 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Clever Hans Effect in Anomaly Detection
Paper and Code
Jun 18, 2020

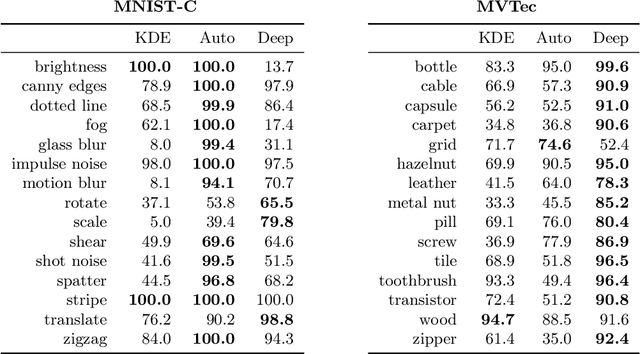
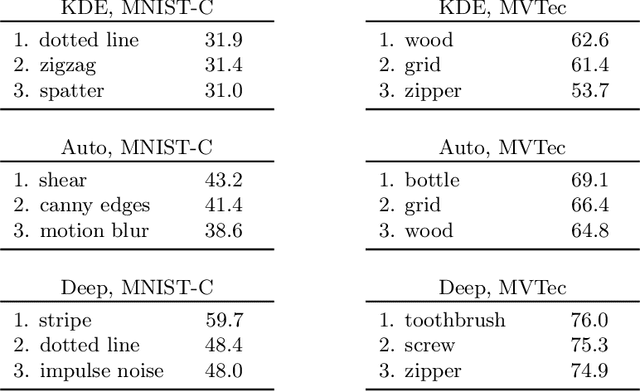
The 'Clever Hans' effect occurs when the learned model produces correct predictions based on the 'wrong' features. This effect which undermines the generalization capability of an ML model and goes undetected by standard validation techniques has been frequently observed for supervised learning where the training algorithm leverages spurious correlations in the data. The question whether Clever Hans also occurs in unsupervised learning, and in which form, has received so far almost no attention. Therefore, this paper will contribute an explainable AI (XAI) procedure that can highlight the relevant features used by popular anomaly detection models of different type. Our analysis reveals that the Clever Hans effect is widespread in anomaly detection and occurs in many (unexpected) forms. Interestingly, the observed Clever Hans effects are in this case not so much due to the data, but due to the anomaly detection models themselves whose structure makes them unable to detect the truly relevant features, even though vast amounts of data points are available. Overall, our work contributes a warning against an unrestrained use of existing anomaly detection models in practical applications, but it also points at a possible way out of the Clever Hans dilemma, specifically, by allowing multiple anomaly models to mutually cancel their individual structural weaknesses to jointly produce a better and more trustworthy anomaly detector.