 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronosX: Adapting Pretrained Time Series Models with Exogenous Variables
Mar 15, 2025



Covariates provide valuable information on external factors that influence time series and are critical in many real-world time series forecasting tasks. For example, in retail, covariates may indicate promotions or peak dates such as holiday seasons that heavily influence demand forecasts. Recent advances in pretraining large language model architectures for time series forecasting have led to highly accurate forecasters. However, the majority of these models do not readily use covariates as they are often specific to a certain task or domain. This paper introduces a new method to incorporate covariates into pretrained time series forecasting models. Our proposed approach incorporates covariate information into pretrained forecasting models through modular blocks that inject past and future covariate information, without necessarily modifying the pretrained model in consideration. In order to evaluate our approach, we introduce a benchmark composed of 32 different synthetic datasets with varying dynamics to evaluate the effectivity of forecasting models with covariates. Extensive evaluations on both synthetic and real datasets show that our approach effectively incorporates covariate information into pretrained models, outperforming existing baselines.
Chronos: Learning the Language of Time Series
Mar 12, 2024We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based language model architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting
Aug 10, 2023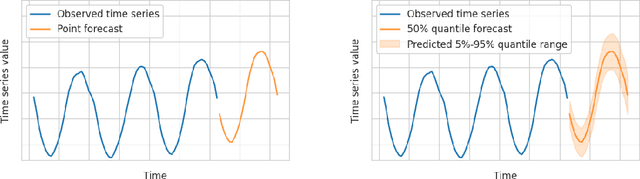
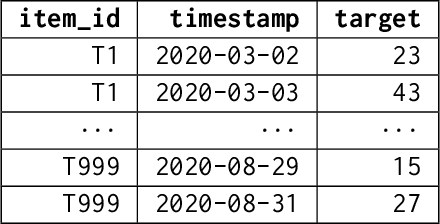
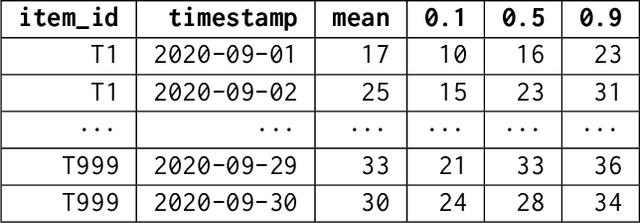
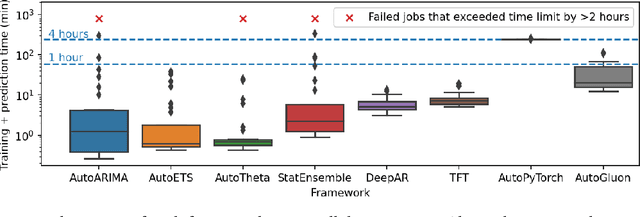
We introduce AutoGluon-TimeSeries - an open-source AutoML library for probabilistic time series forecasting. Focused on ease of use and robustness, AutoGluon-TimeSeries enables users to generate accurate point and quantile forecasts with just 3 lines of Python code. Built on the design philosophy of AutoGluon, AutoGluon-TimeSeries leverages ensembles of diverse forecasting models to deliver high accuracy within a short training time. AutoGluon-TimeSeries combines both conventional statistical models, machine-learning based forecasting approaches, and ensembling techniques. In our evaluation on 29 benchmark datasets, AutoGluon-TimeSeries demonstrates strong empirical performance, outperforming a range of forecasting methods in terms of both point and quantile forecast accuracy, and often even improving upon the best-in-hindsight combination of prior methods.
Obeying the Order: Introducing Ordered Transfer Hyperparameter Optimisation
Jun 29, 2023We introduce ordered transfer hyperparameter optimisation (OTHPO), a version of transfer learning for hyperparameter optimisation (HPO) where the tasks follow a sequential order. Unlike for state-of-the-art transfer HPO, the assumption is that each task is most correlated to those immediately before it. This matches many deployed settings, where hyperparameters are retuned as more data is collected; for instance tuning a sequence of movie recommendation systems as more movies and ratings are added. We propose a formal definition, outline the differences to related problems and propose a basic OTHPO method that outperforms state-of-the-art transfer HPO. We empirically show the importance of taking order into account using ten benchmarks. The benchmarks are in the setting of gradually accumulating data, and span XGBoost, random forest, approximate k-nearest neighbor, elastic net, support vector machines and a separate real-world motivated optimisation problem. We open source the benchmarks to foster future research on ordered transfer HPO.
Cross-Frequency Time Series Meta-Forecasting
Feb 04, 2023



Meta-forecasting is a newly emerging field which combines meta-learning and time series forecasting. The goal of meta-forecasting is to train over a collection of source time series and generalize to new time series one-at-a-time. Previous approaches in meta-forecasting achieve competitive performance, but with the restriction of training a separate model for each sampling frequency. In this work, we investigate meta-forecasting over different sampling frequencies, and introduce a new model, the Continuous Frequency Adapter (CFA), specifically designed to learn frequency-invariant representations. We find that CFA greatly improves performance when generalizing to unseen frequencies, providing a first step towards forecasting over larger multi-frequency datasets.
Overfitting in Bayesian Optimization: an empirical study and early-stopping solution
Apr 16, 2021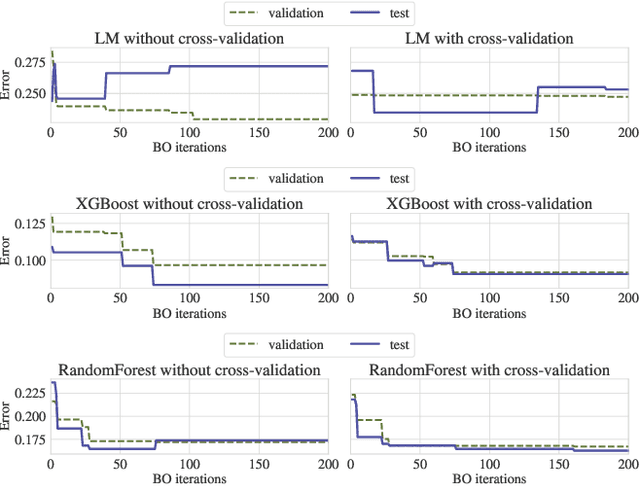
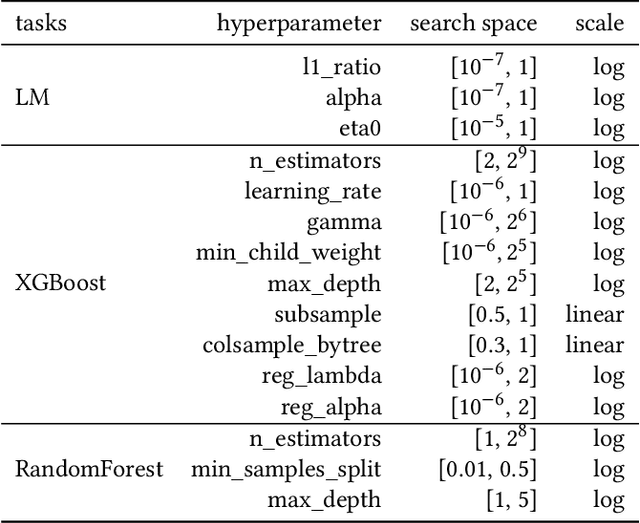
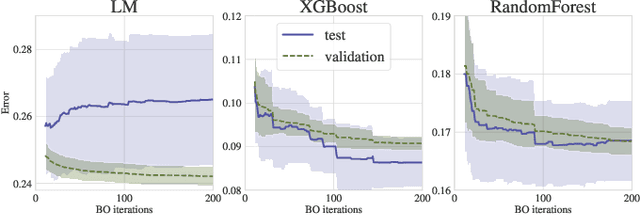
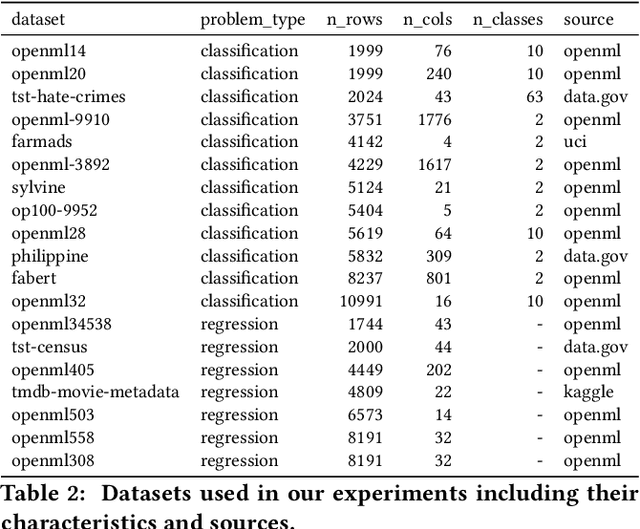
Bayesian Optimization (BO) is a successful methodology to tune the hyperparameters of machine learning algorithms. The user defines a metric of interest, such as the validation error, and BO finds the optimal hyperparameters that minimize it. However, the metric improvements on the validation set may not translate to the test set, especially on small datasets. In other words, BO can overfit. While cross-validation mitigates this, it comes with high computational cost. In this paper, we carry out the first systematic investigation of overfitting in BO and demonstrate that this is a serious yet often overlooked concern in practice. We propose the first problem-adaptive and interpretable criterion to early stop BO, reducing overfitting while mitigating the cost of cross-validation. Experimental results on real-world hyperparameter optimization tasks show that our approach can substantially reduce compute time with little to no loss of test accuracy,demonstrating a clear practical advantage over existing techniques.
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
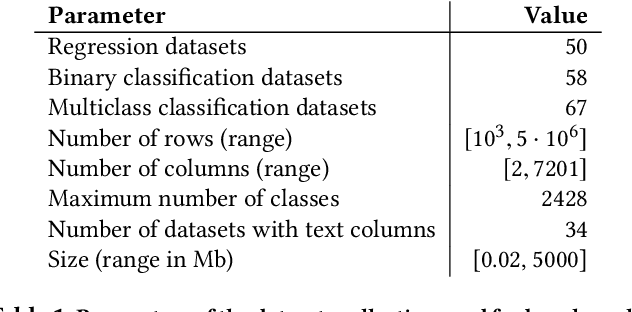
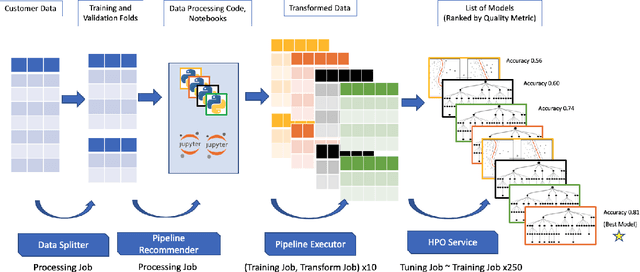
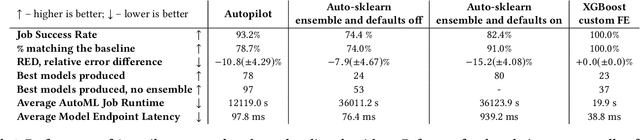
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.
Amazon SageMaker Automatic Model Tuning: Scalable Black-box Optimization
Dec 15, 2020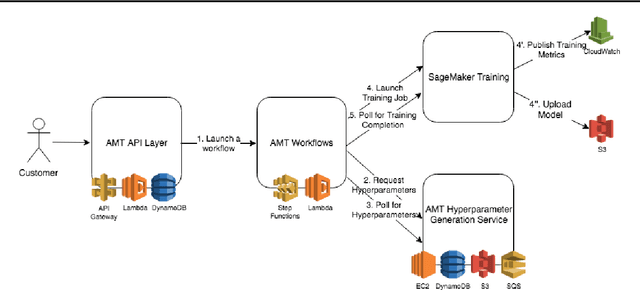
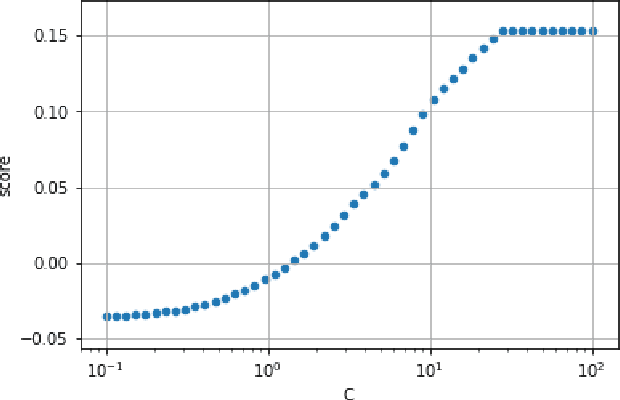
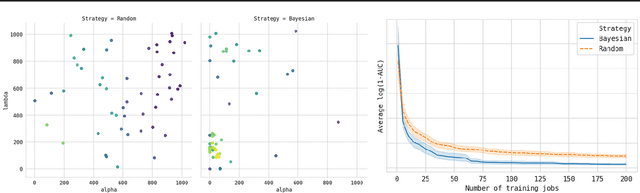
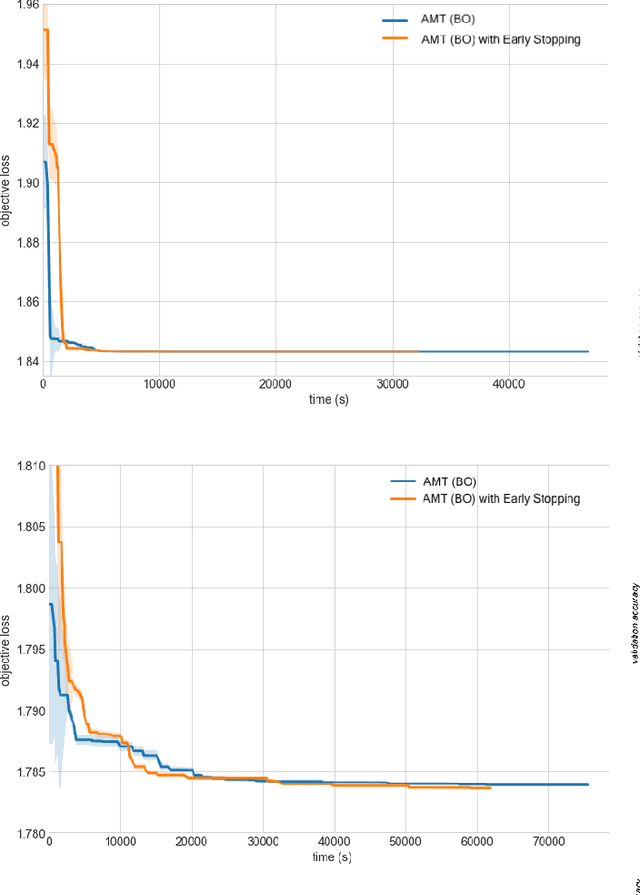
Tuning complex machine learning systems is challenging. Machine learning models typically expose a set of hyperparameters, be it regularization, architecture, or optimization parameters, whose careful tuning is critical to achieve good performance. To democratize access to such systems, it is essential to automate this tuning process. This paper presents Amazon SageMaker Automatic Model Tuning (AMT), a fully managed system for black-box optimization at scale. AMT finds the best version of a machine learning model by repeatedly training it with different hyperparameter configurations. It leverages either random search or Bayesian optimization to choose the hyperparameter values resulting in the best-performing model, as measured by the metric chosen by the user. AMT can be used with built-in algorithms, custom algorithms, and Amazon SageMaker pre-built containers for machine learning frameworks. We discuss the core functionality, system architecture and our design principles. We also describe some more advanced features provided by AMT, such as automated early stopping and warm-starting, demonstrating their benefits in experiments.
A Copula approach for hyperparameter transfer learning
Sep 30, 2019
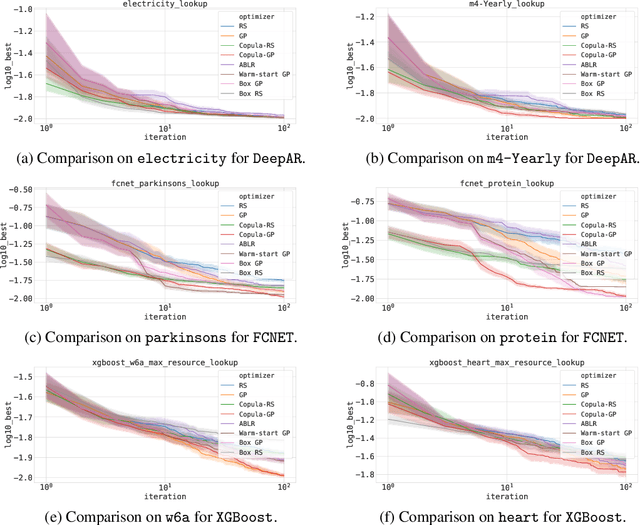
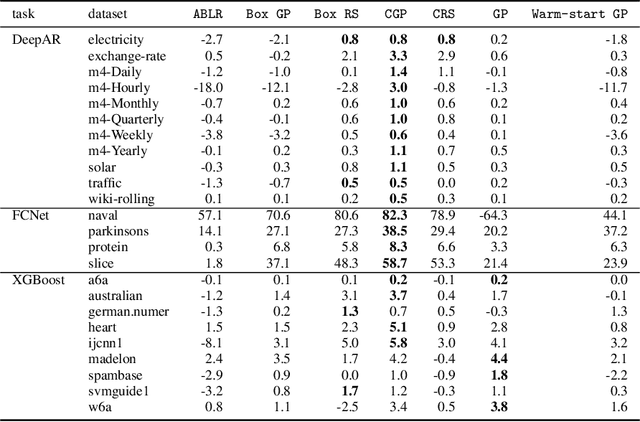
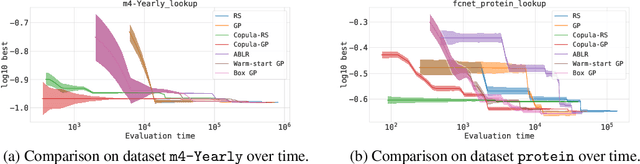
Bayesian optimization (BO) is a popular methodology to tune the hyperparameters of expensive black-box functions. Despite its success, standard BO focuses on a single task at a time and is not designed to leverage information from related functions, such as tuning performance metrics of the same algorithm across multiple datasets. In this work, we introduce a novel approach to achieve transfer learning across different datasets as well as different metrics. The main idea is to regress the mapping from hyperparameter to metric quantiles with a semi-parametric Gaussian Copula distribution, which provides robustness against different scales or outliers that can occur in different tasks. We introduce two methods to leverage this estimation: a Thompson sampling strategy as well as a Gaussian Copula process using such quantile estimate as a prior. We show that these strategies can combine the estimation of multiple metrics such as runtime and accuracy, steering the optimization toward cheaper hyperparameters for the same level of accuracy. Experiments on an extensive set of hyperparameter tuning tasks demonstrate significant improvements over state-of-the-art methods.
Learning search spaces for Bayesian optimization: Another view of hyperparameter transfer learning
Sep 27, 2019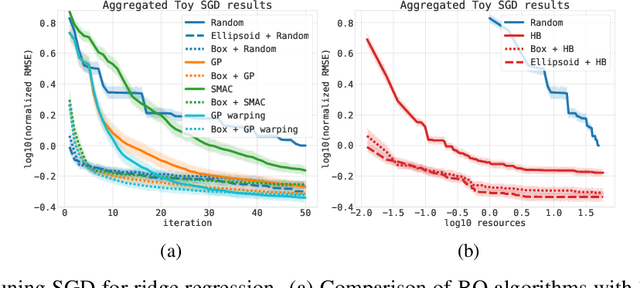
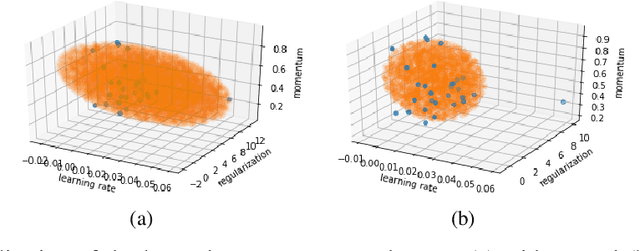

Bayesian optimization (BO) is a successful methodology to optimize black-box functions that are expensive to evaluate. While traditional methods optimize each black-box function in isolation, there has been recent interest in speeding up BO by transferring knowledge across multiple related black-box functions. In this work, we introduce a method to automatically design the BO search space by relying on evaluations of previous black-box functions. We depart from the common practice of defining a set of arbitrary search ranges a priori by considering search space geometries that are learned from historical data. This simple, yet effective strategy can be used to endow many existing BO methods with transfer learning properties. Despite its simplicity, we show that our approach considerably boosts BO by reducing the size of the search space, thus accelerating the optimization of a variety of black-box optimization problems. In particular, the proposed approach combined with random search results in a parameter-free, easy-to-implement, robust hyperparameter optimization strategy. We hope it will constitute a natural baseline for further research attempting to warm-start BO.