 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTgrid: Contextualized Embedding for 2D Document Representation and Understanding
Oct 14, 2019
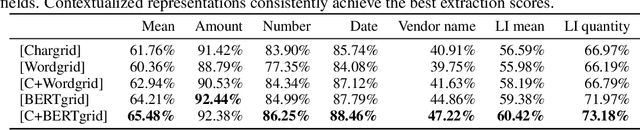

For understanding generic documents, information like font sizes, column layout, and generally the positioning of words may carry semantic information that is crucial for solving a downstream document intelligence task. Our novel BERTgrid, which is based on Chargrid by Katti et al. (2018), represents a document as a grid of contextualized word piece embedding vectors, thereby making its spatial structure and semantics accessible to the processing neural network. The contextualized embedding vectors are retrieved from a BERT language model. We use BERTgrid in combination with a fully convolutional network on a semantic instance segmentation task for extracting fields from invoices. We demonstrate its performance on tabulated line item and document header field extraction.
Chargrid-OCR: End-to-end trainable Optical Character Recognition through Semantic Segmentation and Object Detection
Sep 13, 2019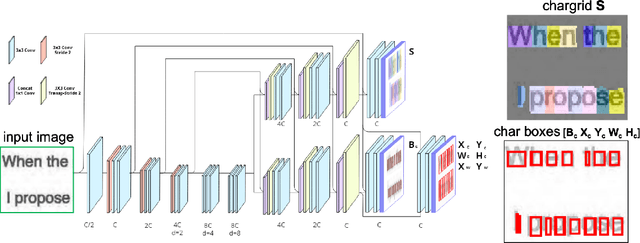
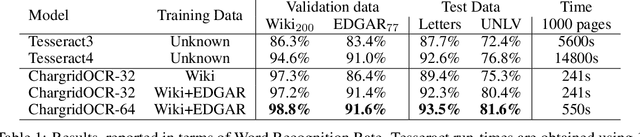

We present an end-to-end trainable approach for optical character recognition (OCR) on printed documents. It is based on predicting a two-dimensional character grid (\emph{chargrid}) representation of a document image as a semantic segmentation task. To identify individual character instances from the chargrid, we regard characters as objects and use object detection techniques from computer vision. We demonstrate experimentally that our method outperforms previous state-of-the-art approaches in accuracy while being easily parallelizable on GPU (therefore being significantly faster), as well as easier to train.
Chargrid: Towards Understanding 2D Documents
Sep 24, 2018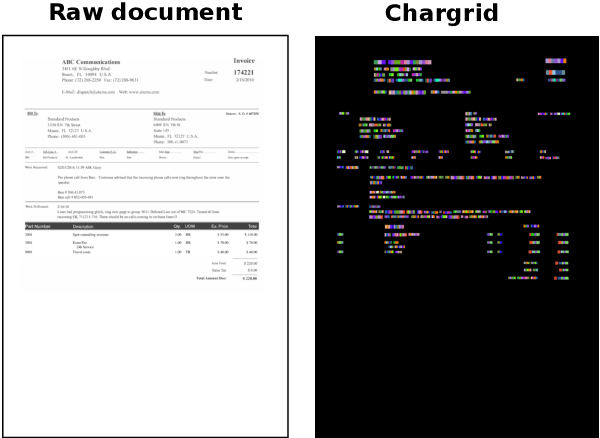

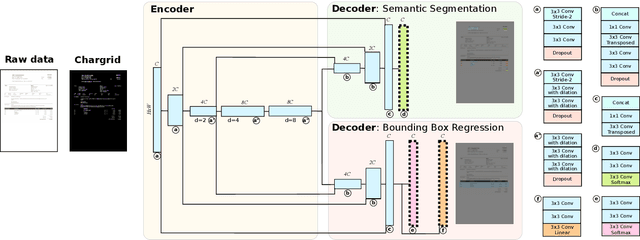
We introduce a novel type of text representation that preserves the 2D layout of a document. This is achieved by encoding each document page as a two-dimensional grid of characters. Based on this representation, we present a generic document understanding pipeline for structured documents. This pipeline makes use of a fully convolutional encoder-decoder network that predicts a segmentation mask and bounding boxes. We demonstrate its capabilities on an information extraction task from invoices and show that it significantly outperforms approaches based on sequential text or document images.