 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas 2 - Foundation models for clinical deployment
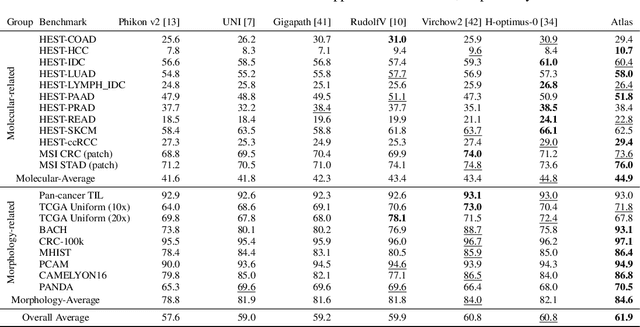
Jan 08, 2026Pathology foundation models substantially advanced the possibilities in computational pathology -- yet tradeoffs in terms of performance, robustness, and computational requirements remained, which limited their clinical deployment. In this report, we present Atlas 2, Atlas 2-B, and Atlas 2-S, three pathology vision foundation models which bridge these shortcomings by showing state-of-the-art performance in prediction performance, robustness, and resource efficiency in a comprehensive evaluation across eighty public benchmarks. Our models were trained on the largest pathology foundation model dataset to date comprising 5.5 million histopathology whole slide images, collected from three medical institutions Charité - Universtätsmedizin Berlin, LMU Munich, and Mayo Clinic.
Towards Robust Foundation Models for Digital Pathology
Jul 22, 2025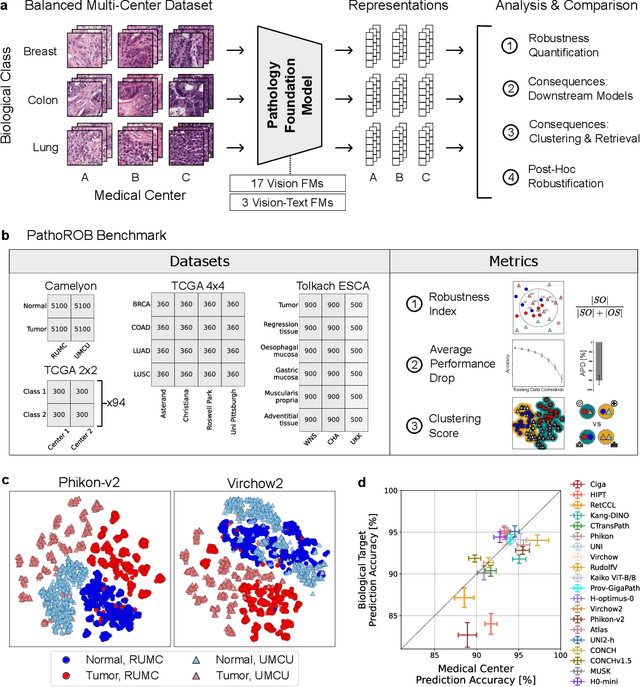
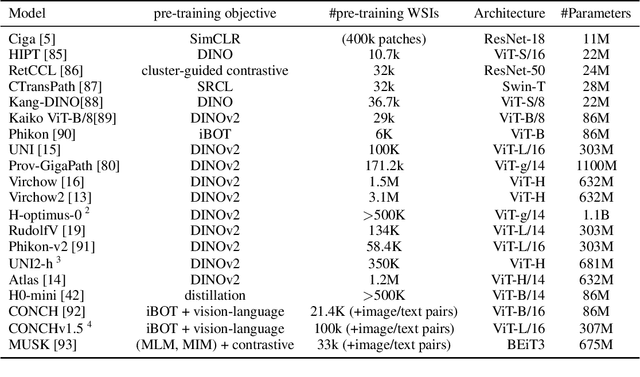
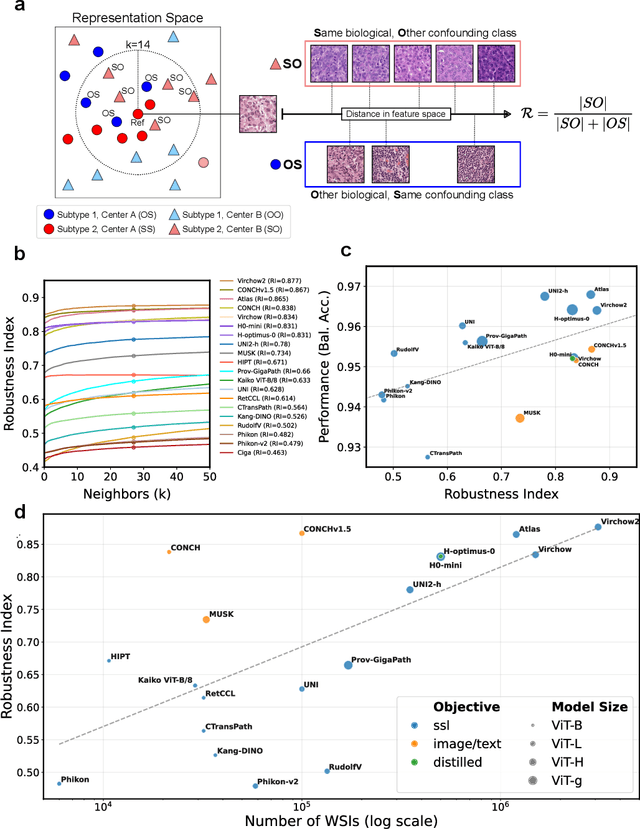

Biomedical Foundation Models (FMs) are rapidly transforming AI-enabled healthcare research and entering clinical validation. However, their susceptibility to learning non-biological technical features -- including variations in surgical/endoscopic techniques, laboratory procedures, and scanner hardware -- poses risks for clinical deployment. We present the first systematic investigation of pathology FM robustness to non-biological features. Our work (i) introduces measures to quantify FM robustness, (ii) demonstrates the consequences of limited robustness, and (iii) proposes a framework for FM robustification to mitigate these issues. Specifically, we developed PathoROB, a robustness benchmark with three novel metrics, including the robustness index, and four datasets covering 28 biological classes from 34 medical centers. Our experiments reveal robustness deficits across all 20 evaluated FMs, and substantial robustness differences between them. We found that non-robust FM representations can cause major diagnostic downstream errors and clinical blunders that prevent safe clinical adoption. Using more robust FMs and post-hoc robustification considerably reduced (but did not yet eliminate) the risk of such errors. This work establishes that robustness evaluation is essential for validating pathology FMs before clinical adoption and demonstrates that future FM development must integrate robustness as a core design principle. PathoROB provides a blueprint for assessing robustness across biomedical domains, guiding FM improvement efforts towards more robust, representative, and clinically deployable AI systems that prioritize biological information over technical artifacts.
Atlas: A Novel Pathology Foundation Model by Mayo Clinic, Charité, and Aignostics
Jan 10, 2025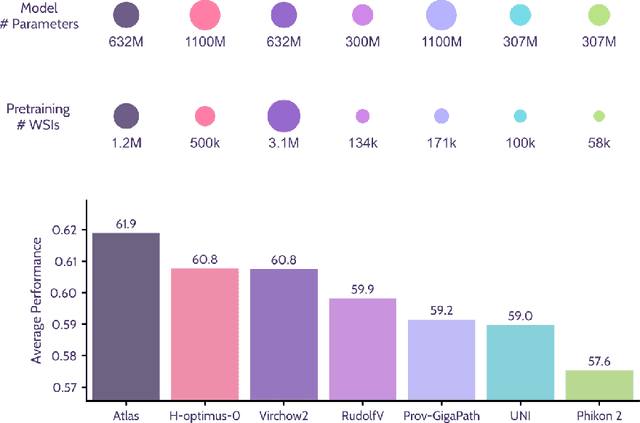
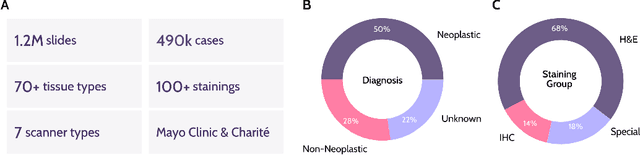
Recent advances in digital pathology have demonstrated the effectiveness of foundation models across diverse applications. In this report, we present Atlas, a novel vision foundation model based on the RudolfV approach. Our model was trained on a dataset comprising 1.2 million histopathology whole slide images, collected from two medical institutions: Mayo Clinic and Charit\'e - Universt\"atsmedizin Berlin. Comprehensive evaluations show that Atlas achieves state-of-the-art performance across twenty-one public benchmark datasets, even though it is neither the largest model by parameter count nor by training dataset size.
Training objective drives the consistency of representational similarity across datasets
Nov 08, 2024



The Platonic Representation Hypothesis claims that recent foundation models are converging to a shared representation space as a function of their downstream task performance, irrespective of the objectives and data modalities used to train these models. Representational similarity is generally measured for individual datasets and is not necessarily consistent across datasets. Thus, one may wonder whether this convergence of model representations is confounded by the datasets commonly used in machine learning. Here, we propose a systematic way to measure how representational similarity between models varies with the set of stimuli used to construct the representations. We find that the objective function is the most crucial factor in determining the consistency of representational similarities across datasets. Specifically, self-supervised vision models learn representations whose relative pairwise similarities generalize better from one dataset to another compared to those of image classification or image-text models. Moreover, the correspondence between representational similarities and the models' task behavior is dataset-dependent, being most strongly pronounced for single-domain datasets. Our work provides a framework for systematically measuring similarities of model representations across datasets and linking those similarities to differences in task behavior.
Do Histopathological Foundation Models Eliminate Batch Effects? A Comparative Study
Nov 08, 2024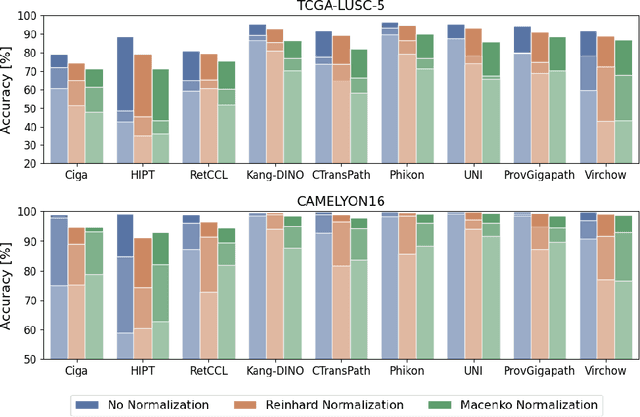

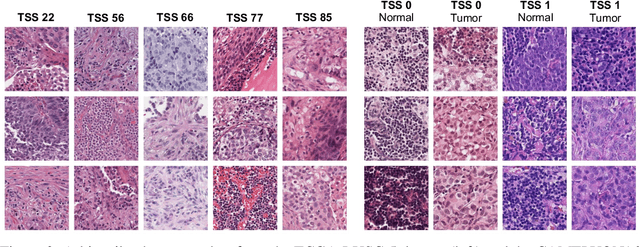
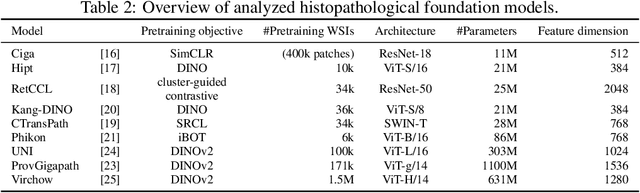
Deep learning has led to remarkable advancements in computational histopathology, e.g., in diagnostics, biomarker prediction, and outcome prognosis. Yet, the lack of annotated data and the impact of batch effects, e.g., systematic technical data differences across hospitals, hamper model robustness and generalization. Recent histopathological foundation models -- pretrained on millions to billions of images -- have been reported to improve generalization performances on various downstream tasks. However, it has not been systematically assessed whether they fully eliminate batch effects. In this study, we empirically show that the feature embeddings of the foundation models still contain distinct hospital signatures that can lead to biased predictions and misclassifications. We further find that the signatures are not removed by stain normalization methods, dominate distances in feature space, and are evident across various principal components. Our work provides a novel perspective on the evaluation of medical foundation models, paving the way for more robust pretraining strategies and downstream predictors.
The Clever Hans Effect in Unsupervised Learning
Aug 15, 2024Unsupervised learning has become an essential building block of AI systems. The representations it produces, e.g. in foundation models, are critical to a wide variety of downstream applications. It is therefore important to carefully examine unsupervised models to ensure not only that they produce accurate predictions, but also that these predictions are not "right for the wrong reasons", the so-called Clever Hans (CH) effect. Using specially developed Explainable AI techniques, we show for the first time that CH effects are widespread in unsupervised learning. Our empirical findings are enriched by theoretical insights, which interestingly point to inductive biases in the unsupervised learning machine as a primary source of CH effects. Overall, our work sheds light on unexplored risks associated with practical applications of unsupervised learning and suggests ways to make unsupervised learning more robust.
AI-based Anomaly Detection for Clinical-Grade Histopathological Diagnostics
Jun 21, 2024



While previous studies have demonstrated the potential of AI to diagnose diseases in imaging data, clinical implementation is still lagging behind. This is partly because AI models require training with large numbers of examples only available for common diseases. In clinical reality, however, only few diseases are common, whereas the majority of diseases are less frequent (long-tail distribution). Current AI models overlook or misclassify these diseases. We propose a deep anomaly detection approach that only requires training data from common diseases to detect also all less frequent diseases. We collected two large real-world datasets of gastrointestinal biopsies, which are prototypical of the problem. Herein, the ten most common findings account for approximately 90% of cases, whereas the remaining 10% contained 56 disease entities, including many cancers. 17 million histological images from 5,423 cases were used for training and evaluation. Without any specific training for the diseases, our best-performing model reliably detected a broad spectrum of infrequent ("anomalous") pathologies with 95.0% (stomach) and 91.0% (colon) AUROC and generalized across scanners and hospitals. By design, the proposed anomaly detection can be expected to detect any pathological alteration in the diagnostic tail of gastrointestinal biopsies, including rare primary or metastatic cancers. This study establishes the first effective clinical application of AI-based anomaly detection in histopathology that can flag anomalous cases, facilitate case prioritization, reduce missed diagnoses and enhance the general safety of AI models, thereby driving AI adoption and automation in routine diagnostics and beyond.
xMIL: Insightful Explanations for Multiple Instance Learning in Histopathology
Jun 06, 2024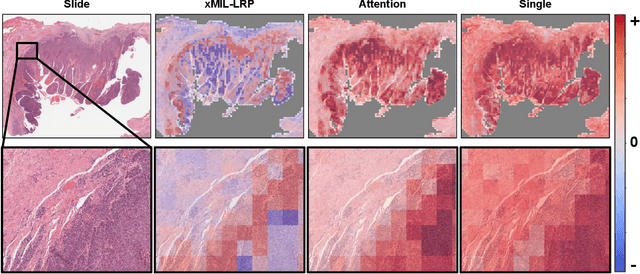
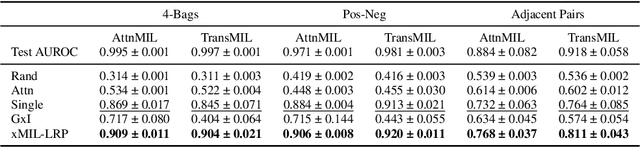
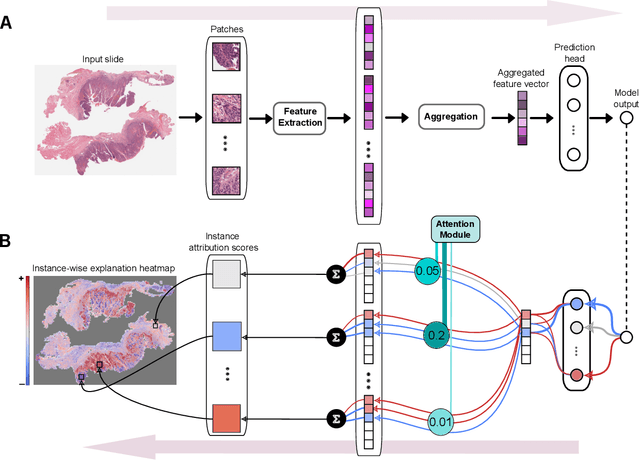
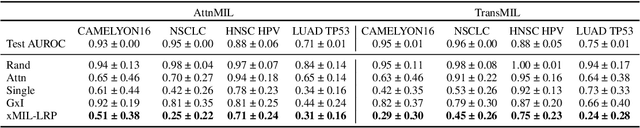
Multiple instance learning (MIL) is an effective and widely used approach for weakly supervised machine learning. In histopathology, MIL models have achieved remarkable success in tasks like tumor detection, biomarker prediction, and outcome prognostication. However, MIL explanation methods are still lagging behind, as they are limited to small bag sizes or disregard instance interactions. We revisit MIL through the lens of explainable AI (XAI) and introduce xMIL, a refined framework with more general assumptions. We demonstrate how to obtain improved MIL explanations using layer-wise relevance propagation (LRP) and conduct extensive evaluation experiments on three toy settings and four real-world histopathology datasets. Our approach consistently outperforms previous explanation attempts with particularly improved faithfulness scores on challenging biomarker prediction tasks. Finally, we showcase how xMIL explanations enable pathologists to extract insights from MIL models, representing a significant advance for knowledge discovery and model debugging in digital histopathology.
RudolfV: A Foundation Model by Pathologists for Pathologists
Jan 23, 2024



Histopathology plays a central role in clinical medicine and biomedical research. While artificial intelligence shows promising results on many pathological tasks, generalization and dealing with rare diseases, where training data is scarce, remains a challenge. Distilling knowledge from unlabeled data into a foundation model before learning from, potentially limited, labeled data provides a viable path to address these challenges. In this work, we extend the state of the art of foundation models for digital pathology whole slide images by semi-automated data curation and incorporating pathologist domain knowledge. Specifically, we combine computational and pathologist domain knowledge (1) to curate a diverse dataset of 103k slides corresponding to 750 million image patches covering data from different fixation, staining, and scanning protocols as well as data from different indications and labs across the EU and US, (2) for grouping semantically similar slides and tissue patches, and (3) to augment the input images during training. We evaluate the resulting model on a set of public and internal benchmarks and show that although our foundation model is trained with an order of magnitude less slides, it performs on par or better than competing models. We expect that scaling our approach to more data and larger models will further increase its performance and capacity to deal with increasingly complex real world tasks in diagnostics and biomedical research.
Improving neural network representations using human similarity judgments
Jun 07, 2023Deep neural networks have reached human-level performance on many computer vision tasks. However, the objectives used to train these networks enforce only that similar images are embedded at similar locations in the representation space, and do not directly constrain the global structure of the resulting space. Here, we explore the impact of supervising this global structure by linearly aligning it with human similarity judgments. We find that a naive approach leads to large changes in local representational structure that harm downstream performance. Thus, we propose a novel method that aligns the global structure of representations while preserving their local structure. This global-local transform considerably improves accuracy across a variety of few-shot learning and anomaly detection tasks. Our results indicate that human visual representations are globally organized in a way that facilitates learning from few examples, and incorporating this global structure into neural network representations improves performance on downstream tasks.