 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing zero-shot self-explanations with human rationales in multilingual text classification
Paper and Code
Oct 04, 2024
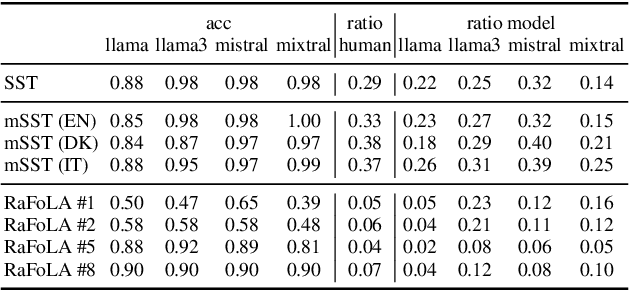

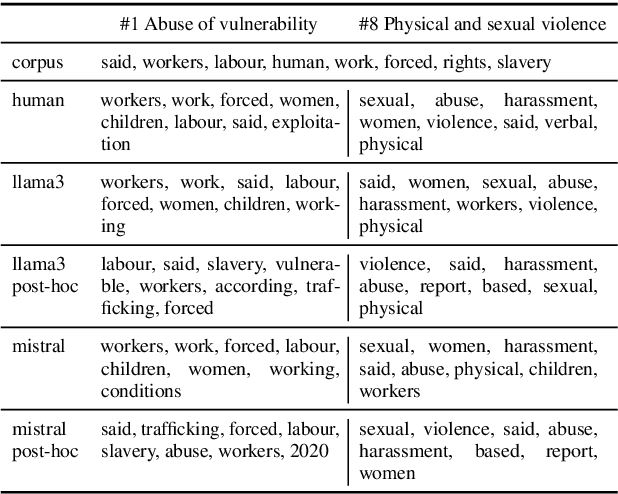
Instruction-tuned LLMs are able to provide an explanation about their output to users by generating self-explanations that do not require gradient computations or the application of possibly complex XAI methods. In this paper, we analyse whether this ability results in a good explanation by evaluating self-explanations in the form of input rationales with respect to their plausibility to humans as well as their faithfulness to models. For this, we apply two text classification tasks: sentiment classification and forced labour detection. Next to English, we further include Danish and Italian translations of the sentiment classification task and compare self-explanations to human annotations for all samples. To allow for direct comparisons, we also compute post-hoc feature attribution, i.e., layer-wise relevance propagation (LRP) and apply this pipeline to 4 LLMs (Llama2, Llama3, Mistral and Mixtral). Our results show that self-explanations align more closely with human annotations compared to LRP, while maintaining a comparable level of faithfulness.