 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Segmentation Problems: Choose the Right Encoder and Skip the Decoder
Jul 29, 2022



It is common practice to reuse models initially trained on different data to increase downstream task performance. Especially in the computer vision domain, ImageNet-pretrained weights have been successfully used for various tasks. In this work, we investigate the impact of transfer learning for segmentation problems, being pixel-wise classification problems that can be tackled with encoder-decoder architectures. We find that transfer learning the decoder does not help downstream segmentation tasks, while transfer learning the encoder is truly beneficial. We demonstrate that pretrained weights for a decoder may yield faster convergence, but they do not improve the overall model performance as one can obtain equivalent results with randomly initialized decoders. However, we show that it is more effective to reuse encoder weights trained on a segmentation or reconstruction task than reusing encoder weights trained on classification tasks. This finding implicates that using ImageNet-pretrained encoders for downstream segmentation problems is suboptimal. We also propose a contrastive self-supervised approach with multiple self-reconstruction tasks, which provides encoders that are suitable for transfer learning in segmentation problems in the absence of segmentation labels.
Towards Fine-grained Visual Representations by Combining Contrastive Learning with Image Reconstruction and Attention-weighted Pooling
Apr 09, 2021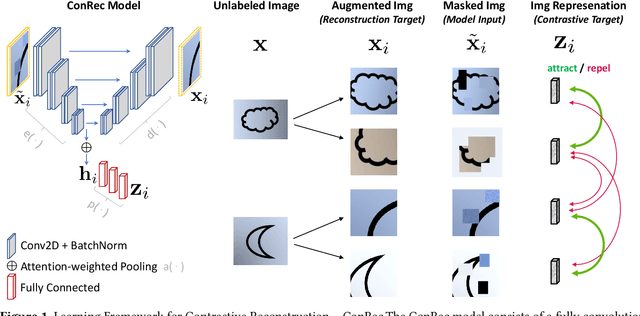
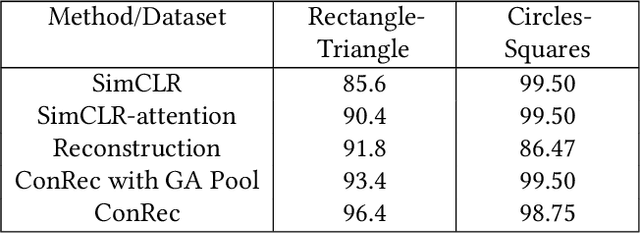
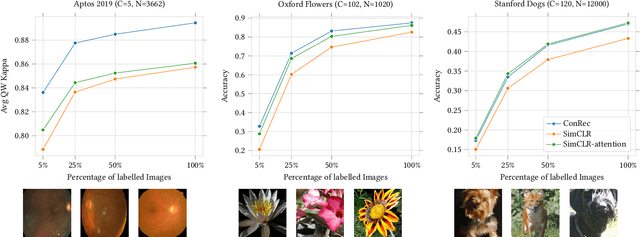

This paper presents Contrastive Reconstruction, ConRec - a self-supervised learning algorithm that obtains image representations by jointly optimizing a contrastive and a self-reconstruction loss. We showcase that state-of-the-art contrastive learning methods (e.g. SimCLR) have shortcomings to capture fine-grained visual features in their representations. ConRec extends the SimCLR framework by adding (1) a self-reconstruction task and (2) an attention mechanism within the contrastive learning task. This is accomplished by applying a simple encoder-decoder architecture with two heads. We show that both extensions contribute towards an improved vector representation for images with fine-grained visual features. Combining those concepts, ConRec outperforms SimCLR and SimCLR with Attention-Pooling on fine-grained classification datasets.
Chargrid-OCR: End-to-end trainable Optical Character Recognition through Semantic Segmentation and Object Detection
Sep 13, 2019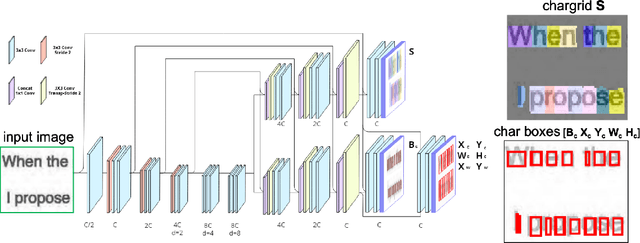
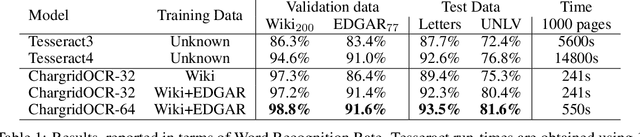

We present an end-to-end trainable approach for optical character recognition (OCR) on printed documents. It is based on predicting a two-dimensional character grid (\emph{chargrid}) representation of a document image as a semantic segmentation task. To identify individual character instances from the chargrid, we regard characters as objects and use object detection techniques from computer vision. We demonstrate experimentally that our method outperforms previous state-of-the-art approaches in accuracy while being easily parallelizable on GPU (therefore being significantly faster), as well as easier to train.
Chargrid: Towards Understanding 2D Documents
Sep 24, 2018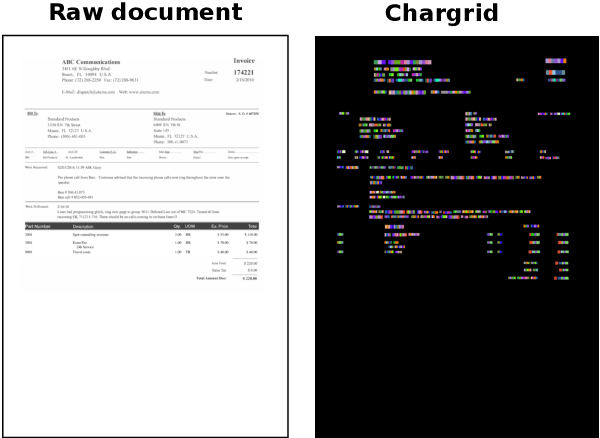

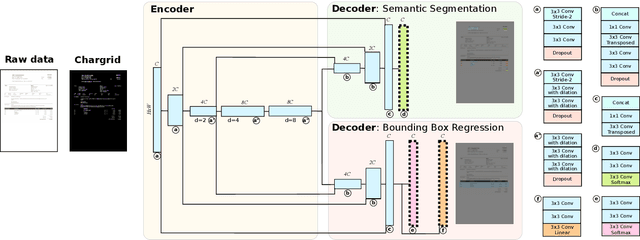
We introduce a novel type of text representation that preserves the 2D layout of a document. This is achieved by encoding each document page as a two-dimensional grid of characters. Based on this representation, we present a generic document understanding pipeline for structured documents. This pipeline makes use of a fully convolutional encoder-decoder network that predicts a segmentation mask and bounding boxes. We demonstrate its capabilities on an information extraction task from invoices and show that it significantly outperforms approaches based on sequential text or document images.
Multi-Target Shrinkage
Dec 05, 2014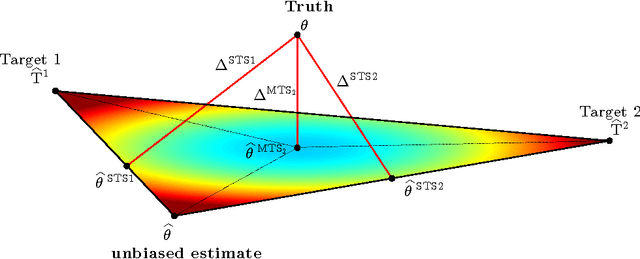
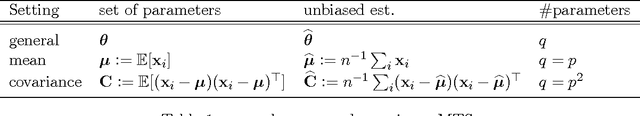
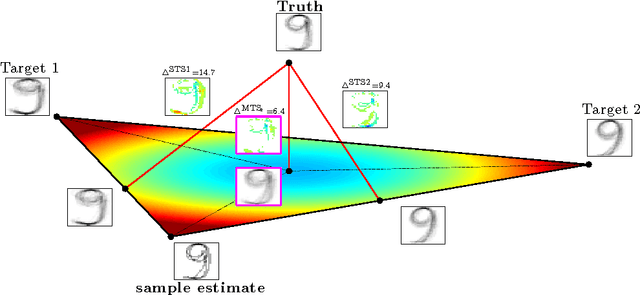

Stein showed that the multivariate sample mean is outperformed by "shrinking" to a constant target vector. Ledoit and Wolf extended this approach to the sample covariance matrix and proposed a multiple of the identity as shrinkage target. In a general framework, independent of a specific estimator, we extend the shrinkage concept by allowing simultaneous shrinkage to a set of targets. Application scenarios include settings with (A) additional data sets from potentially similar distributions, (B) non-stationarity, (C) a natural grouping of the data or (D) multiple alternative estimators which could serve as targets. We show that this Multi-Target Shrinkage can be translated into a quadratic program and derive conditions under which the estimation of the shrinkage intensities yields optimal expected squared error in the limit. For the sample mean and the sample covariance as specific instances, we derive conditions under which the optimality of MTS is applicable. We consider two asymptotic settings: the large dimensional limit (LDL), where the dimensionality and the number of observations go to infinity at the same rate, and the finite observations large dimensional limit (FOLDL), where only the dimensionality goes to infinity while the number of observations remains constant. We then show the effectiveness in extensive simulations and on real world data.