 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Pointwise-Pairwise Learning-to-Rank for News Recommendation
Sep 26, 2024



News recommendation is a challenging task that involves personalization based on the interaction history and preferences of each user. Recent works have leveraged the power of pretrained language models (PLMs) to directly rank news items by using inference approaches that predominately fall into three categories: pointwise, pairwise, and listwise learning-to-rank. While pointwise methods offer linear inference complexity, they fail to capture crucial comparative information between items that is more effective for ranking tasks. Conversely, pairwise and listwise approaches excel at incorporating these comparisons but suffer from practical limitations: pairwise approaches are either computationally expensive or lack theoretical guarantees, and listwise methods often perform poorly in practice. In this paper, we propose a novel framework for PLM-based news recommendation that integrates both pointwise relevance prediction and pairwise comparisons in a scalable manner. We present a rigorous theoretical analysis of our framework, establishing conditions under which our approach guarantees improved performance. Extensive experiments show that our approach outperforms the state-of-the-art methods on the MIND and Adressa news recommendation datasets.
Overfitting in Bayesian Optimization: an empirical study and early-stopping solution
Apr 16, 2021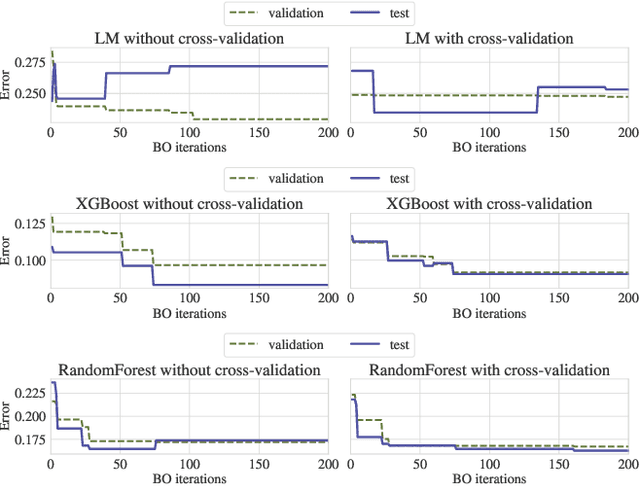
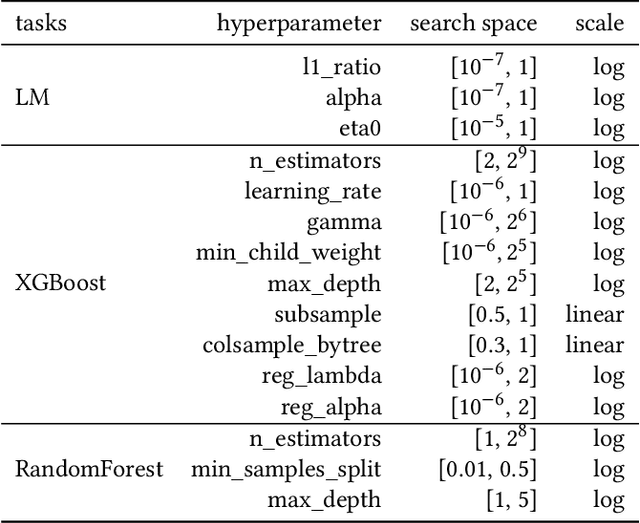
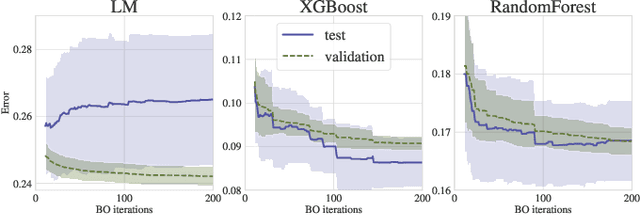
Bayesian Optimization (BO) is a successful methodology to tune the hyperparameters of machine learning algorithms. The user defines a metric of interest, such as the validation error, and BO finds the optimal hyperparameters that minimize it. However, the metric improvements on the validation set may not translate to the test set, especially on small datasets. In other words, BO can overfit. While cross-validation mitigates this, it comes with high computational cost. In this paper, we carry out the first systematic investigation of overfitting in BO and demonstrate that this is a serious yet often overlooked concern in practice. We propose the first problem-adaptive and interpretable criterion to early stop BO, reducing overfitting while mitigating the cost of cross-validation. Experimental results on real-world hyperparameter optimization tasks show that our approach can substantially reduce compute time with little to no loss of test accuracy,demonstrating a clear practical advantage over existing techniques.
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
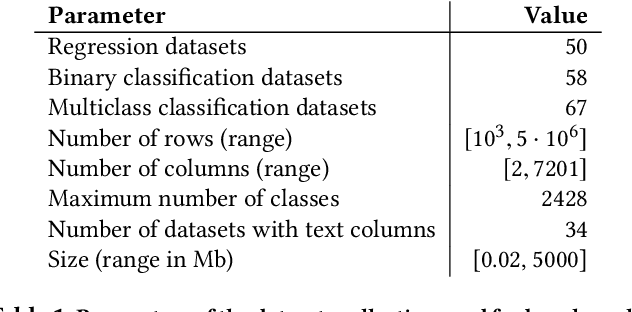
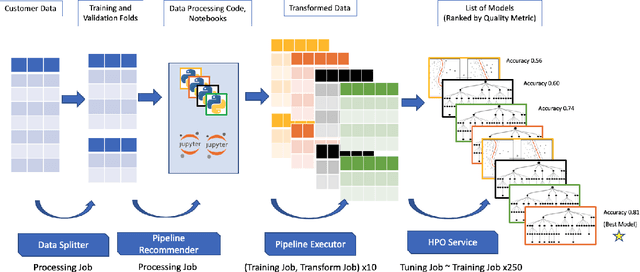
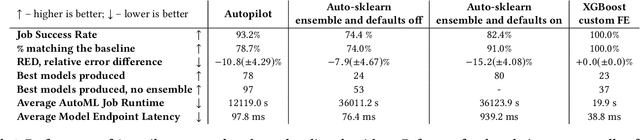
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.
Amazon SageMaker Automatic Model Tuning: Scalable Black-box Optimization
Dec 15, 2020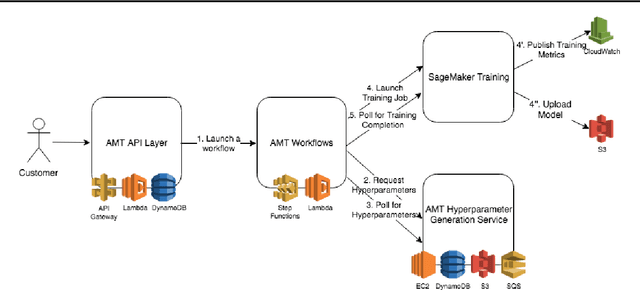
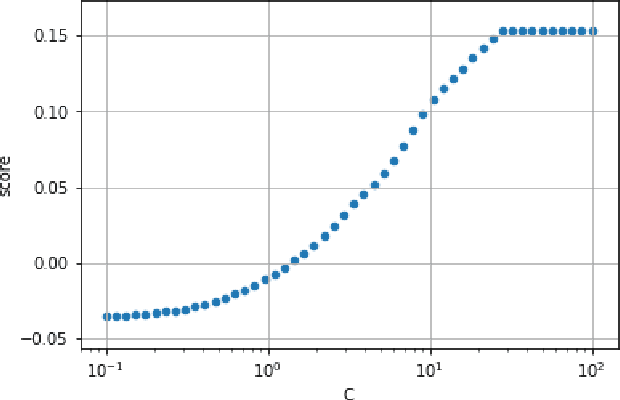
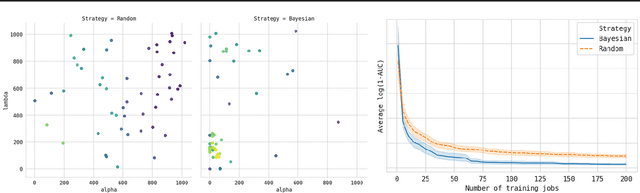
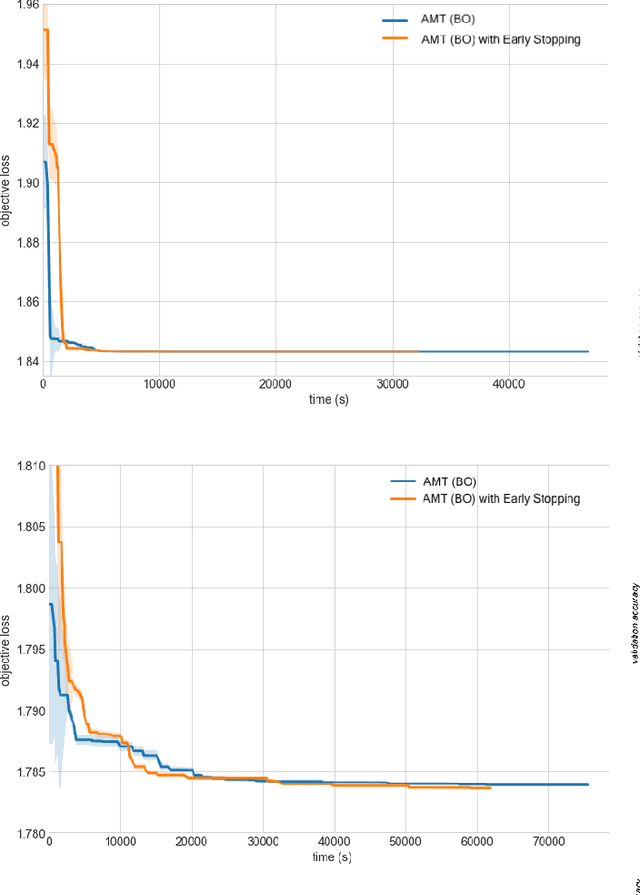
Tuning complex machine learning systems is challenging. Machine learning models typically expose a set of hyperparameters, be it regularization, architecture, or optimization parameters, whose careful tuning is critical to achieve good performance. To democratize access to such systems, it is essential to automate this tuning process. This paper presents Amazon SageMaker Automatic Model Tuning (AMT), a fully managed system for black-box optimization at scale. AMT finds the best version of a machine learning model by repeatedly training it with different hyperparameter configurations. It leverages either random search or Bayesian optimization to choose the hyperparameter values resulting in the best-performing model, as measured by the metric chosen by the user. AMT can be used with built-in algorithms, custom algorithms, and Amazon SageMaker pre-built containers for machine learning frameworks. We discuss the core functionality, system architecture and our design principles. We also describe some more advanced features provided by AMT, such as automated early stopping and warm-starting, demonstrating their benefits in experiments.
Chargrid: Towards Understanding 2D Documents
Sep 24, 2018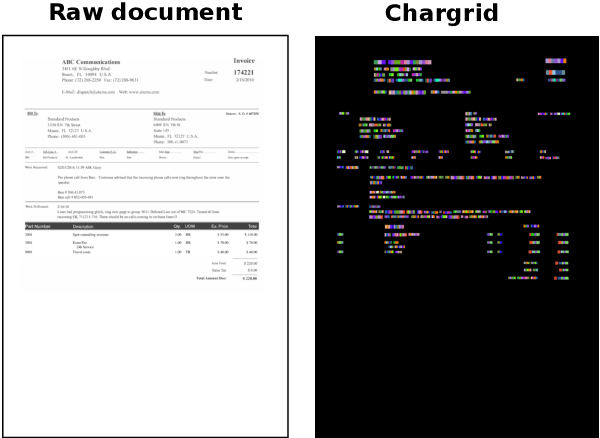

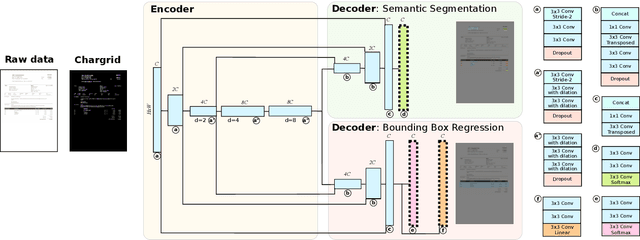
We introduce a novel type of text representation that preserves the 2D layout of a document. This is achieved by encoding each document page as a two-dimensional grid of characters. Based on this representation, we present a generic document understanding pipeline for structured documents. This pipeline makes use of a fully convolutional encoder-decoder network that predicts a segmentation mask and bounding boxes. We demonstrate its capabilities on an information extraction task from invoices and show that it significantly outperforms approaches based on sequential text or document images.