 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Modeling of Distribution Shifts via Displacement-Reshaped Optimal Transport
May 06, 2026Optimal transport (OT) is a central framework for modeling distribution shifts. Because OT compares distributions directly in input space, a well-designed ground metric between observations is essential to ensure that the optimizer does not violate the true geometry of change. We propose Displacement-Reshaped Optimal Transport (ReshapeOT), a method that reshapes the ground metric by integrating observed sample displacements as an additional source of knowledge. Technically, ReshapeOT replaces the Euclidean metric with a Mahalanobis distance estimated from displacement second moments. This effectively carves expressways through the input space, inviting transport solutions that better align with observed displacements. Our method is computationally lightweight, integrates seamlessly into any OT solver that operates on a cost matrix, and can be kernelized for further flexibility. Experiments on synthetic and real-world data show that ReshapeOT achieves substantial gains in transport reliability. We further demonstrate our method's usefulness in two practical use cases.
Fast and Accurate Explanations of Distance-Based Classifiers by Uncovering Latent Explanatory Structures
Aug 05, 2025Distance-based classifiers, such as k-nearest neighbors and support vector machines, continue to be a workhorse of machine learning, widely used in science and industry. In practice, to derive insights from these models, it is also important to ensure that their predictions are explainable. While the field of Explainable AI has supplied methods that are in principle applicable to any model, it has also emphasized the usefulness of latent structures (e.g. the sequence of layers in a neural network) to produce explanations. In this paper, we contribute by uncovering a hidden neural network structure in distance-based classifiers (consisting of linear detection units combined with nonlinear pooling layers) upon which Explainable AI techniques such as layer-wise relevance propagation (LRP) become applicable. Through quantitative evaluations, we demonstrate the advantage of our novel explanation approach over several baselines. We also show the overall usefulness of explaining distance-based models through two practical use cases.
Wasserstein Distances Made Explainable: Insights into Dataset Shifts and Transport Phenomena
May 09, 2025Wasserstein distances provide a powerful framework for comparing data distributions. They can be used to analyze processes over time or to detect inhomogeneities within data. However, simply calculating the Wasserstein distance or analyzing the corresponding transport map (or coupling) may not be sufficient for understanding what factors contribute to a high or low Wasserstein distance. In this work, we propose a novel solution based on Explainable AI that allows us to efficiently and accurately attribute Wasserstein distances to various data components, including data subgroups, input features, or interpretable subspaces. Our method achieves high accuracy across diverse datasets and Wasserstein distance specifications, and its practical utility is demonstrated in two use cases.
The Clever Hans Effect in Unsupervised Learning
Aug 15, 2024Unsupervised learning has become an essential building block of AI systems. The representations it produces, e.g. in foundation models, are critical to a wide variety of downstream applications. It is therefore important to carefully examine unsupervised models to ensure not only that they produce accurate predictions, but also that these predictions are not "right for the wrong reasons", the so-called Clever Hans (CH) effect. Using specially developed Explainable AI techniques, we show for the first time that CH effects are widespread in unsupervised learning. Our empirical findings are enriched by theoretical insights, which interestingly point to inductive biases in the unsupervised learning machine as a primary source of CH effects. Overall, our work sheds light on unexplored risks associated with practical applications of unsupervised learning and suggests ways to make unsupervised learning more robust.
The Clever Hans Effect in Anomaly Detection
Jun 18, 2020

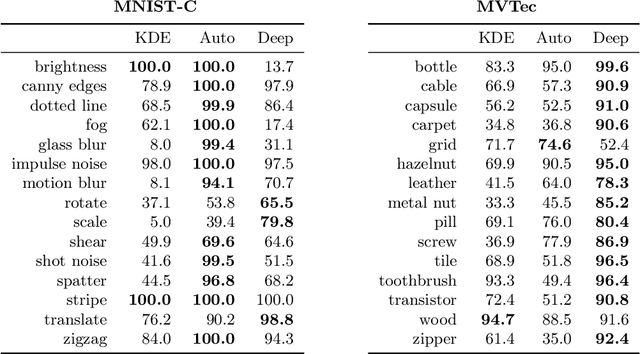
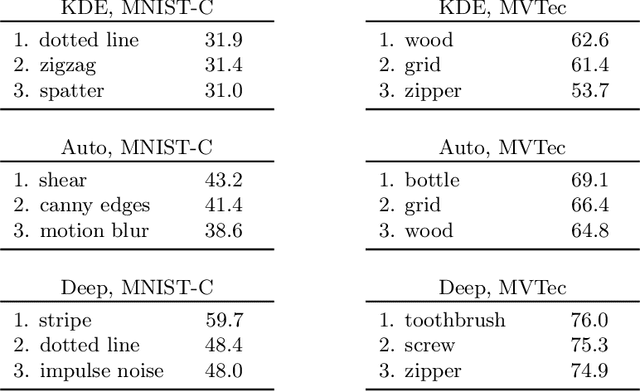
The 'Clever Hans' effect occurs when the learned model produces correct predictions based on the 'wrong' features. This effect which undermines the generalization capability of an ML model and goes undetected by standard validation techniques has been frequently observed for supervised learning where the training algorithm leverages spurious correlations in the data. The question whether Clever Hans also occurs in unsupervised learning, and in which form, has received so far almost no attention. Therefore, this paper will contribute an explainable AI (XAI) procedure that can highlight the relevant features used by popular anomaly detection models of different type. Our analysis reveals that the Clever Hans effect is widespread in anomaly detection and occurs in many (unexpected) forms. Interestingly, the observed Clever Hans effects are in this case not so much due to the data, but due to the anomaly detection models themselves whose structure makes them unable to detect the truly relevant features, even though vast amounts of data points are available. Overall, our work contributes a warning against an unrestrained use of existing anomaly detection models in practical applications, but it also points at a possible way out of the Clever Hans dilemma, specifically, by allowing multiple anomaly models to mutually cancel their individual structural weaknesses to jointly produce a better and more trustworthy anomaly detector.
From Clustering to Cluster Explanations via Neural Networks
Jun 18, 2019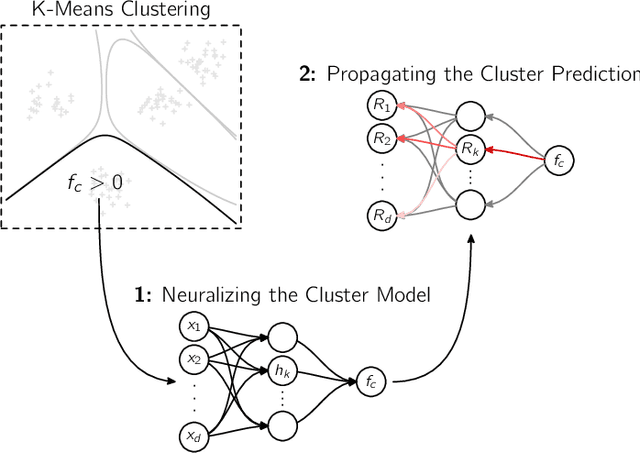
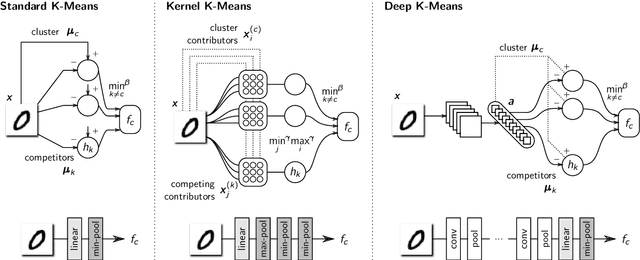
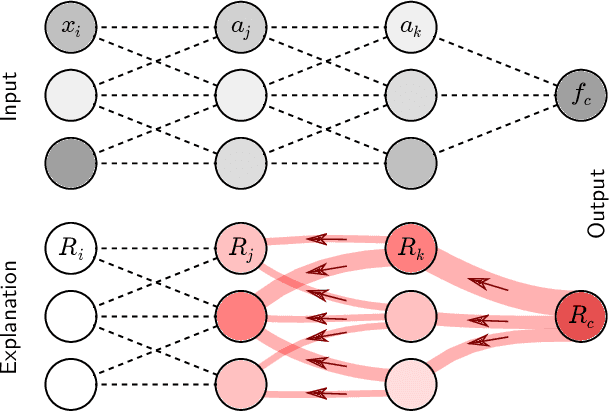

A wealth of algorithms have been developed to extract natural cluster structure in data. Identifying this structure is desirable but not always sufficient: We may also want to understand why the data points have been assigned to a given cluster. Clustering algorithms do not offer a systematic answer to this simple question. Hence we propose a new framework that can, for the first time, explain cluster assignments in terms of input features in a comprehensive manner. It is based on the novel theoretical insight that clustering models can be rewritten as neural networks, or 'neuralized'. Predictions of the obtained networks can then be quickly and accurately attributed to the input features. Several showcases demonstrate the ability of our method to assess the quality of learned clusters and to extract novel insights from the analyzed data and representations.
Unsupervised Detection and Explanation of Latent-class Contextual Anomalies
Jun 29, 2018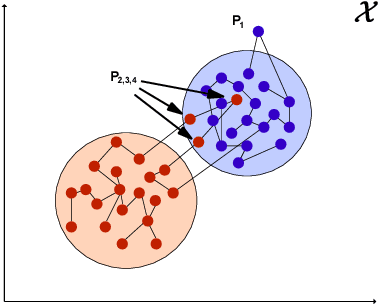
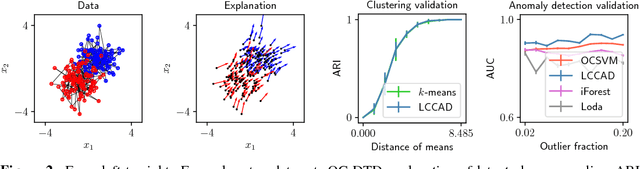
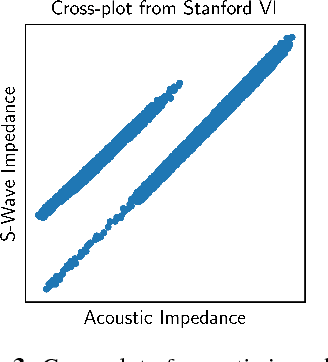
Detecting and explaining anomalies is a challenging effort. This holds especially true when data exhibits strong dependencies and single measurements need to be assessed and analyzed in their respective context. In this work, we consider scenarios where measurements are non-i.i.d, i.e. where samples are dependent on corresponding discrete latent variables which are connected through some given dependency structure, the contextual information. Our contribution is twofold: (i) Building atop of support vector data description (SVDD), we derive a method able to cope with latent-class dependency structure that can still be optimized efficiently. We further show that our approach neatly generalizes vanilla SVDD as well as k-means and conditional random fields (CRF) and provide a corresponding probabilistic interpretation. (ii) In unsupervised scenarios where it is not possible to quantify the accuracy of an anomaly detector, having an human-interpretable solution is the key to success. Based on deep Taylor decomposition and a reformulation of our trained anomaly detector as a neural network, we are able to backpropagate predictions to pixel-domain and thus identify features and regions of high relevance. We demonstrate the usefulness of our novel approach on toy data with known spatio-temporal structure and successfully validate on synthetic as well as real world off-shore data from the oil industry.
Towards Explaining Anomalies: A Deep Taylor Decomposition of One-Class Models
May 16, 2018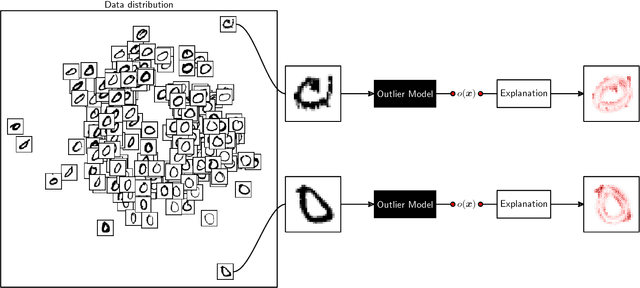

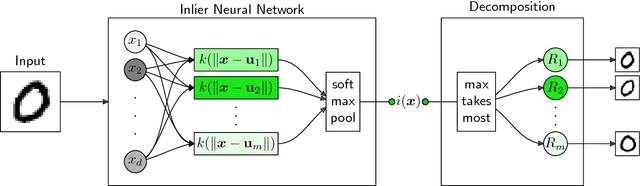
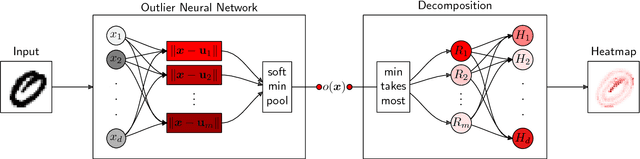
A common machine learning task is to discriminate between normal and anomalous data points. In practice, it is not always sufficient to reach high accuracy at this task, one also would like to understand why a given data point has been predicted in a certain way. We present a new principled approach for one-class SVMs that decomposes outlier predictions in terms of input variables. The method first recomposes the one-class model as a neural network with distance functions and min-pooling, and then performs a deep Taylor decomposition (DTD) of the model output. The proposed One-Class DTD is applicable to a number of common distance-based SVM kernels and is able to reliably explain a wide set of data anomalies. Furthermore, it outperforms baselines such as sensitivity analysis, nearest neighbor, or simple edge detection.