 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Track Transformers: Enabling Fast GPU Inference with Reduced Synchronization
Feb 07, 2026Efficient large-scale inference of transformer-based large language models (LLMs) remains a fundamental systems challenge, frequently requiring multi-GPU parallelism to meet stringent latency and throughput targets. Conventional tensor parallelism decomposes matrix operations across devices but introduces substantial inter-GPU synchronization, leading to communication bottlenecks and degraded scalability. We propose the Parallel Track (PT) Transformer, a novel architectural paradigm that restructures computation to minimize cross-device dependencies. PT achieves up to a 16x reduction in synchronization operations relative to standard tensor parallelism, while maintaining competitive model quality in our experiments. We integrate PT into two widely adopted LLM serving stacks-Tensor-RT-LLM and vLLM-and report consistent improvements in serving efficiency, including up to 15-30% reduced time to first token, 2-12% reduced time per output token, and up to 31.90% increased throughput in both settings.
Tensor Program Optimization with Probabilistic Programs
May 26, 2022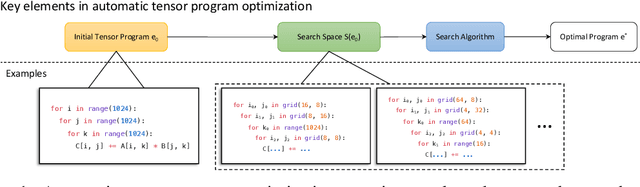

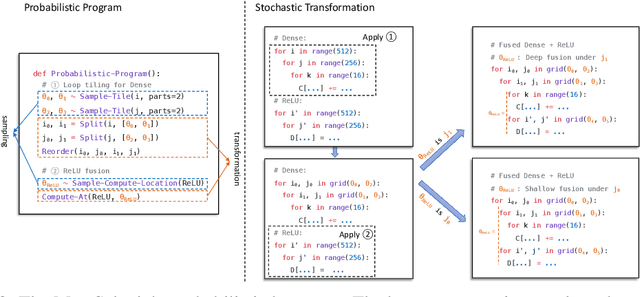
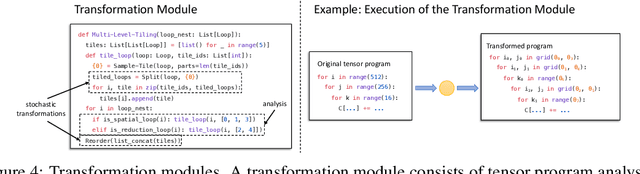
Automatic optimization for tensor programs becomes increasingly important as we deploy deep learning in various environments, and efficient optimization relies on a rich search space and effective search. Most existing efforts adopt a search space which lacks the ability to efficiently enable domain experts to grow the search space. This paper introduces MetaSchedule, a domain-specific probabilistic programming language abstraction to construct a rich search space of tensor programs. Our abstraction allows domain experts to analyze the program, and easily propose stochastic choices in a modular way to compose program transformation accordingly. We also build an end-to-end learning-driven framework to find an optimized program for a given search space. Experimental results show that MetaSchedule can cover the search space used in the state-of-the-art tensor program optimization frameworks in a modular way. Additionally, it empowers domain experts to conveniently grow the search space and modularly enhance the system, which brings 48% speedup on end-to-end deep learning workloads.
Logic2Text: High-Fidelity Natural Language Generation from Logical Forms
Apr 30, 2020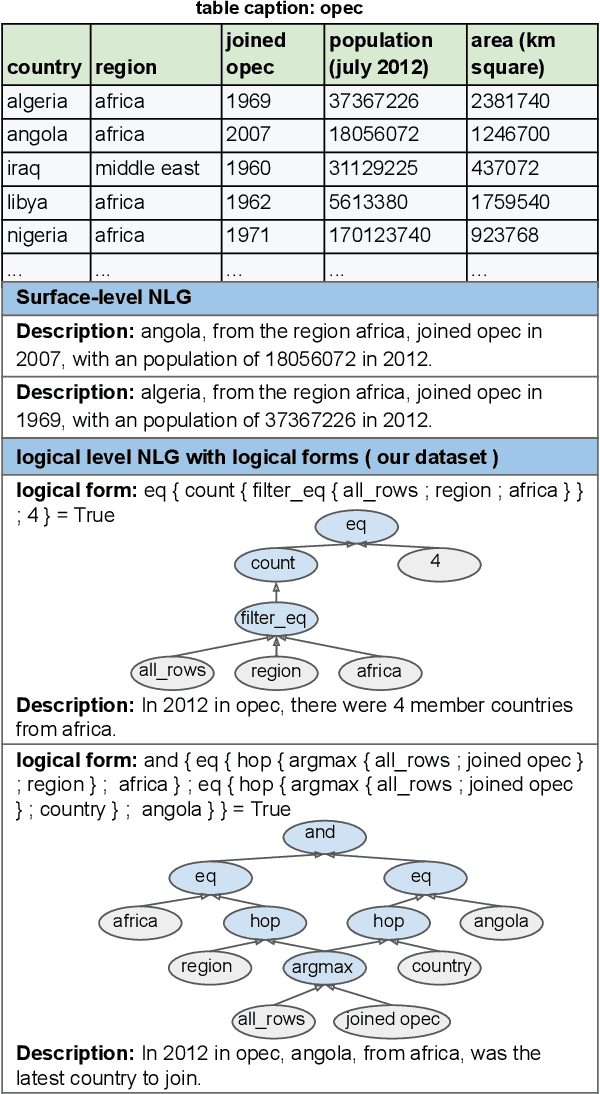

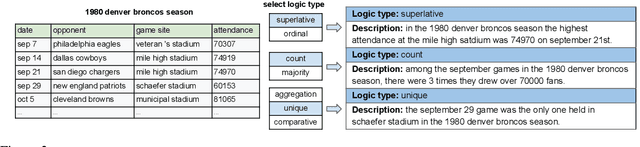

Previous works on Natural Language Generation (NLG) from structured data have primarily focused on surface-level descriptions of record sequences. However, for complex structured data, e.g., multi-row tables, it is often desirable for an NLG system to describe interesting facts from logical inferences across records. If only provided with the table, it is hard for existing models to produce controllable and high-fidelity logical generations. In this work, we formulate logical level NLG as generation from logical forms in order to obtain controllable, high-fidelity, and faithful generations. We present a new large-scale dataset, \textsc{Logic2Text}, with 10,753 descriptions involving common logic types paired with the underlying logical forms. The logical forms show diversified graph structure of free schema, which poses great challenges on the model's ability to understand the semantics. We experiment on (1) Fully-supervised training with the full datasets, and (2) Few-shot setting, provided with hundreds of paired examples; We compare several popular generation models and analyze their performances. We hope our dataset can encourage research towards building an advanced NLG system capable of natural, faithful, and human-like generation. The dataset and code are available at \url{https://github.com/czyssrs/Logic2Text}.
HULK: An Energy Efficiency Benchmark Platform for Responsible Natural Language Processing
Feb 14, 2020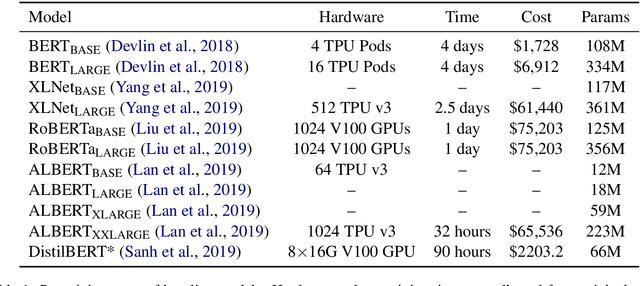

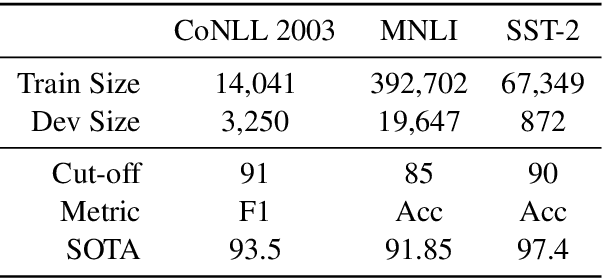
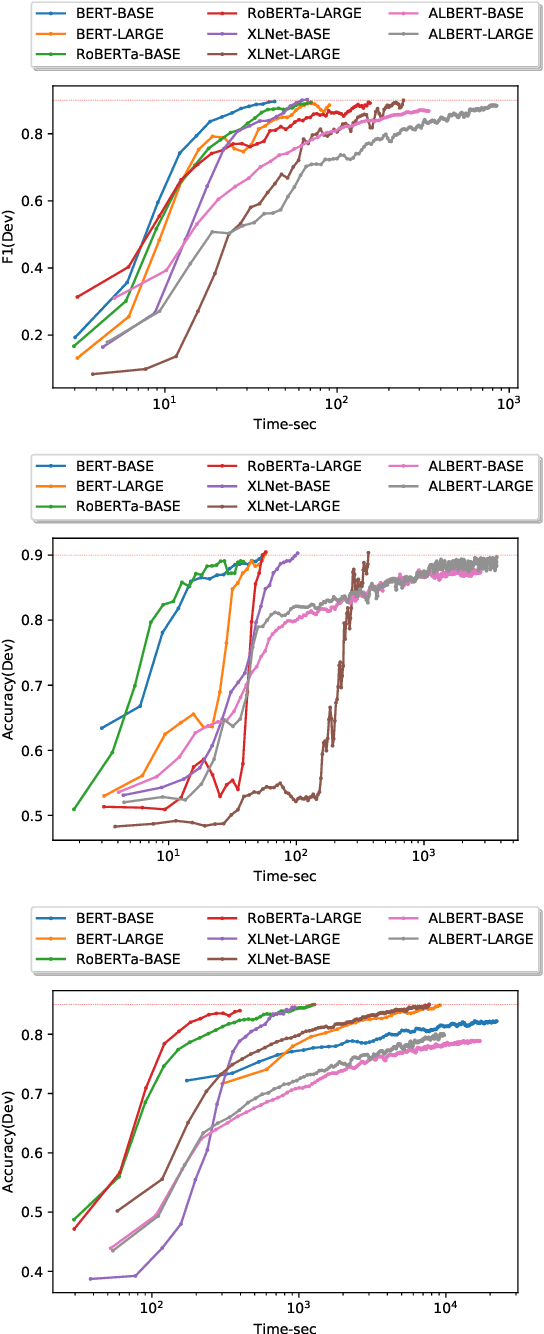
Computation-intensive pretrained models have been taking the lead of many natural language processing benchmarks such as GLUE. However, energy efficiency in the process of model training and inference becomes a critical bottleneck. We introduce HULK, a multi-task energy efficiency benchmarking platform for responsible natural language processing. With HULK, we compare pretrained models' energy efficiency from the perspectives of time and cost. Baseline benchmarking results are provided for further analysis. The fine-tuning efficiency of different pretrained models can differ a lot among different tasks and fewer parameter number does not necessarily imply better efficiency. We analyzed such phenomenon and demonstrate the method of comparing the multi-task efficiency of pretrained models. Our platform is available at https://sites.engineering.ucsb.edu/~xiyou/hulk/.
TabFact: A Large-scale Dataset for Table-based Fact Verification
Oct 08, 2019



The problem of verifying whether a textual hypothesis holds based on the given evidence, also known as fact verification, plays an important role in the study of natural language understanding and semantic representation. However, existing studies are mainly restricted to dealing with unstructured evidence (e.g., natural language sentences and documents, news, etc), while verification under structured evidence, such as tables, graphs, and databases, remains unexplored. This paper specifically aims to study the fact verification given semi-structured data as evidence. To this end, we construct a large-scale dataset called TabFact with 16k Wikipedia tables as the evidence for 118k human-annotated natural language statements, which are labeled as either ENTAILED or REFUTED. TabFact is challenging since it involves both soft linguistic reasoning and hard symbolic reasoning. To address these reasoning challenges, we design two different models: Table-BERT and Latent Program Algorithm (LPA). Table-BERT leverages the state-of-the-art pre-trained language model to encode the linearized tables and statements into continuous vectors for verification. LPA parses statements into LISP-like programs and executes them against the tables to obtain the returned binary value for verification. Both methods achieve similar accuracy but still lag far behind human performance. We also perform a comprehensive analysis to demonstrate great future opportunities. The data and code of the dataset are provided in \url{https://github.com/wenhuchen/Table-Fact-Checking}.
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Jun 29, 2019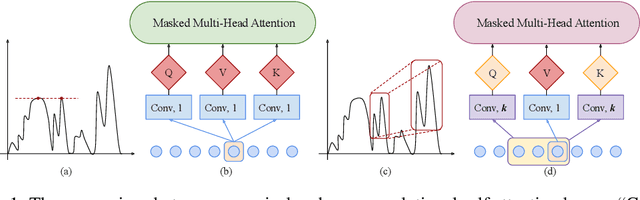
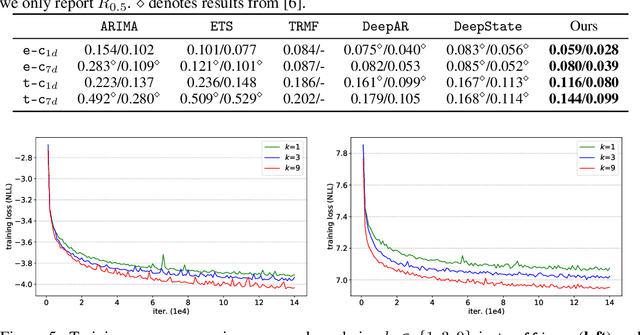
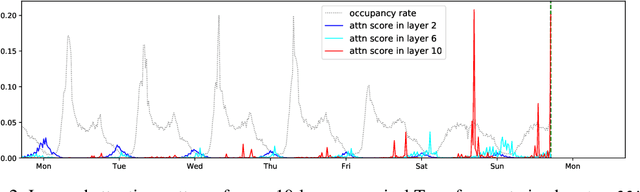

Time series forecasting is an important problem across many domains, including predictions of solar plant energy output, electricity consumption, and traffic jam situation. In this paper, we propose to tackle such forecasting problem with Transformer. Although impressed by its performance in our preliminary study, we found its two major weaknesses: (1) locality-agnostics: the point-wise dot-product self attention in canonical Transformer architecture is insensitive to local context, which can make the model prone to anomalies in time series; (2) memory bottleneck: space complexity of canonical Transformer grows quadratically with sequence length $L$, making modeling long time series infeasible. In order to solve these two issues, we first propose convolutional self attention by producing queries and keys with causal convolution so that local context can be better incorporated into attention mechanism. Then, we propose LogSparse Transformer with only $O(L(\log L)^{2})$ memory cost, improving the time series forecasting in finer granularity under constrained memory budget. Our experiments on both synthetic data and real-world datasets show that it compares favorably to the state-of-the-art.
Verb Pattern: A Probabilistic Semantic Representation on Verbs
Oct 20, 2017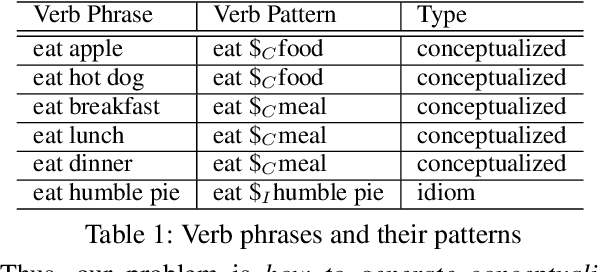
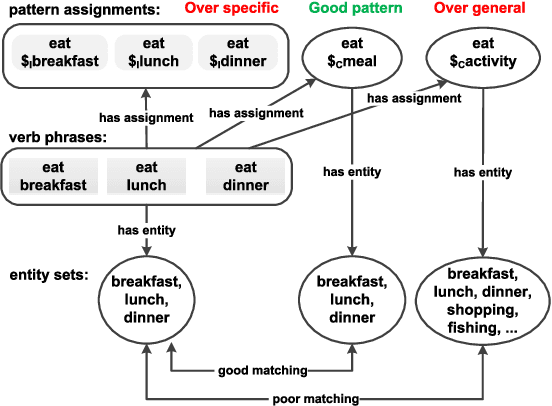
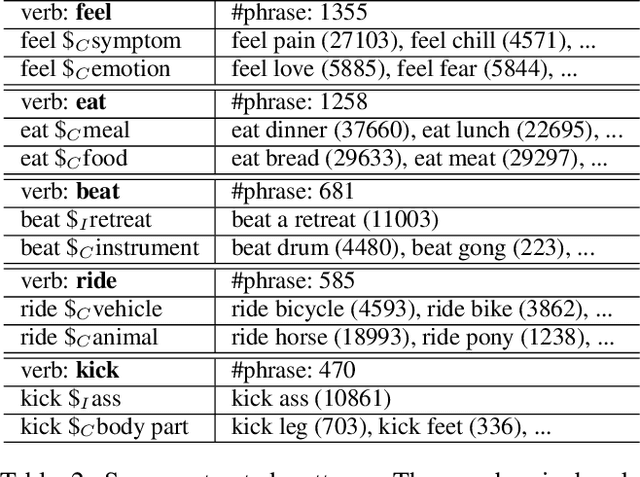
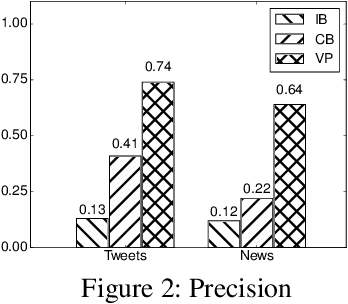
Verbs are important in semantic understanding of natural language. Traditional verb representations, such as FrameNet, PropBank, VerbNet, focus on verbs' roles. These roles are too coarse to represent verbs' semantics. In this paper, we introduce verb patterns to represent verbs' semantics, such that each pattern corresponds to a single semantic of the verb. First we analyze the principles for verb patterns: generality and specificity. Then we propose a nonparametric model based on description length. Experimental results prove the high effectiveness of verb patterns. We further apply verb patterns to context-aware conceptualization, to show that verb patterns are helpful in semantic-related tasks.