 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Attention Heatmaps: How to Get Better Explanations for Multiple Instance Learning Models in Histopathology
Mar 09, 2026Multiple instance learning (MIL) has enabled substantial progress in computational histopathology, where a large amount of patches from gigapixel whole slide images are aggregated into slide-level predictions. Heatmaps are widely used to validate MIL models and to discover tissue biomarkers. Yet, the validity of these heatmaps has barely been investigated. In this work, we introduce a general framework for evaluating the quality of MIL heatmaps without requiring additional labels. We conduct a large-scale benchmark experiment to assess six explanation methods across histopathology task types (classification, regression, survival), MIL model architectures (Attention-, Transformer-, Mamba-based), and patch encoder backbones (UNI2, Virchow2). Our results show that explanation quality mostly depends on MIL model architecture and task type, with perturbation ("Single"), layer-wise relevance propagation (LRP), and integrated gradients (IG) consistently outperforming attention-based and gradient-based saliency heatmaps, which often fail to reflect model decision mechanisms. We further demonstrate the advanced capabilities of the best-performing explanation methods: (i) We provide a proof-of-concept that MIL heatmaps of a bulk gene expression prediction model can be correlated with spatial transcriptomics for biological validation, and (ii) showcase the discovery of distinct model strategies for predicting human papillomavirus (HPV) infection from head and neck cancer slides. Our work highlights the importance of validating MIL heatmaps and establishes that improved explainability can enable more reliable model validation and yield biological insights, making a case for a broader adoption of explainable AI in digital pathology. Our code is provided in a public GitHub repository: https://github.com/bifold-pathomics/xMIL/tree/xmil-journal
Position: We Need An Algorithmic Understanding of Generative AI
Jul 10, 2025
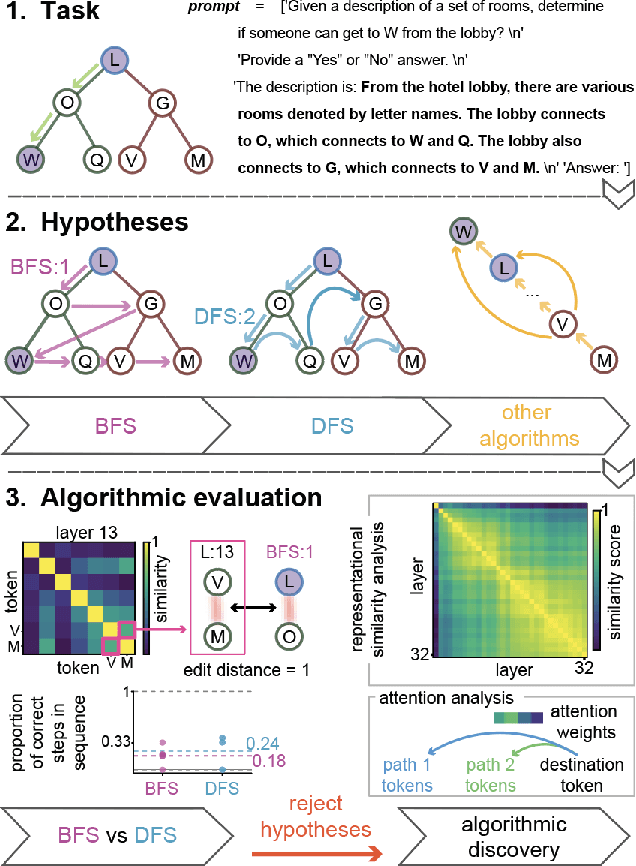


What algorithms do LLMs actually learn and use to solve problems? Studies addressing this question are sparse, as research priorities are focused on improving performance through scale, leaving a theoretical and empirical gap in understanding emergent algorithms. This position paper proposes AlgEval: a framework for systematic research into the algorithms that LLMs learn and use. AlgEval aims to uncover algorithmic primitives, reflected in latent representations, attention, and inference-time compute, and their algorithmic composition to solve task-specific problems. We highlight potential methodological paths and a case study toward this goal, focusing on emergent search algorithms. Our case study illustrates both the formation of top-down hypotheses about candidate algorithms, and bottom-up tests of these hypotheses via circuit-level analysis of attention patterns and hidden states. The rigorous, systematic evaluation of how LLMs actually solve tasks provides an alternative to resource-intensive scaling, reorienting the field toward a principled understanding of underlying computations. Such algorithmic explanations offer a pathway to human-understandable interpretability, enabling comprehension of the model's internal reasoning performance measures. This can in turn lead to more sample-efficient methods for training and improving performance, as well as novel architectures for end-to-end and multi-agent systems.
Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
Jun 18, 2025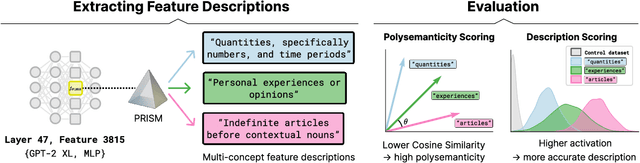

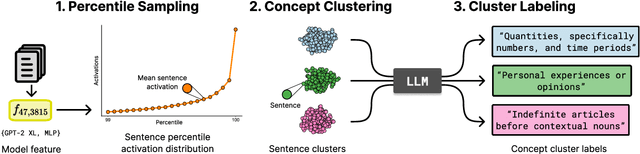

Automated interpretability research aims to identify concepts encoded in neural network features to enhance human understanding of model behavior. Current feature description methods face two critical challenges: limited robustness and the flawed assumption that each neuron encodes only a single concept (monosemanticity), despite growing evidence that neurons are often polysemantic. This assumption restricts the expressiveness of feature descriptions and limits their ability to capture the full range of behaviors encoded in model internals. To address this, we introduce Polysemantic FeatuRe Identification and Scoring Method (PRISM), a novel framework that captures the inherent complexity of neural network features. Unlike prior approaches that assign a single description per feature, PRISM provides more nuanced descriptions for both polysemantic and monosemantic features. We apply PRISM to language models and, through extensive benchmarking against existing methods, demonstrate that our approach produces more accurate and faithful feature descriptions, improving both overall description quality (via a description score) and the ability to capture distinct concepts when polysemanticity is present (via a polysemanticity score).
Cat, Rat, Meow: On the Alignment of Language Model and Human Term-Similarity Judgments
Apr 10, 2025Small and mid-sized generative language models have gained increasing attention. Their size and availability make them amenable to being analyzed at a behavioral as well as a representational level, allowing investigations of how these levels interact. We evaluate 32 publicly available language models for their representational and behavioral alignment with human similarity judgments on a word triplet task. This provides a novel evaluation setting to probe semantic associations in language beyond common pairwise comparisons. We find that (1) even the representations of small language models can achieve human-level alignment, (2) instruction-tuned model variants can exhibit substantially increased agreement, (3) the pattern of alignment across layers is highly model dependent, and (4) alignment based on models' behavioral responses is highly dependent on model size, matching their representational alignment only for the largest evaluated models.
Comparing zero-shot self-explanations with human rationales in multilingual text classification
Oct 04, 2024
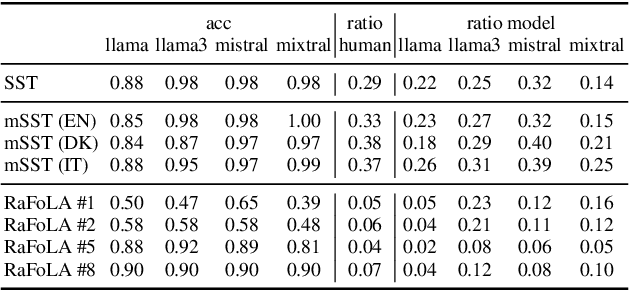

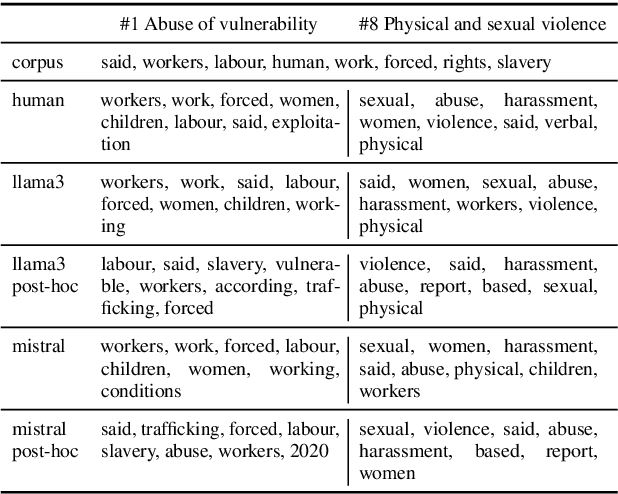
Instruction-tuned LLMs are able to provide an explanation about their output to users by generating self-explanations that do not require gradient computations or the application of possibly complex XAI methods. In this paper, we analyse whether this ability results in a good explanation by evaluating self-explanations in the form of input rationales with respect to their plausibility to humans as well as their faithfulness to models. For this, we apply two text classification tasks: sentiment classification and forced labour detection. Next to English, we further include Danish and Italian translations of the sentiment classification task and compare self-explanations to human annotations for all samples. To allow for direct comparisons, we also compute post-hoc feature attribution, i.e., layer-wise relevance propagation (LRP) and apply this pipeline to 4 LLMs (Llama2, Llama3, Mistral and Mixtral). Our results show that self-explanations align more closely with human annotations compared to LRP, while maintaining a comparable level of faithfulness.
MambaLRP: Explaining Selective State Space Sequence Models
Jun 11, 2024



Recent sequence modeling approaches using Selective State Space Sequence Models, referred to as Mamba models, have seen a surge of interest. These models allow efficient processing of long sequences in linear time and are rapidly being adopted in a wide range of applications such as language modeling, demonstrating promising performance. To foster their reliable use in real-world scenarios, it is crucial to augment their transparency. Our work bridges this critical gap by bringing explainability, particularly Layer-wise Relevance Propagation (LRP), to the Mamba architecture. Guided by the axiom of relevance conservation, we identify specific components in the Mamba architecture, which cause unfaithful explanations. To remedy this issue, we propose MambaLRP, a novel algorithm within the LRP framework, which ensures a more stable and reliable relevance propagation through these components. Our proposed method is theoretically sound and excels in achieving state-of-the-art explanation performance across a diverse range of models and datasets. Moreover, MambaLRP facilitates a deeper inspection of Mamba architectures, uncovering various biases and evaluating their significance. It also enables the analysis of previous speculations regarding the long-range capabilities of Mamba models.
xMIL: Insightful Explanations for Multiple Instance Learning in Histopathology
Jun 06, 2024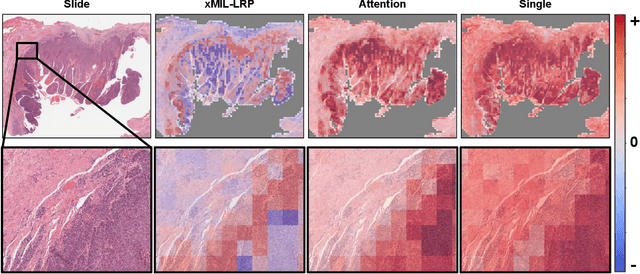
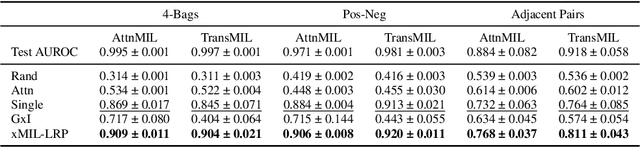
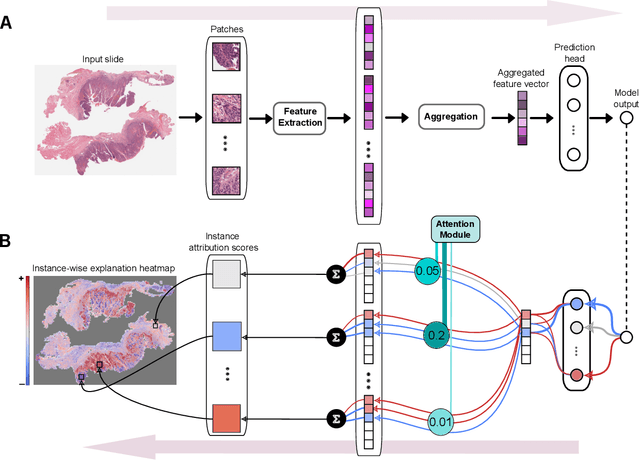
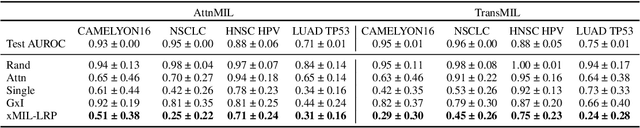
Multiple instance learning (MIL) is an effective and widely used approach for weakly supervised machine learning. In histopathology, MIL models have achieved remarkable success in tasks like tumor detection, biomarker prediction, and outcome prognostication. However, MIL explanation methods are still lagging behind, as they are limited to small bag sizes or disregard instance interactions. We revisit MIL through the lens of explainable AI (XAI) and introduce xMIL, a refined framework with more general assumptions. We demonstrate how to obtain improved MIL explanations using layer-wise relevance propagation (LRP) and conduct extensive evaluation experiments on three toy settings and four real-world histopathology datasets. Our approach consistently outperforms previous explanation attempts with particularly improved faithfulness scores on challenging biomarker prediction tasks. Finally, we showcase how xMIL explanations enable pathologists to extract insights from MIL models, representing a significant advance for knowledge discovery and model debugging in digital histopathology.
Explaining Text Similarity in Transformer Models
May 10, 2024



As Transformers have become state-of-the-art models for natural language processing (NLP) tasks, the need to understand and explain their predictions is increasingly apparent. Especially in unsupervised applications, such as information retrieval tasks, similarity models built on top of foundation model representations have been widely applied. However, their inner prediction mechanisms have mostly remained opaque. Recent advances in explainable AI have made it possible to mitigate these limitations by leveraging improved explanations for Transformers through layer-wise relevance propagation (LRP). Using BiLRP, an extension developed for computing second-order explanations in bilinear similarity models, we investigate which feature interactions drive similarity in NLP models. We validate the resulting explanations and demonstrate their utility in three corpus-level use cases, analyzing grammatical interactions, multilingual semantics, and biomedical text retrieval. Our findings contribute to a deeper understanding of different semantic similarity tasks and models, highlighting how novel explainable AI methods enable in-depth analyses and corpus-level insights.
Evaluating Webcam-based Gaze Data as an Alternative for Human Rationale Annotations
Feb 29, 2024Rationales in the form of manually annotated input spans usually serve as ground truth when evaluating explainability methods in NLP. They are, however, time-consuming and often biased by the annotation process. In this paper, we debate whether human gaze, in the form of webcam-based eye-tracking recordings, poses a valid alternative when evaluating importance scores. We evaluate the additional information provided by gaze data, such as total reading times, gaze entropy, and decoding accuracy with respect to human rationale annotations. We compare WebQAmGaze, a multilingual dataset for information-seeking QA, with attention and explainability-based importance scores for 4 different multilingual Transformer-based language models (mBERT, distil-mBERT, XLMR, and XLMR-L) and 3 languages (English, Spanish, and German). Our pipeline can easily be applied to other tasks and languages. Our findings suggest that gaze data offers valuable linguistic insights that could be leveraged to infer task difficulty and further show a comparable ranking of explainability methods to that of human rationales.
Rather a Nurse than a Physician -- Contrastive Explanations under Investigation
Oct 18, 2023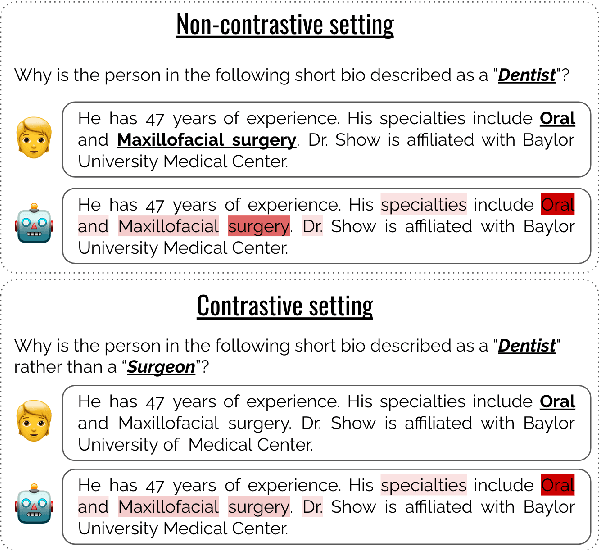
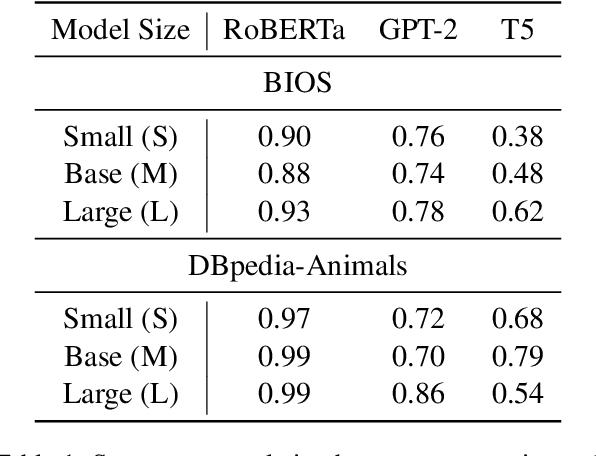

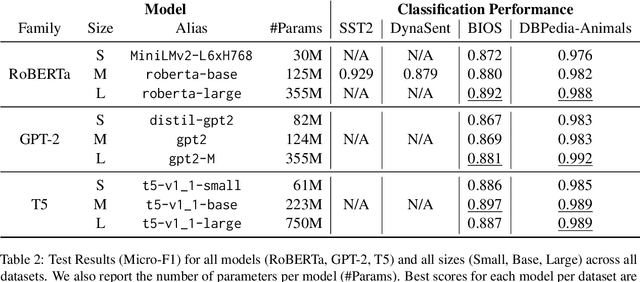
Contrastive explanations, where one decision is explained in contrast to another, are supposed to be closer to how humans explain a decision than non-contrastive explanations, where the decision is not necessarily referenced to an alternative. This claim has never been empirically validated. We analyze four English text-classification datasets (SST2, DynaSent, BIOS and DBpedia-Animals). We fine-tune and extract explanations from three different models (RoBERTa, GTP-2, and T5), each in three different sizes and apply three post-hoc explainability methods (LRP, GradientxInput, GradNorm). We furthermore collect and release human rationale annotations for a subset of 100 samples from the BIOS dataset for contrastive and non-contrastive settings. A cross-comparison between model-based rationales and human annotations, both in contrastive and non-contrastive settings, yields a high agreement between the two settings for models as well as for humans. Moreover, model-based explanations computed in both settings align equally well with human rationales. Thus, we empirically find that humans do not necessarily explain in a contrastive manner.9 pages, long paper at ACL 2022 proceedings.