Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChargrid-OCR: End-to-end trainable Optical Character Recognition through Semantic Segmentation and Object Detection
Paper and Code
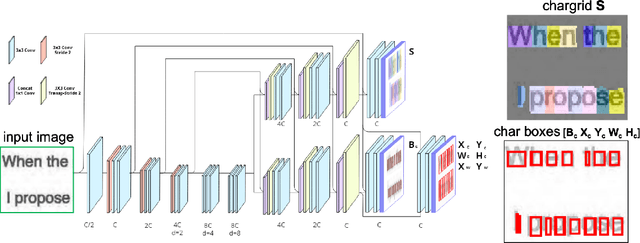
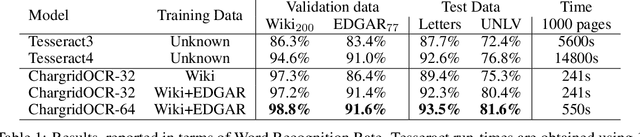

We present an end-to-end trainable approach for optical character recognition (OCR) on printed documents. It is based on predicting a two-dimensional character grid (\emph{chargrid}) representation of a document image as a semantic segmentation task. To identify individual character instances from the chargrid, we regard characters as objects and use object detection techniques from computer vision. We demonstrate experimentally that our method outperforms previous state-of-the-art approaches in accuracy while being easily parallelizable on GPU (therefore being significantly faster), as well as easier to train.
* 4 pages
View paper on
 OpenReview
OpenReview