 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Attention Heatmaps: How to Get Better Explanations for Multiple Instance Learning Models in Histopathology
Mar 09, 2026Multiple instance learning (MIL) has enabled substantial progress in computational histopathology, where a large amount of patches from gigapixel whole slide images are aggregated into slide-level predictions. Heatmaps are widely used to validate MIL models and to discover tissue biomarkers. Yet, the validity of these heatmaps has barely been investigated. In this work, we introduce a general framework for evaluating the quality of MIL heatmaps without requiring additional labels. We conduct a large-scale benchmark experiment to assess six explanation methods across histopathology task types (classification, regression, survival), MIL model architectures (Attention-, Transformer-, Mamba-based), and patch encoder backbones (UNI2, Virchow2). Our results show that explanation quality mostly depends on MIL model architecture and task type, with perturbation ("Single"), layer-wise relevance propagation (LRP), and integrated gradients (IG) consistently outperforming attention-based and gradient-based saliency heatmaps, which often fail to reflect model decision mechanisms. We further demonstrate the advanced capabilities of the best-performing explanation methods: (i) We provide a proof-of-concept that MIL heatmaps of a bulk gene expression prediction model can be correlated with spatial transcriptomics for biological validation, and (ii) showcase the discovery of distinct model strategies for predicting human papillomavirus (HPV) infection from head and neck cancer slides. Our work highlights the importance of validating MIL heatmaps and establishes that improved explainability can enable more reliable model validation and yield biological insights, making a case for a broader adoption of explainable AI in digital pathology. Our code is provided in a public GitHub repository: https://github.com/bifold-pathomics/xMIL/tree/xmil-journal
Uncovering the Structure of Explanation Quality with Spectral Analysis
Apr 11, 2025As machine learning models are increasingly considered for high-stakes domains, effective explanation methods are crucial to ensure that their prediction strategies are transparent to the user. Over the years, numerous metrics have been proposed to assess quality of explanations. However, their practical applicability remains unclear, in particular due to a limited understanding of which specific aspects each metric rewards. In this paper we propose a new framework based on spectral analysis of explanation outcomes to systematically capture the multifaceted properties of different explanation techniques. Our analysis uncovers two distinct factors of explanation quality-stability and target sensitivity-that can be directly observed through spectral decomposition. Experiments on both MNIST and ImageNet show that popular evaluation techniques (e.g., pixel-flipping, entropy) partially capture the trade-offs between these factors. Overall, our framework provides a foundational basis for understanding explanation quality, guiding the development of more reliable techniques for evaluating explanations.
Towards Symbolic XAI -- Explanation Through Human Understandable Logical Relationships Between Features
Aug 30, 2024Explainable Artificial Intelligence (XAI) plays a crucial role in fostering transparency and trust in AI systems, where traditional XAI approaches typically offer one level of abstraction for explanations, often in the form of heatmaps highlighting single or multiple input features. However, we ask whether abstract reasoning or problem-solving strategies of a model may also be relevant, as these align more closely with how humans approach solutions to problems. We propose a framework, called Symbolic XAI, that attributes relevance to symbolic queries expressing logical relationships between input features, thereby capturing the abstract reasoning behind a model's predictions. The methodology is built upon a simple yet general multi-order decomposition of model predictions. This decomposition can be specified using higher-order propagation-based relevance methods, such as GNN-LRP, or perturbation-based explanation methods commonly used in XAI. The effectiveness of our framework is demonstrated in the domains of natural language processing (NLP), vision, and quantum chemistry (QC), where abstract symbolic domain knowledge is abundant and of significant interest to users. The Symbolic XAI framework provides an understanding of the model's decision-making process that is both flexible for customization by the user and human-readable through logical formulas.
xMIL: Insightful Explanations for Multiple Instance Learning in Histopathology
Jun 06, 2024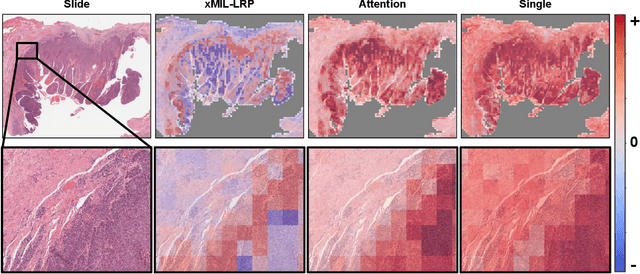
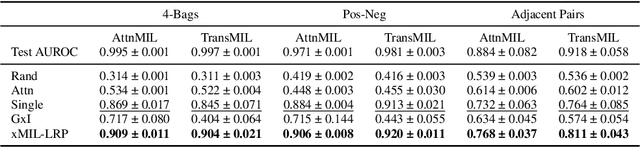
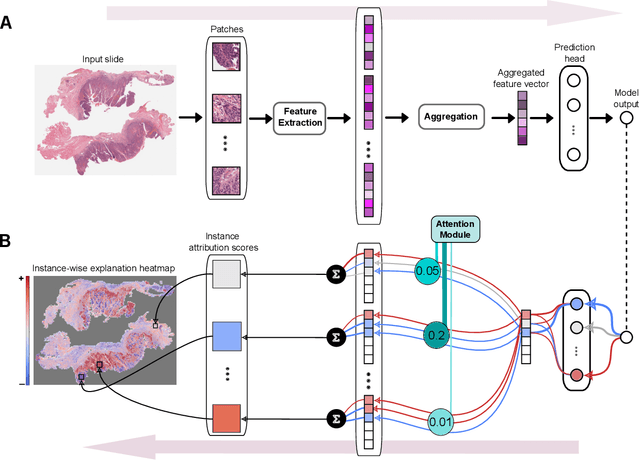
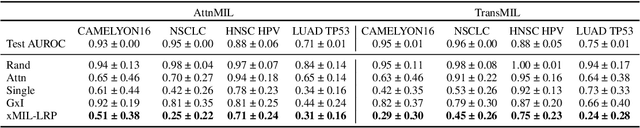
Multiple instance learning (MIL) is an effective and widely used approach for weakly supervised machine learning. In histopathology, MIL models have achieved remarkable success in tasks like tumor detection, biomarker prediction, and outcome prognostication. However, MIL explanation methods are still lagging behind, as they are limited to small bag sizes or disregard instance interactions. We revisit MIL through the lens of explainable AI (XAI) and introduce xMIL, a refined framework with more general assumptions. We demonstrate how to obtain improved MIL explanations using layer-wise relevance propagation (LRP) and conduct extensive evaluation experiments on three toy settings and four real-world histopathology datasets. Our approach consistently outperforms previous explanation attempts with particularly improved faithfulness scores on challenging biomarker prediction tasks. Finally, we showcase how xMIL explanations enable pathologists to extract insights from MIL models, representing a significant advance for knowledge discovery and model debugging in digital histopathology.
XAI for Transformers: Better Explanations through Conservative Propagation
Feb 15, 2022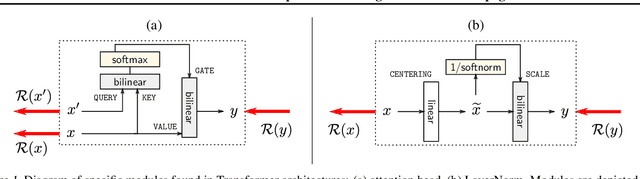
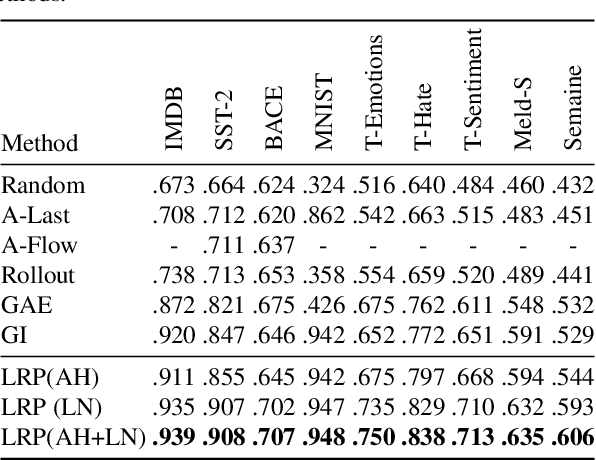
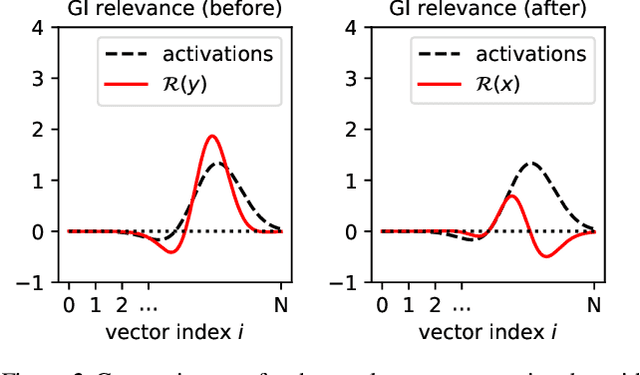
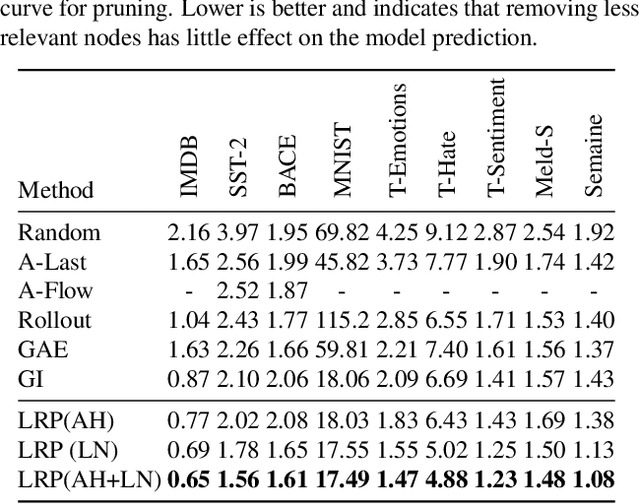
Transformers have become an important workhorse of machine learning, with numerous applications. This necessitates the development of reliable methods for increasing their transparency. Multiple interpretability methods, often based on gradient information, have been proposed. We show that the gradient in a Transformer reflects the function only locally, and thus fails to reliably identify the contribution of input features to the prediction. We identify Attention Heads and LayerNorm as main reasons for such unreliable explanations and propose a more stable way for propagation through these layers. Our proposal, which can be seen as a proper extension of the well-established LRP method to Transformers, is shown both theoretically and empirically to overcome the deficiency of a simple gradient-based approach, and achieves state-of-the-art explanation performance on a broad range of Transformer models and datasets.
XAI for Graphs: Explaining Graph Neural Network Predictions by Identifying Relevant Walks
Jun 12, 2020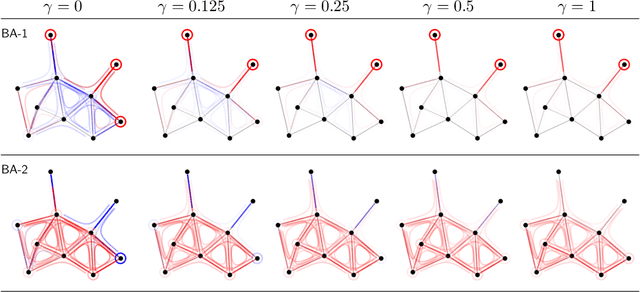
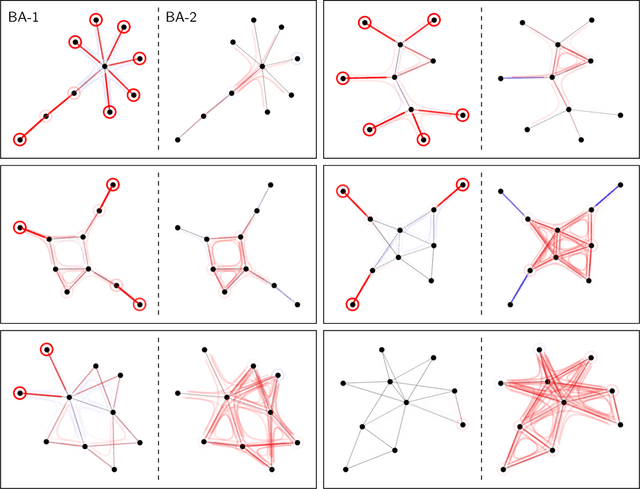
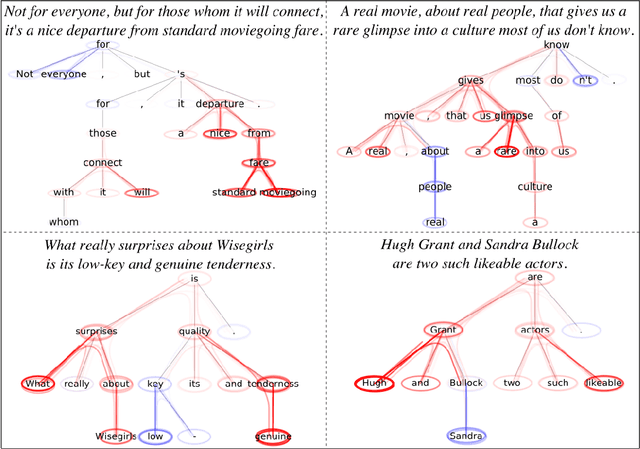
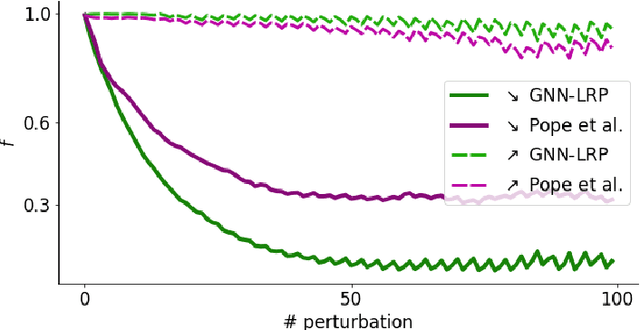
Graph Neural Networks (GNNs) are a popular approach for predicting graph structured data. As GNNs tightly entangle the input graph into the neural network structure, common explainable AI (XAI) approaches are not applicable. To a large extent, GNNs have remained black-boxes for the user so far. In this paper, we contribute by proposing a new XAI approach for GNNs. Our approach is derived from high-order Taylor expansions and is able to generate a decomposition of the GNN prediction as a collection of relevant walks on the input graph. We find that these high-order Taylor expansions can be equivalently (and more simply) computed using multiple backpropagation passes from the top layer of the GNN to the first layer. The explanation can then be further robustified and generalized by using layer-wise-relevance propagation (LRP) in place of the standard equations for gradient propagation. Our novel method which we denote as 'GNN-LRP' is tested on scale-free graphs, sentence parsing trees, molecular graphs, and pixel lattices representing images. In each case, it performs stably and accurately, and delivers interesting and novel application insights.