 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Segmentation Problems: Choose the Right Encoder and Skip the Decoder
Jul 29, 2022



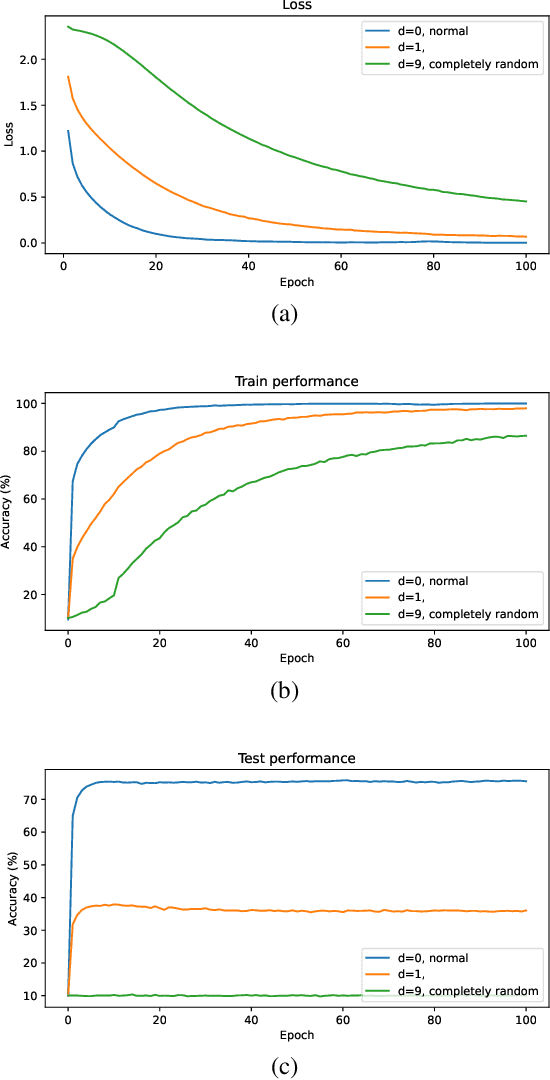
It is common practice to reuse models initially trained on different data to increase downstream task performance. Especially in the computer vision domain, ImageNet-pretrained weights have been successfully used for various tasks. In this work, we investigate the impact of transfer learning for segmentation problems, being pixel-wise classification problems that can be tackled with encoder-decoder architectures. We find that transfer learning the decoder does not help downstream segmentation tasks, while transfer learning the encoder is truly beneficial. We demonstrate that pretrained weights for a decoder may yield faster convergence, but they do not improve the overall model performance as one can obtain equivalent results with randomly initialized decoders. However, we show that it is more effective to reuse encoder weights trained on a segmentation or reconstruction task than reusing encoder weights trained on classification tasks. This finding implicates that using ImageNet-pretrained encoders for downstream segmentation problems is suboptimal. We also propose a contrastive self-supervised approach with multiple self-reconstruction tasks, which provides encoders that are suitable for transfer learning in segmentation problems in the absence of segmentation labels.
Similarity of Pre-trained and Fine-tuned Representations
Jul 19, 2022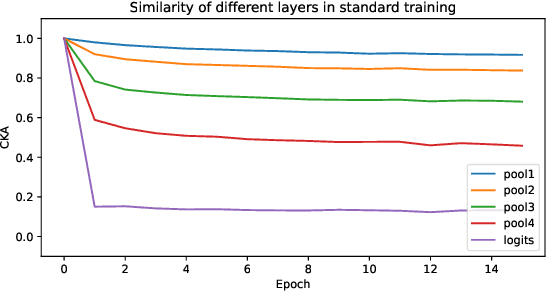


In transfer learning, only the last part of the networks - the so-called head - is often fine-tuned. Representation similarity analysis shows that the most significant change still occurs in the head even if all weights are updatable. However, recent results from few-shot learning have shown that representation change in the early layers, which are mostly convolutional, is beneficial, especially in the case of cross-domain adaption. In our paper, we find out whether that also holds true for transfer learning. In addition, we analyze the change of representation in transfer learning, both during pre-training and fine-tuning, and find out that pre-trained structure is unlearned if not usable.
Exploring the Similarity of Representations in Model-Agnostic Meta-Learning
May 12, 2021

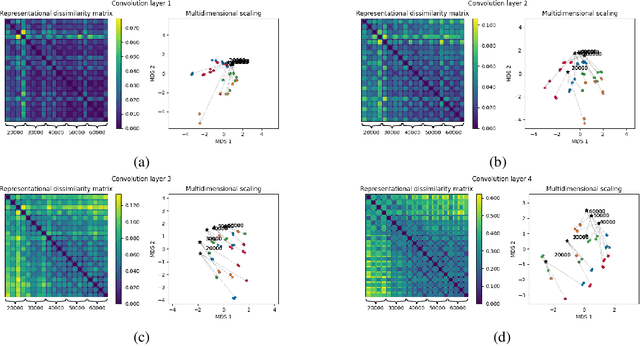
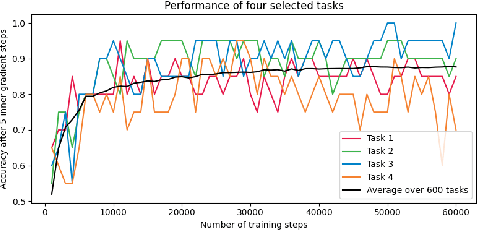
In past years model-agnostic meta-learning (MAML) has been one of the most promising approaches in meta-learning. It can be applied to different kinds of problems, e.g., reinforcement learning, but also shows good results on few-shot learning tasks. Besides their tremendous success in these tasks, it has still not been fully revealed yet, why it works so well. Recent work proposes that MAML rather reuses features than rapidly learns. In this paper, we want to inspire a deeper understanding of this question by analyzing MAML's representation. We apply representation similarity analysis (RSA), a well-established method in neuroscience, to the few-shot learning instantiation of MAML. Although some part of our analysis supports their general results that feature reuse is predominant, we also reveal arguments against their conclusion. The similarity-increase of layers closer to the input layers arises from the learning task itself and not from the model. In addition, the representations after inner gradient steps make a broader change to the representation than the changes during meta-training.