 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreDiff: Precipitation Nowcasting with Latent Diffusion Models
Jul 19, 2023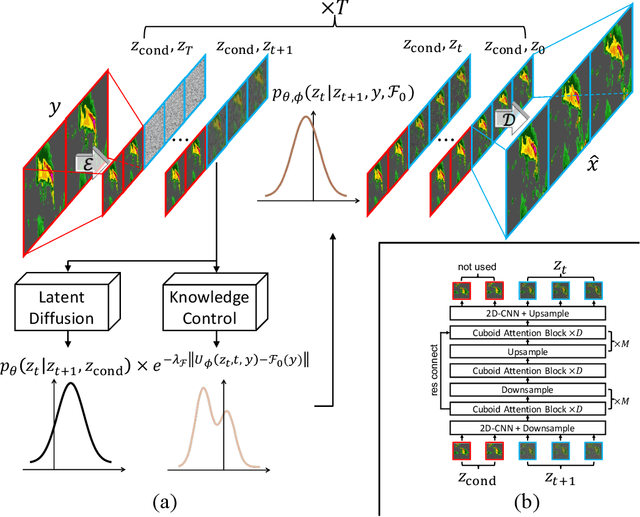
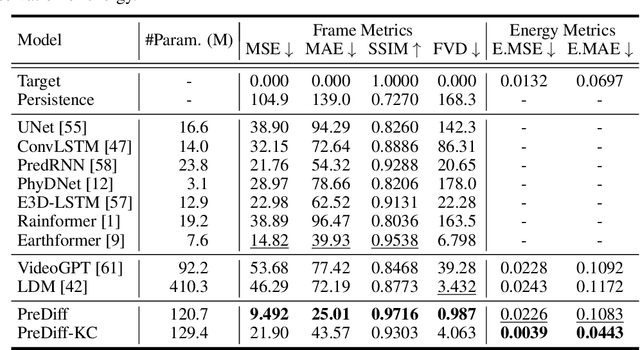

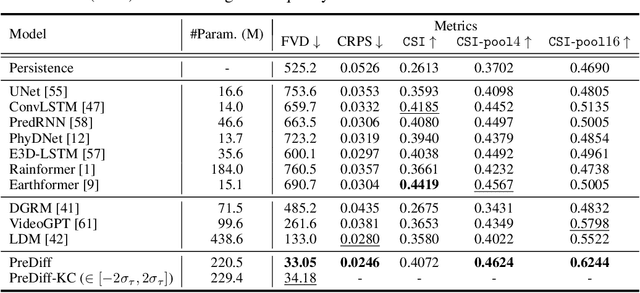
Earth system forecasting has traditionally relied on complex physical models that are computationally expensive and require significant domain expertise. In the past decade, the unprecedented increase in spatiotemporal Earth observation data has enabled data-driven forecasting models using deep learning techniques. These models have shown promise for diverse Earth system forecasting tasks but either struggle with handling uncertainty or neglect domain-specific prior knowledge, resulting in averaging possible futures to blurred forecasts or generating physically implausible predictions. To address these limitations, we propose a two-stage pipeline for probabilistic spatiotemporal forecasting: 1) We develop PreDiff, a conditional latent diffusion model capable of probabilistic forecasts. 2) We incorporate an explicit knowledge control mechanism to align forecasts with domain-specific physical constraints. This is achieved by estimating the deviation from imposed constraints at each denoising step and adjusting the transition distribution accordingly. We conduct empirical studies on two datasets: N-body MNIST, a synthetic dataset with chaotic behavior, and SEVIR, a real-world precipitation nowcasting dataset. Specifically, we impose the law of conservation of energy in N-body MNIST and anticipated precipitation intensity in SEVIR. Experiments demonstrate the effectiveness of PreDiff in handling uncertainty, incorporating domain-specific prior knowledge, and generating forecasts that exhibit high operational utility.
Cross-Frequency Time Series Meta-Forecasting
Feb 04, 2023



Meta-forecasting is a newly emerging field which combines meta-learning and time series forecasting. The goal of meta-forecasting is to train over a collection of source time series and generalize to new time series one-at-a-time. Previous approaches in meta-forecasting achieve competitive performance, but with the restriction of training a separate model for each sampling frequency. In this work, we investigate meta-forecasting over different sampling frequencies, and introduce a new model, the Continuous Frequency Adapter (CFA), specifically designed to learn frequency-invariant representations. We find that CFA greatly improves performance when generalizing to unseen frequencies, providing a first step towards forecasting over larger multi-frequency datasets.
First De-Trend then Attend: Rethinking Attention for Time-Series Forecasting
Dec 15, 2022



Transformer-based models have gained large popularity and demonstrated promising results in long-term time-series forecasting in recent years. In addition to learning attention in time domain, recent works also explore learning attention in frequency domains (e.g., Fourier domain, wavelet domain), given that seasonal patterns can be better captured in these domains. In this work, we seek to understand the relationships between attention models in different time and frequency domains. Theoretically, we show that attention models in different domains are equivalent under linear conditions (i.e., linear kernel to attention scores). Empirically, we analyze how attention models of different domains show different behaviors through various synthetic experiments with seasonality, trend and noise, with emphasis on the role of softmax operation therein. Both these theoretical and empirical analyses motivate us to propose a new method: TDformer (Trend Decomposition Transformer), that first applies seasonal-trend decomposition, and then additively combines an MLP which predicts the trend component with Fourier attention which predicts the seasonal component to obtain the final prediction. Extensive experiments on benchmark time-series forecasting datasets demonstrate that TDformer achieves state-of-the-art performance against existing attention-based models.
Attention-based Domain Adaptation for Time Series Forecasting
Feb 17, 2021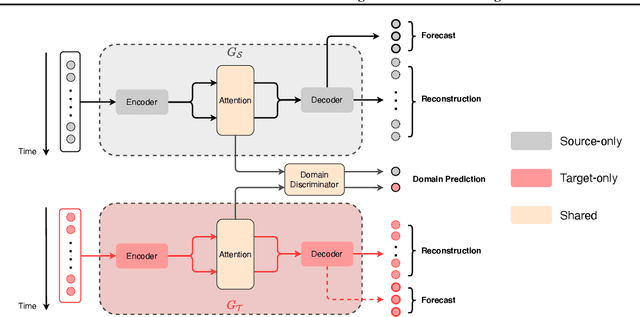
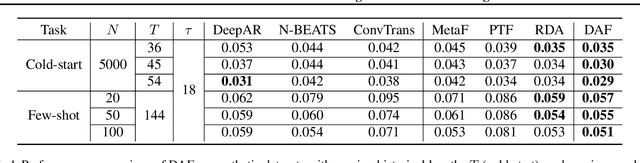

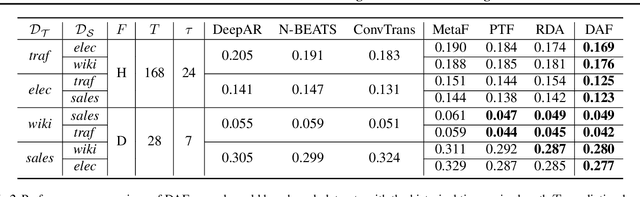
Recent years have witnessed deep neural networks gaining increasing popularity in the field of time series forecasting. A primary reason of their success is their ability to effectively capture complex temporal dynamics across multiple related time series. However, the advantages of these deep forecasters only start to emerge in the presence of a sufficient amount of data. This poses a challenge for typical forecasting problems in practice, where one either has a small number of time series, or limited observations per time series, or both. To cope with the issue of data scarcity, we propose a novel domain adaptation framework, Domain Adaptation Forecaster (DAF), that leverages the statistical strengths from another relevant domain with abundant data samples (source) to improve the performance on the domain of interest with limited data (target). In particular, we propose an attention-based shared module with a domain discriminator across domains as well as private modules for individual domains. This allows us to jointly train the source and target domains by generating domain-invariant latent features while retraining domain-specific features. Extensive experiments on various domains demonstrate that our proposed method outperforms state-of-the-art baselines on synthetic and real-world datasets.
Inter-Series Attention Model for COVID-19 Forecasting
Oct 25, 2020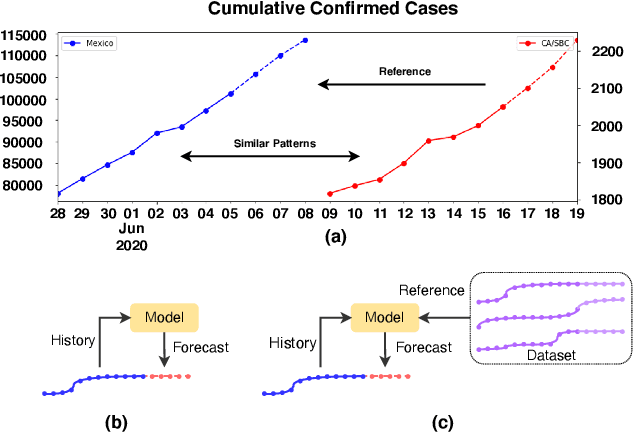

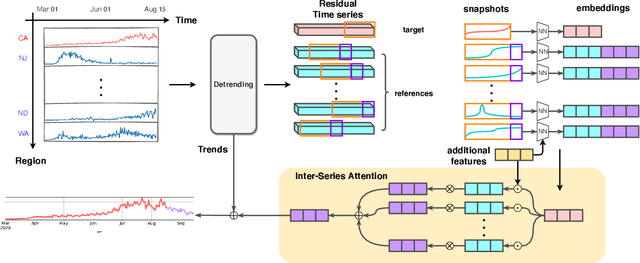
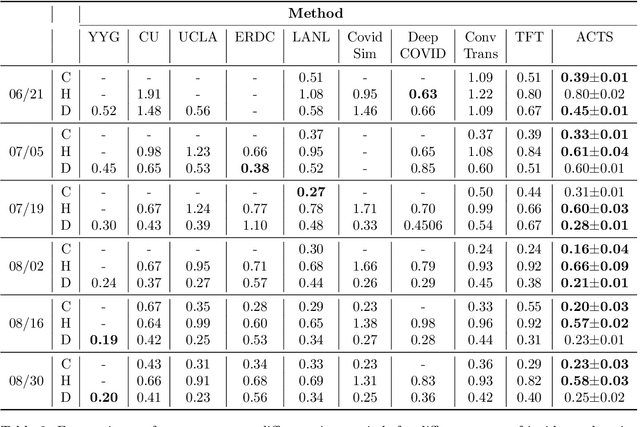
COVID-19 pandemic has an unprecedented impact all over the world since early 2020. During this public health crisis, reliable forecasting of the disease becomes critical for resource allocation and administrative planning. The results from compartmental models such as SIR and SEIR are popularly referred by CDC and news media. With more and more COVID-19 data becoming available, we examine the following question: Can a direct data-driven approach without modeling the disease spreading dynamics outperform the well referred compartmental models and their variants? In this paper, we show the possibility. It is observed that as COVID-19 spreads at different speed and scale in different geographic regions, it is highly likely that similar progression patterns are shared among these regions within different time periods. This intuition lead us to develop a new neural forecasting model, called Attention Crossing Time Series (\textbf{ACTS}), that makes forecasts via comparing patterns across time series obtained from multiple regions. The attention mechanism originally developed for natural language processing can be leveraged and generalized to materialize this idea. Among 13 out of 18 testings including forecasting newly confirmed cases, hospitalizations and deaths, \textbf{ACTS} outperforms all the leading COVID-19 forecasters highlighted by CDC.
HULK: An Energy Efficiency Benchmark Platform for Responsible Natural Language Processing
Feb 14, 2020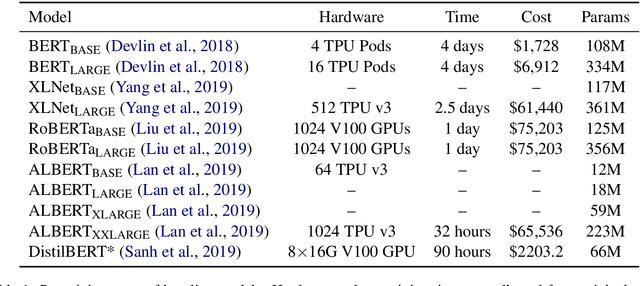

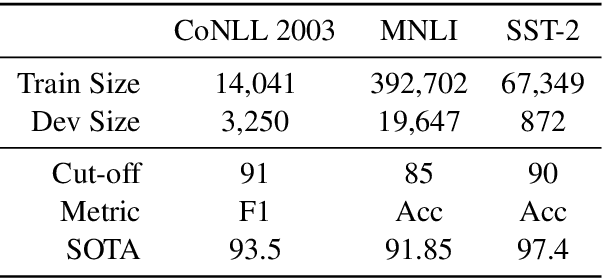
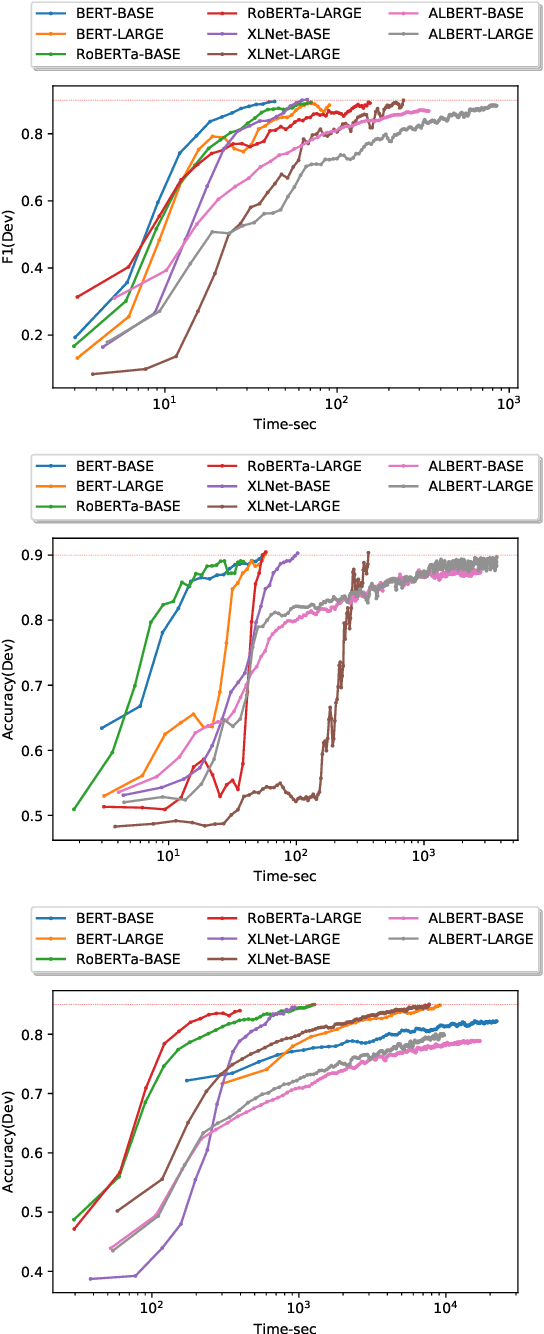
Computation-intensive pretrained models have been taking the lead of many natural language processing benchmarks such as GLUE. However, energy efficiency in the process of model training and inference becomes a critical bottleneck. We introduce HULK, a multi-task energy efficiency benchmarking platform for responsible natural language processing. With HULK, we compare pretrained models' energy efficiency from the perspectives of time and cost. Baseline benchmarking results are provided for further analysis. The fine-tuning efficiency of different pretrained models can differ a lot among different tasks and fewer parameter number does not necessarily imply better efficiency. We analyzed such phenomenon and demonstrate the method of comparing the multi-task efficiency of pretrained models. Our platform is available at https://sites.engineering.ucsb.edu/~xiyou/hulk/.
You May Not Need Order in Time Series Forecasting
Oct 21, 2019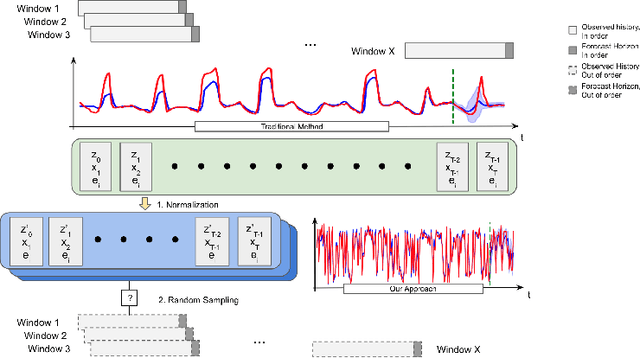
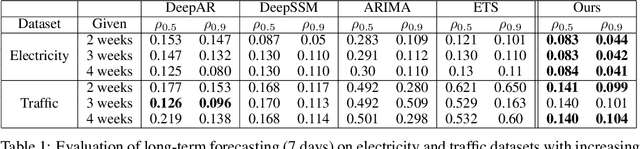
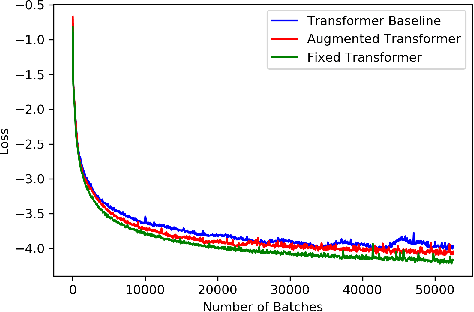
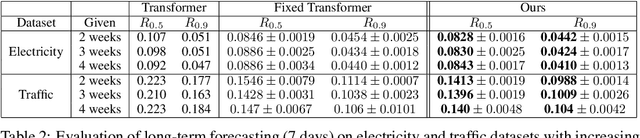
Time series forecasting with limited data is a challenging yet critical task. While transformers have achieved outstanding performances in time series forecasting, they often require many training samples due to the large number of trainable parameters. In this paper, we propose a training technique for transformers that prepares the training windows through random sampling. As input time steps need not be consecutive, the number of distinct samples increases from linearly to combinatorially many. By breaking the temporal order, this technique also helps transformers to capture dependencies among time steps in finer granularity. We achieve competitive results compared to the state-of-the-art on real-world datasets.
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Jun 29, 2019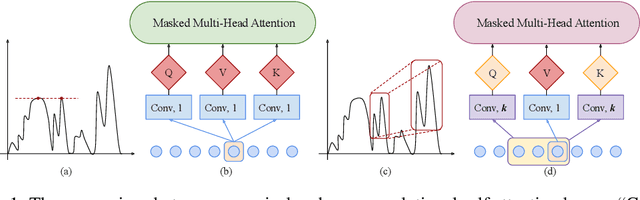
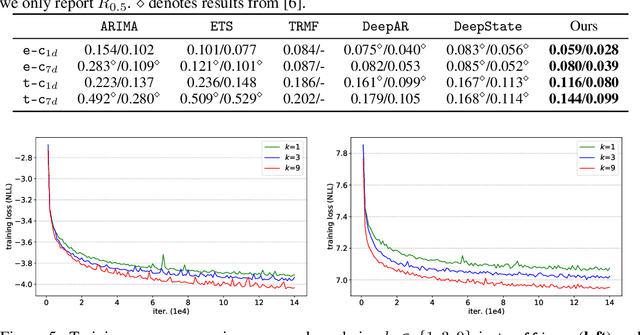
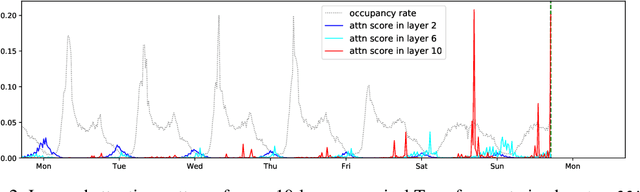

Time series forecasting is an important problem across many domains, including predictions of solar plant energy output, electricity consumption, and traffic jam situation. In this paper, we propose to tackle such forecasting problem with Transformer. Although impressed by its performance in our preliminary study, we found its two major weaknesses: (1) locality-agnostics: the point-wise dot-product self attention in canonical Transformer architecture is insensitive to local context, which can make the model prone to anomalies in time series; (2) memory bottleneck: space complexity of canonical Transformer grows quadratically with sequence length $L$, making modeling long time series infeasible. In order to solve these two issues, we first propose convolutional self attention by producing queries and keys with causal convolution so that local context can be better incorporated into attention mechanism. Then, we propose LogSparse Transformer with only $O(L(\log L)^{2})$ memory cost, improving the time series forecasting in finer granularity under constrained memory budget. Our experiments on both synthetic data and real-world datasets show that it compares favorably to the state-of-the-art.