 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas 2 - Foundation models for clinical deployment
Jan 08, 2026Pathology foundation models substantially advanced the possibilities in computational pathology -- yet tradeoffs in terms of performance, robustness, and computational requirements remained, which limited their clinical deployment. In this report, we present Atlas 2, Atlas 2-B, and Atlas 2-S, three pathology vision foundation models which bridge these shortcomings by showing state-of-the-art performance in prediction performance, robustness, and resource efficiency in a comprehensive evaluation across eighty public benchmarks. Our models were trained on the largest pathology foundation model dataset to date comprising 5.5 million histopathology whole slide images, collected from three medical institutions Charité - Universtätsmedizin Berlin, LMU Munich, and Mayo Clinic.
Atlas: A Novel Pathology Foundation Model by Mayo Clinic, Charité, and Aignostics
Jan 10, 2025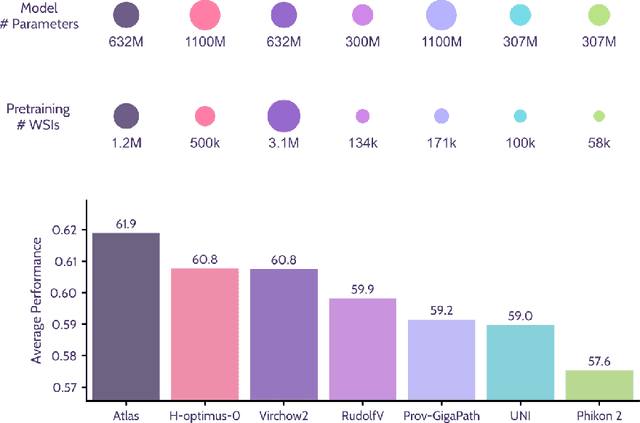
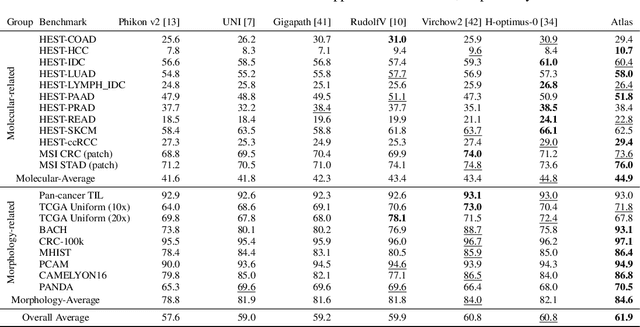
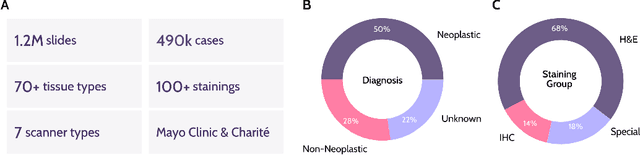
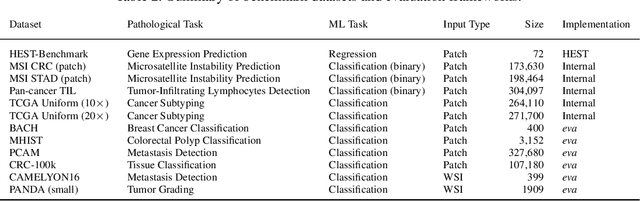
Recent advances in digital pathology have demonstrated the effectiveness of foundation models across diverse applications. In this report, we present Atlas, a novel vision foundation model based on the RudolfV approach. Our model was trained on a dataset comprising 1.2 million histopathology whole slide images, collected from two medical institutions: Mayo Clinic and Charit\'e - Universt\"atsmedizin Berlin. Comprehensive evaluations show that Atlas achieves state-of-the-art performance across twenty-one public benchmark datasets, even though it is neither the largest model by parameter count nor by training dataset size.
AI-based Anomaly Detection for Clinical-Grade Histopathological Diagnostics
Jun 21, 2024



While previous studies have demonstrated the potential of AI to diagnose diseases in imaging data, clinical implementation is still lagging behind. This is partly because AI models require training with large numbers of examples only available for common diseases. In clinical reality, however, only few diseases are common, whereas the majority of diseases are less frequent (long-tail distribution). Current AI models overlook or misclassify these diseases. We propose a deep anomaly detection approach that only requires training data from common diseases to detect also all less frequent diseases. We collected two large real-world datasets of gastrointestinal biopsies, which are prototypical of the problem. Herein, the ten most common findings account for approximately 90% of cases, whereas the remaining 10% contained 56 disease entities, including many cancers. 17 million histological images from 5,423 cases were used for training and evaluation. Without any specific training for the diseases, our best-performing model reliably detected a broad spectrum of infrequent ("anomalous") pathologies with 95.0% (stomach) and 91.0% (colon) AUROC and generalized across scanners and hospitals. By design, the proposed anomaly detection can be expected to detect any pathological alteration in the diagnostic tail of gastrointestinal biopsies, including rare primary or metastatic cancers. This study establishes the first effective clinical application of AI-based anomaly detection in histopathology that can flag anomalous cases, facilitate case prioritization, reduce missed diagnoses and enhance the general safety of AI models, thereby driving AI adoption and automation in routine diagnostics and beyond.
RudolfV: A Foundation Model by Pathologists for Pathologists
Jan 23, 2024



Histopathology plays a central role in clinical medicine and biomedical research. While artificial intelligence shows promising results on many pathological tasks, generalization and dealing with rare diseases, where training data is scarce, remains a challenge. Distilling knowledge from unlabeled data into a foundation model before learning from, potentially limited, labeled data provides a viable path to address these challenges. In this work, we extend the state of the art of foundation models for digital pathology whole slide images by semi-automated data curation and incorporating pathologist domain knowledge. Specifically, we combine computational and pathologist domain knowledge (1) to curate a diverse dataset of 103k slides corresponding to 750 million image patches covering data from different fixation, staining, and scanning protocols as well as data from different indications and labs across the EU and US, (2) for grouping semantically similar slides and tissue patches, and (3) to augment the input images during training. We evaluate the resulting model on a set of public and internal benchmarks and show that although our foundation model is trained with an order of magnitude less slides, it performs on par or better than competing models. We expect that scaling our approach to more data and larger models will further increase its performance and capacity to deal with increasingly complex real world tasks in diagnostics and biomedical research.