 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Brain2Music: Reconstructing Music from Human Brain Activity
Jul 20, 2023



The process of reconstructing experiences from human brain activity offers a unique lens into how the brain interprets and represents the world. In this paper, we introduce a method for reconstructing music from brain activity, captured using functional magnetic resonance imaging (fMRI). Our approach uses either music retrieval or the MusicLM music generation model conditioned on embeddings derived from fMRI data. The generated music resembles the musical stimuli that human subjects experienced, with respect to semantic properties like genre, instrumentation, and mood. We investigate the relationship between different components of MusicLM and brain activity through a voxel-wise encoding modeling analysis. Furthermore, we discuss which brain regions represent information derived from purely textual descriptions of music stimuli. We provide supplementary material including examples of the reconstructed music at https://google-research.github.io/seanet/brain2music
V2Meow: Meowing to the Visual Beat via Music Generation
May 11, 2023
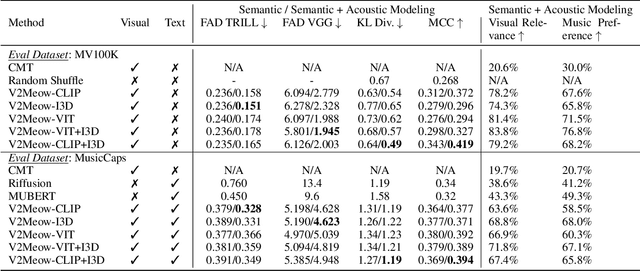

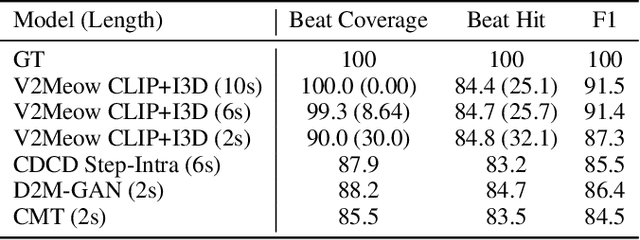
Generating high quality music that complements the visual content of a video is a challenging task. Most existing visual conditioned music generation systems generate symbolic music data, such as MIDI files, instead of raw audio waveform. Given the limited availability of symbolic music data, such methods can only generate music for a few instruments or for specific types of visual input. In this paper, we propose a novel approach called V2Meow that can generate high-quality music audio that aligns well with the visual semantics of a diverse range of video input types. Specifically, the proposed music generation system is a multi-stage autoregressive model which is trained with a number of O(100K) music audio clips paired with video frames, which are mined from in-the-wild music videos, and no parallel symbolic music data is involved. V2Meow is able to synthesize high-fidelity music audio waveform solely conditioned on pre-trained visual features extracted from an arbitrary silent video clip, and it also allows high-level control over the music style of generation examples via supporting text prompts in addition to the video frames conditioning. Through both qualitative and quantitative evaluations, we demonstrate that our model outperforms several existing music generation systems in terms of both visual-audio correspondence and audio quality.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023

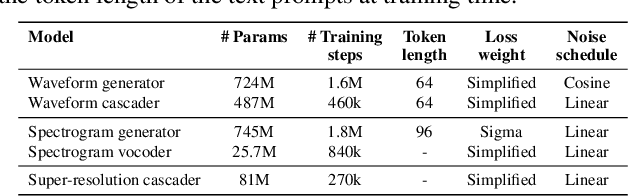
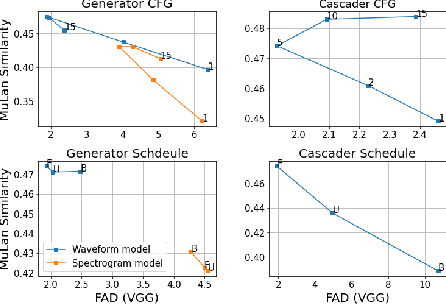
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
MusicLM: Generating Music From Text
Jan 26, 2023



We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
Contextual BERT: Conditioning the Language Model Using a Global State
Oct 29, 2020

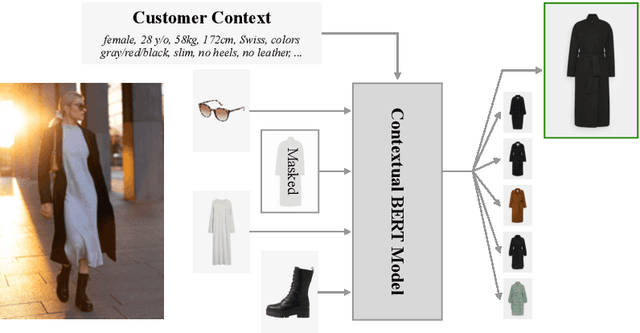
BERT is a popular language model whose main pre-training task is to fill in the blank, i.e., predicting a word that was masked out of a sentence, based on the remaining words. In some applications, however, having an additional context can help the model make the right prediction, e.g., by taking the domain or the time of writing into account. This motivates us to advance the BERT architecture by adding a global state for conditioning on a fixed-sized context. We present our two novel approaches and apply them to an industry use-case, where we complete fashion outfits with missing articles, conditioned on a specific customer. An experimental comparison to other methods from the literature shows that our methods improve personalization significantly.
BERTgrid: Contextualized Embedding for 2D Document Representation and Understanding
Oct 14, 2019
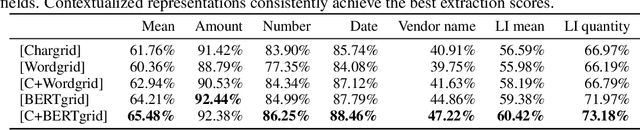

For understanding generic documents, information like font sizes, column layout, and generally the positioning of words may carry semantic information that is crucial for solving a downstream document intelligence task. Our novel BERTgrid, which is based on Chargrid by Katti et al. (2018), represents a document as a grid of contextualized word piece embedding vectors, thereby making its spatial structure and semantics accessible to the processing neural network. The contextualized embedding vectors are retrieved from a BERT language model. We use BERTgrid in combination with a fully convolutional network on a semantic instance segmentation task for extracting fields from invoices. We demonstrate its performance on tabulated line item and document header field extraction.