 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Temporal Graph Neural Networks via Feature-induced Information Flow
Jun 25, 2026Event-based Temporal Graph Neural Networks (ETGNNs) have demonstrated strong performance across a wide range of applications, including social network analysis, epidemic tracing, recommender systems, and political event forecasting. However, their increasing complexity poses significant challenges for explainability. Existing explanation methods focus only on a subset of the information flow within ETGNNs, typically tracing contributions from the event-related embeddings to the output. Consequently, they overlook the important pathways through event-induced variables, which mediate interactions between nodes and thereby play a central role in capturing long-range temporal dependencies. To overcome this limitation, we propose a novel attribution method that analyzes the \emph{entire} information flow through all event-associated variables. Our method is built upon the recent Normalized Relevance Measure (NRM) framework, which enables explicit quantification of information flow originating from event embeddings as well as information flow passing through event-induced variables. It also ensures comparability of latent variables across layers, and supports higher-order analysis of interactions between events. To handle the architectural complexity of ETGNNs, we extend the NRM framework with a modular decomposition procedure that facilitates the systematic construction of relevance structure for complex neural architectures. We evaluate our approach on two synthetic datasets for epidemic tracing and social dynamics, as well as a real-world dataset of political event networks. Our qualitative and quantitative experiments show that our method consistently outperforms existing explanation approaches while producing more human-interpretable explanations.
Structure-Preserving Correction Learning for Sparse Bayesian Inference in Brain Source Imaging
Jun 05, 2026Classical sparse Type-II Bayesian methods for M/EEG brain imaging support joint estimation of source and noise hyperparameters, but rely on fixed iterative update rules. Although these updates are principled and interpretable, their dynamics cannot be adapted from data. We propose to learn the update mechanism itself while preserving the underlying Bayesian structure by unfolding a classical joint hyperparameter-learning solver into a trainable neural architecture whose layers mirror the original iterations. The resulting framework is initialized to recover the classical solver exactly before training and is enriched through progressively more expressive correction-learning mechanisms, ranging from learnable biases to adaptive MLP and attention-based contextual refinements. In this way, training does not replace Bayesian inference with a black-box predictor, but instead learns structured correction terms while retaining the interpretability and model-based character of the original update dynamics. Structured correction learning therefore aims to improve empirical reconstruction performance without replacing the original model-based inference mechanism. Experimental results show that the learned correction variants improve reconstruction performance and convergence behavior over the baseline unfolded solver while preserving its algorithmic transparency.
Normalized Relevance Measure as a Unifying Framework to Explain Neural Network Latent Structures
May 30, 2026To understand how a neural network (NN) functions and makes predictions, it has become increasingly clear that analyzing only the input domain is insufficient -- one must also examine its internal inference mechanisms to capture the complete picture. To explain the internal inference mechanisms of such models, it is essential to analyze the importance of latent representations for a given task. In this paper, we propose the \emph{normalized relevance measure} (NRM) framework -- a novel general explanation procedure that attributes relevance to \emph{arbitrary sets of neurons across layers of arbitrary architectures}. In the NRM framework, relevance of selected neurons is explicitly defined as a normalized signed measure, constructed using simple operations -- marginalization and conditioning based on additive and multiplicative laws -- in analogy to the probability measures. The normalization property further guarantees comparability across layers. The NRM framework subsumes existing propagation-based explanation algorithms by explicitly identifying the underlying quantity being computed. We demonstrate the utility of the framework in computer vision applications, where joint relevance analysis across multiple layers reveals key information flows in VGG16 networks. Overall, the NRM framework provides a general, mathematically grounded approach to understanding how modern NNs propagate information, offering a versatile and broadly applicable foundation for explainable artificial intelligence.
Relevant Walk Search for Explaining Graph Neural Networks
May 22, 2026Graph Neural Networks (GNNs) have become important machine learning tools for graph analysis, and its explainability is crucial for safety, fairness, and robustness. Layer-wise relevance propagation for GNNs (GNN-LRP) evaluates the relevance of \emph{walks} to reveal important information flows in the network, and provides higher-order explanations, which have been shown to be superior to the lower-order, i.e., node-/edge-level, explanations. However, identifying relevant walks by GNN-LRP requires {\em exponential} computational complexity with respect to the network depth, which we will remedy in this paper. Specifically, we propose {\em polynomial-time} algorithms for finding top-$K$ relevant walks, which drastically reduces the computation and thus increases the applicability of GNN-LRP to large-scale problems. Our proposed algorithms are based on the \emph{max-product} algorithm -- a common tool for finding the maximum likelihood configurations in probabilistic graphical models -- and can find the most relevant walks exactly at the neuron level and approximately at the node level. Our experiments demonstrate the performance of our algorithms at scale and their utility across application domains, i.e., on epidemiology, molecular, and natural language benchmarks. We provide our codes under \href{https://github.com/xiong-ping/rel_walk_gnnlrp}{github.com/xiong-ping/rel\_walk\_gnnlrp}.
* Published in ICML 2023
Efficient Higher-order Subgraph Attribution via Message Passing
May 21, 2026Explaining graph neural networks (GNNs) has become more and more important recently. Higher-order interpretation schemes, such as GNN-LRP (layer-wise relevance propagation for GNN), emerged as powerful tools for unraveling how different features interact thereby contributing to explaining GNNs. GNN-LRP gives a relevance attribution of walks between nodes at each layer, and the subgraph attribution is expressed as a sum over exponentially many such walks. In this work, we demonstrate that such exponential complexity can be avoided. In particular, we propose novel algorithms that enable to attribute subgraphs with GNN-LRP in linear-time (w.r.t. the network depth). Our algorithms are derived via message passing techniques that make use of the distributive property, thereby directly computing quantities for higher-order explanations. We further adapt our efficient algorithms to compute a generalization of subgraph attributions that also takes into account the neighboring graph features. Experimental results show the significant acceleration of the proposed algorithms and demonstrate the high usefulness and scalability of our novel generalized subgraph attribution method.
* Published in ICML 2022
Beyond the final layer: Attentive multilayer fusion for vision transformers
Jan 14, 2026With the rise of large-scale foundation models, efficiently adapting them to downstream tasks remains a central challenge. Linear probing, which freezes the backbone and trains a lightweight head, is computationally efficient but often restricted to last-layer representations. We show that task-relevant information is distributed across the network hierarchy rather than solely encoded in any of the last layers. To leverage this distribution of information, we apply an attentive probing mechanism that dynamically fuses representations from all layers of a Vision Transformer. This mechanism learns to identify the most relevant layers for a target task and combines low-level structural cues with high-level semantic abstractions. Across 20 diverse datasets and multiple pretrained foundation models, our method achieves consistent, substantial gains over standard linear probes. Attention heatmaps further reveal that tasks different from the pre-training domain benefit most from intermediate representations. Overall, our findings underscore the value of intermediate layer information and demonstrate a principled, task aware approach for unlocking their potential in probing-based adaptation.
Uncovering the Structure of Explanation Quality with Spectral Analysis
Apr 11, 2025As machine learning models are increasingly considered for high-stakes domains, effective explanation methods are crucial to ensure that their prediction strategies are transparent to the user. Over the years, numerous metrics have been proposed to assess quality of explanations. However, their practical applicability remains unclear, in particular due to a limited understanding of which specific aspects each metric rewards. In this paper we propose a new framework based on spectral analysis of explanation outcomes to systematically capture the multifaceted properties of different explanation techniques. Our analysis uncovers two distinct factors of explanation quality-stability and target sensitivity-that can be directly observed through spectral decomposition. Experiments on both MNIST and ImageNet show that popular evaluation techniques (e.g., pixel-flipping, entropy) partially capture the trade-offs between these factors. Overall, our framework provides a foundational basis for understanding explanation quality, guiding the development of more reliable techniques for evaluating explanations.
Multilevel Generative Samplers for Investigating Critical Phenomena
Mar 13, 2025Investigating critical phenomena or phase transitions is of high interest in physics and chemistry, for which Monte Carlo (MC) simulations, a crucial tool for numerically analyzing macroscopic properties of given systems, are often hindered by an emerging divergence of correlation length -- known as scale invariance at criticality (SIC) in the renormalization group theory. SIC causes the system to behave the same at any length scale, from which many existing sampling methods suffer: long-range correlations cause critical slowing down in Markov chain Monte Carlo (MCMC), and require intractably large receptive fields for generative samplers. In this paper, we propose a Renormalization-informed Generative Critical Sampler (RiGCS) -- a novel sampler specialized for near-critical systems, where SIC is leveraged as an advantage rather than a nuisance. Specifically, RiGCS builds on MultiLevel Monte Carlo (MLMC) with Heat Bath (HB) algorithms, which perform ancestral sampling from low-resolution to high-resolution lattice configurations with site-wise-independent conditional HB sampling. Although MLMC-HB is highly efficient under exact SIC, it suffers from a low acceptance rate under slight SIC violation. Notably, SIC violation always occurs in finite-size systems, and may induce long-range and higher-order interactions in the renormalized distributions, which are not considered by independent HB samplers. RiGCS enhances MLMC-HB by replacing a part of the conditional HB sampler with generative models that capture those residual interactions and improve the sampling efficiency. Our experiments show that the effective sample size of RiGCS is a few orders of magnitude higher than state-of-the-art generative model baselines in sampling configurations for 128x128 two-dimensional Ising systems.
Enhancing Diffusion Models Efficiency by Disentangling Total-Variance and Signal-to-Noise Ratio
Feb 12, 2025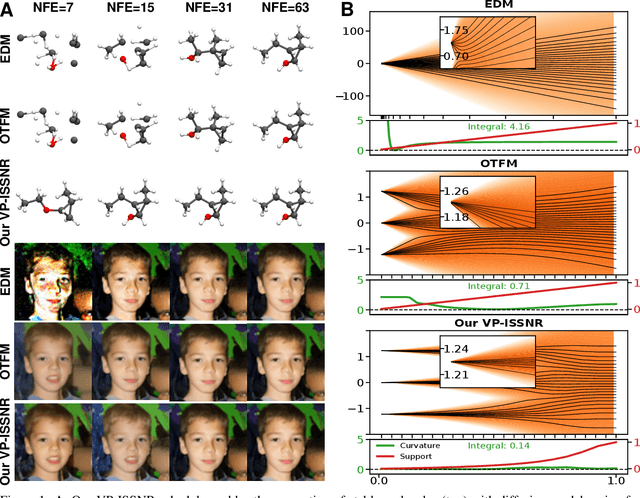
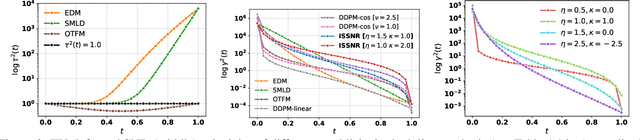
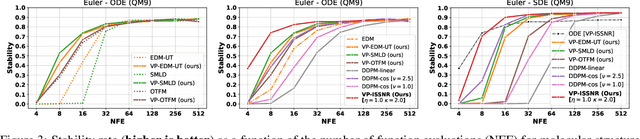
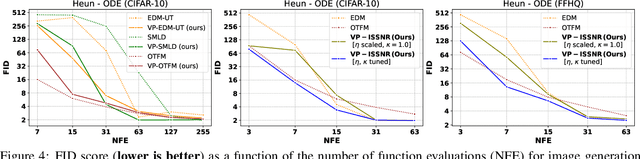
The long sampling time of diffusion models remains a significant bottleneck, which can be mitigated by reducing the number of diffusion time steps. However, the quality of samples with fewer steps is highly dependent on the noise schedule, i.e., the specific manner in which noise is introduced and the signal is reduced at each step. Although prior work has improved upon the original variance-preserving and variance-exploding schedules, these approaches $\textit{passively}$ adjust the total variance, without direct control over it. In this work, we propose a novel total-variance/signal-to-noise-ratio disentangled (TV/SNR) framework, where TV and SNR can be controlled independently. Our approach reveals that different existing schedules, where the TV explodes exponentially, can be $\textit{improved}$ by setting a constant TV schedule while preserving the same SNR schedule. Furthermore, generalizing the SNR schedule of the optimal transport flow matching significantly improves the performance in molecular structure generation, achieving few step generation of stable molecules. A similar tendency is observed in image generation, where our approach with a uniform diffusion time grid performs comparably to the highly tailored EDM sampler.
Bayesian Parameter Shift Rule in Variational Quantum Eigensolvers
Feb 04, 2025Parameter shift rules (PSRs) are key techniques for efficient gradient estimation in variational quantum eigensolvers (VQEs). In this paper, we propose its Bayesian variant, where Gaussian processes with appropriate kernels are used to estimate the gradient of the VQE objective. Our Bayesian PSR offers flexible gradient estimation from observations at arbitrary locations with uncertainty information and reduces to the generalized PSR in special cases. In stochastic gradient descent (SGD), the flexibility of Bayesian PSR allows the reuse of observations in previous steps, which accelerates the optimization process. Furthermore, the accessibility to the posterior uncertainty, along with our proposed notion of gradient confident region (GradCoRe), enables us to minimize the observation costs in each SGD step. Our numerical experiments show that the VQE optimization with Bayesian PSR and GradCoRe significantly accelerates SGD and outperforms the state-of-the-art methods, including sequential minimal optimization.