 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explaining Anomalies: A Deep Taylor Decomposition of One-Class Models
Paper and Code
May 16, 2018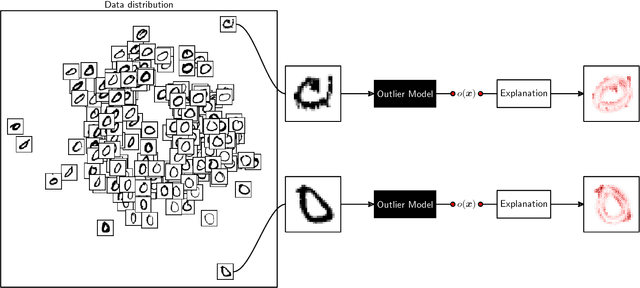

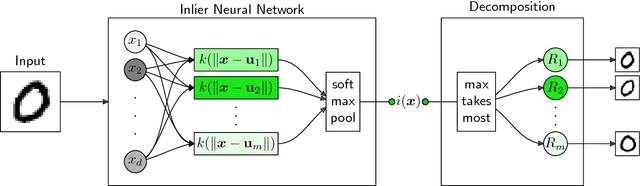
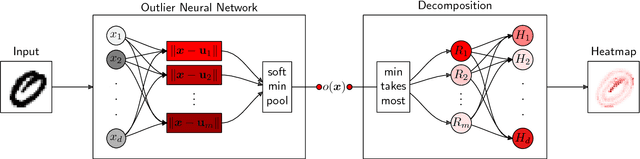
A common machine learning task is to discriminate between normal and anomalous data points. In practice, it is not always sufficient to reach high accuracy at this task, one also would like to understand why a given data point has been predicted in a certain way. We present a new principled approach for one-class SVMs that decomposes outlier predictions in terms of input variables. The method first recomposes the one-class model as a neural network with distance functions and min-pooling, and then performs a deep Taylor decomposition (DTD) of the model output. The proposed One-Class DTD is applicable to a number of common distance-based SVM kernels and is able to reliably explain a wide set of data anomalies. Furthermore, it outperforms baselines such as sensitivity analysis, nearest neighbor, or simple edge detection.