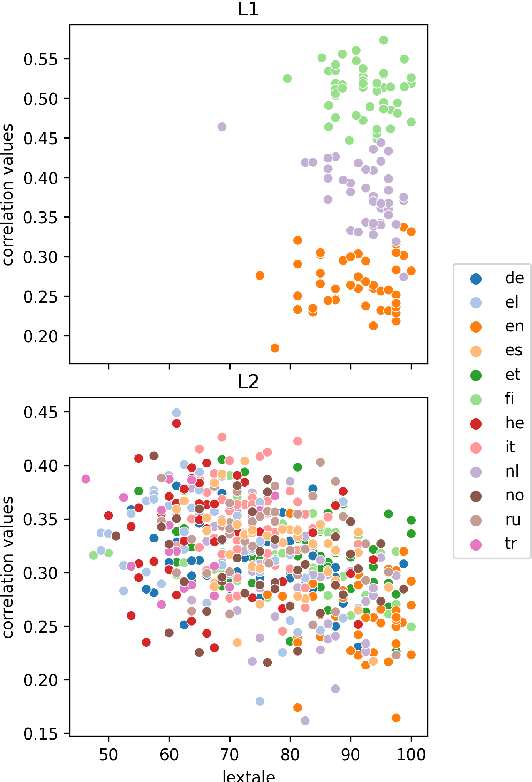
Human fixation patterns have been shown to correlate strongly with Transformer-based attention. Those correlation analyses are usually carried out without taking into account individual differences between participants and are mostly done on monolingual datasets making it difficult to generalise findings. In this paper, we analyse eye-tracking data from speakers of 13 different languages reading both in their native language (L1) and in English as language learners (L2). We find considerable differences between languages but also that individual reading behaviour such as skipping rate, total reading time and vocabulary knowledge (LexTALE) influence the alignment between humans and models to an extent that should be considered in future studies.
How Conservative are Language Models? Adapting to the Introduction of Gender-Neutral Pronouns
Apr 11, 2022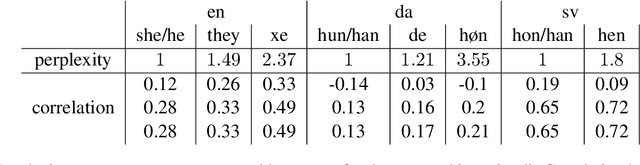


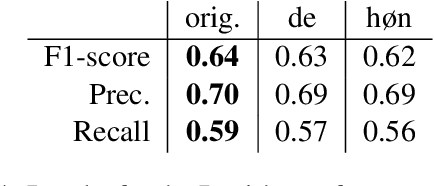
Gender-neutral pronouns have recently been introduced in many languages to a) include non-binary people and b) as a generic singular. Recent results from psycho-linguistics suggest that gender-neutral pronouns (in Swedish) are not associated with human processing difficulties. This, we show, is in sharp contrast with automated processing. We show that gender-neutral pronouns in Danish, English, and Swedish are associated with higher perplexity, more dispersed attention patterns, and worse downstream performance. We argue that such conservativity in language models may limit widespread adoption of gender-neutral pronouns and must therefore be resolved.